关键词 "文本转语音" 的搜索结果, 共 20 条, 只显示前 480 条
1分钟语音数据也可以用来训练一个好的TTS模型!(少量声音克隆).零样本 TTS:输入 5 秒的声音样本并体验即时文本到语音的转换。 Github上超过4万个星星
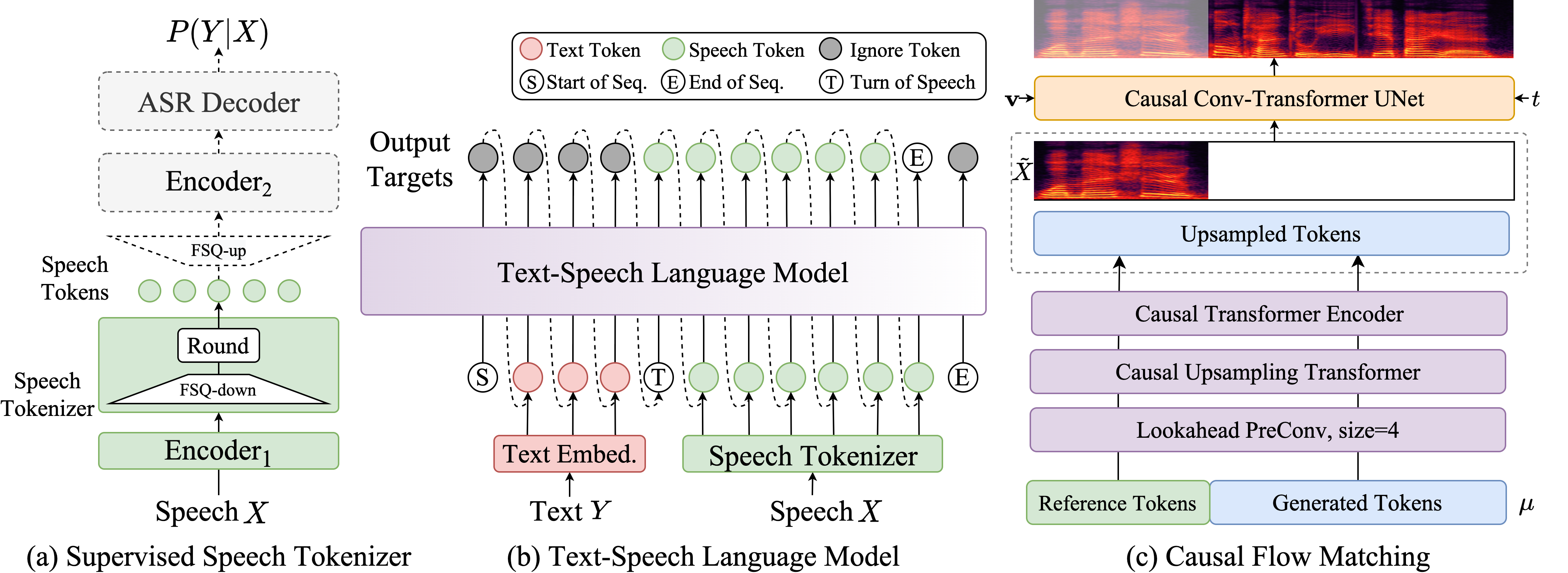
FunAudioLLM/CosyVoice(https://github.com/FunAudioLLM/CosyVoice) 项目是一个开源的多语言语音生成模型,它支持推理、训练和部署全流程。 该模型包括 CosyVoice-300M、CosyVoice-300M-SFT 和 CosyVoice-300M-Instruct 三种预训练模型,以及 CosyVoice-ttsfrd 资源。用户
一款开源的实时AI语音聊天助手:RealtimeVoiceChat,语音听起来相对自然,支持打断 双向语音交互,延迟低,可以实时看到语音转录,以及AI的回复内容 用来构建客服、教育或陪伴等等场景的AI语音助手比较实用 为低延迟交互而构建的复杂客户端-服务器系统: 🎙️捕获:您的声音被您的浏览器捕获。 ➡️流:音频块通过 WebSockets 传输到 Python 后端。 ✍️转
<p>Overview Spark-TTS 是由出门问问(Mobvoi)联合多所顶尖学术机构(如香港科技大学、上海交通大学)最新推出的新一代语音合成模型,其核心创新在于BiCodec编码技术和与文本大模型的结构统一性,利用大型语言模型 (LLM) 的强大功能实现高度准确且自然的语音合成。</p> <p>Spark-TTS is an advanced text
Muyan-TTS,一款低成本、具备良好二次开发支持的模型并完全开源,以方便学术界和小型应用团队的音频技术爱好者。 当前开源的Muyan-TTS版本由于训练数据规模有限,致使其仅对英语语种呈现出良好的支持效果。不过,得益于与之同步开源的详尽训练方法,从事相关行业的开发者能够依据自身实际业务场景,灵活地对Muyan-TTS进行功能升级与定制化改造。 01. H
类似 Manus 但基于 Deepseek R1 Agents 的本地模型。 Manus AI 的本地替代品,它是一个具有语音功能的大语言模型秘书,可以 Coding、访问你的电脑文件、浏览网页,并自动修正错误与反省,最重要的是不会向云端传送任何资料。采用 DeepSeek R1 等推理模型构建,完全在本地硬体上运行,进而保证资料的隐私。 Features: 100% 本机运行:
BookFab AudioBook Creator is an AI text-to-speech tool designed for producing high-quality audiobooks, podcasts and read-aloud content. It supports importing TXT or EPUB files and converting them to a
JoyPix 是专注于数字人和语音合成的AI创作工具。用户可以通过上传照片创建个性化的虚拟形象,支持与虚拟形象进行语音对话。JoyPix 提供自定义虚拟形象,可以根据自己的需求进一步定制虚拟形象的外观。JoyPix支持声音克隆,用户只需上传10秒音频片段,可克隆自己的声音,生成自然流畅的语音输出。JoyPix 的文本转语音功能可以将文本转换为逼真的语音,满足多种语音合成需求。JoyPix提供了虚拟
Unmute 是 Kyutai 推出的低延迟语音交互系统,专注于低延迟语音转文字(Speech-to-Text)和文字转语音(Text-to-Speech)。Unmute 基于先进的 AI 模型,为用户提供实时、高效的语音交互体验。用户基于语音与 AI 进行交流,支持将文字内容快速转换为自然流畅的语音输出。Unmute 的低延迟处理能力,能实现无缝的语音交互。 Unmute的主要功能
OpenAudio S1是Fish Audio推出的文本转语音(TTS)模型,基于超过200万小时的音频数据训练,支持13种语言。采用双自回归(Dual-AR)架构和强化学习与人类反馈(RLHF)技术,生成的声音高度自然、流畅,几乎与人类配音无异。模型支持超过50种情感和语调标记,用户可通过自然语言指令灵活调整语音表达。OpenAudio S1支持零样本和少样本语音克隆,仅需10到30秒的音频样本
LilyFM是创新的AI应用,能将网页文章转化为播客。应用基于先进的AI技术,将用户待读的文章内容转化为生动的音频,提供深度分析和提炼关键要点,帮助用户更高效地获取知识。LilyFM逼真的AI语音支持多种语言,提供自然、富有表现力的朗读体验。用户基于Share Extension一键保存文章到播放队列,随时随地在通勤、健身或休息时收听。LilyFM让稍后阅读转变为稍后收听,让知识获取更加便捷和轻松
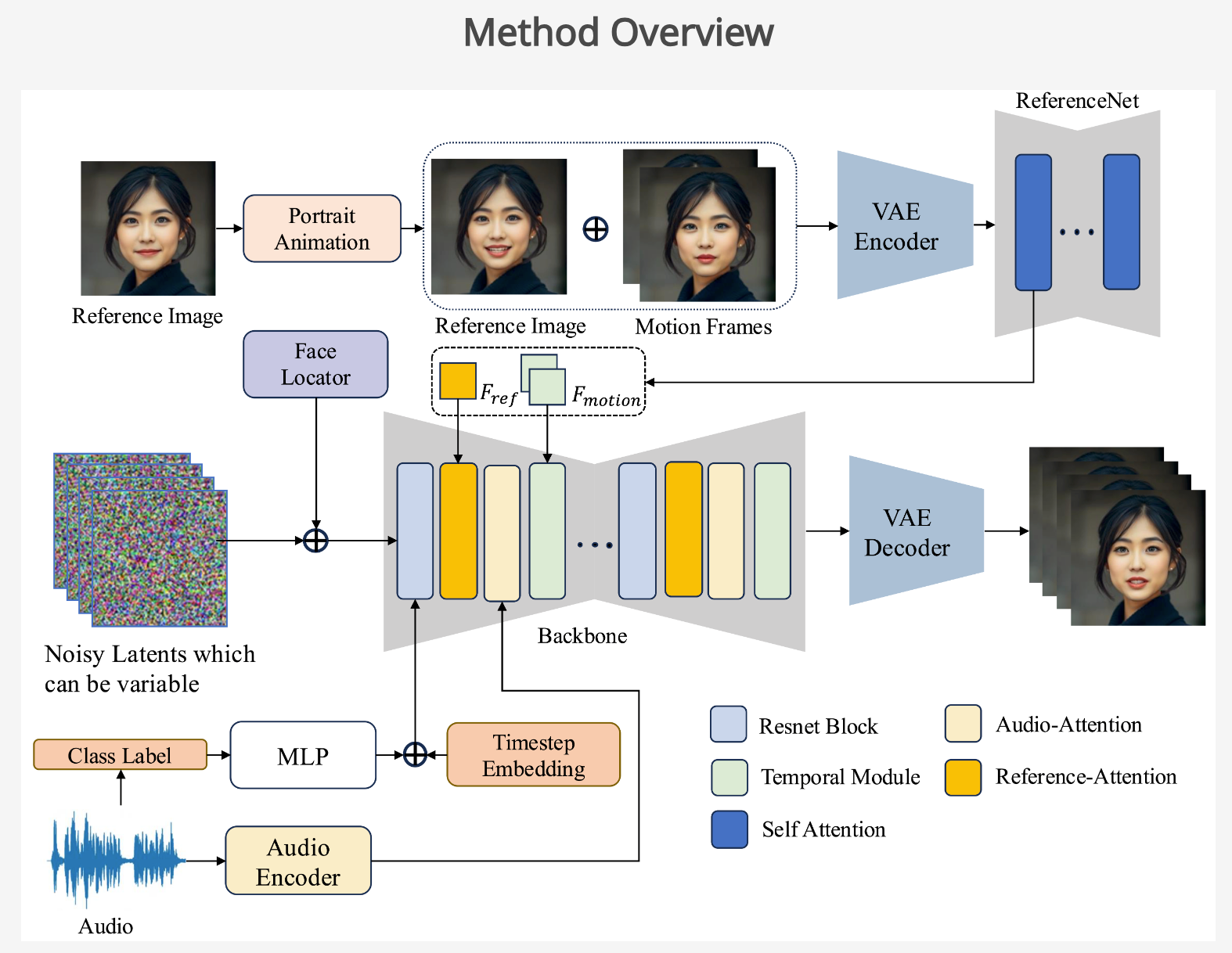
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
智声云配(DubbingX) 是 AI 智能配音工具,提供语音合成(TTS)、音色迁移、歌声转换等多种功能。工具支持中文、英文、日文、粤语等多语言,拥有近2500种情绪语态,支持高度定制,满足游戏、影视、动漫、有声书等多场景需求。工具音色版权合规,支持商用,能显著降低配音成本。智声云配结合专业高校和全球配音演员资源,致力于为用户提供高质量、多样化的音频解决方案。 智声云配官网:https://d
ThinkSound是阿里通义语音团队推出的首个CoT(链式思考)音频生成模型,用在视频配音,为每一帧画面生成专属匹配音效。模型引入CoT推理,解决传统技术难以捕捉画面动态细节和空间关系的问题,让AI像专业音效师一样逐步思考,生成音画同步的高保真音频。模型基于三阶思维链驱动音频生成,包括基础音效推理、对象级交互和指令编辑。模型配备AudioCoT数据集,包含带思维链标注的音频数据。在VGGSoun
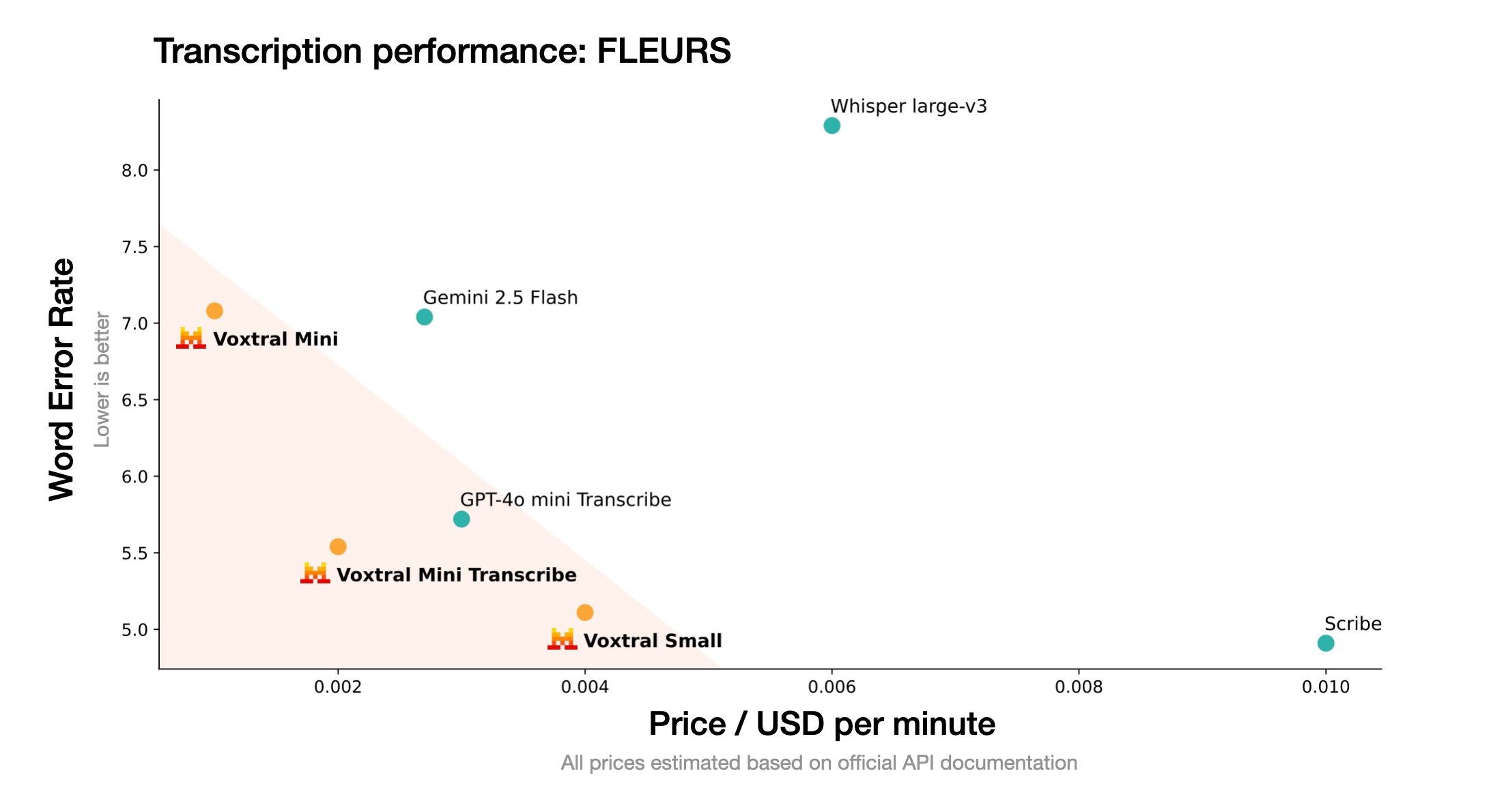
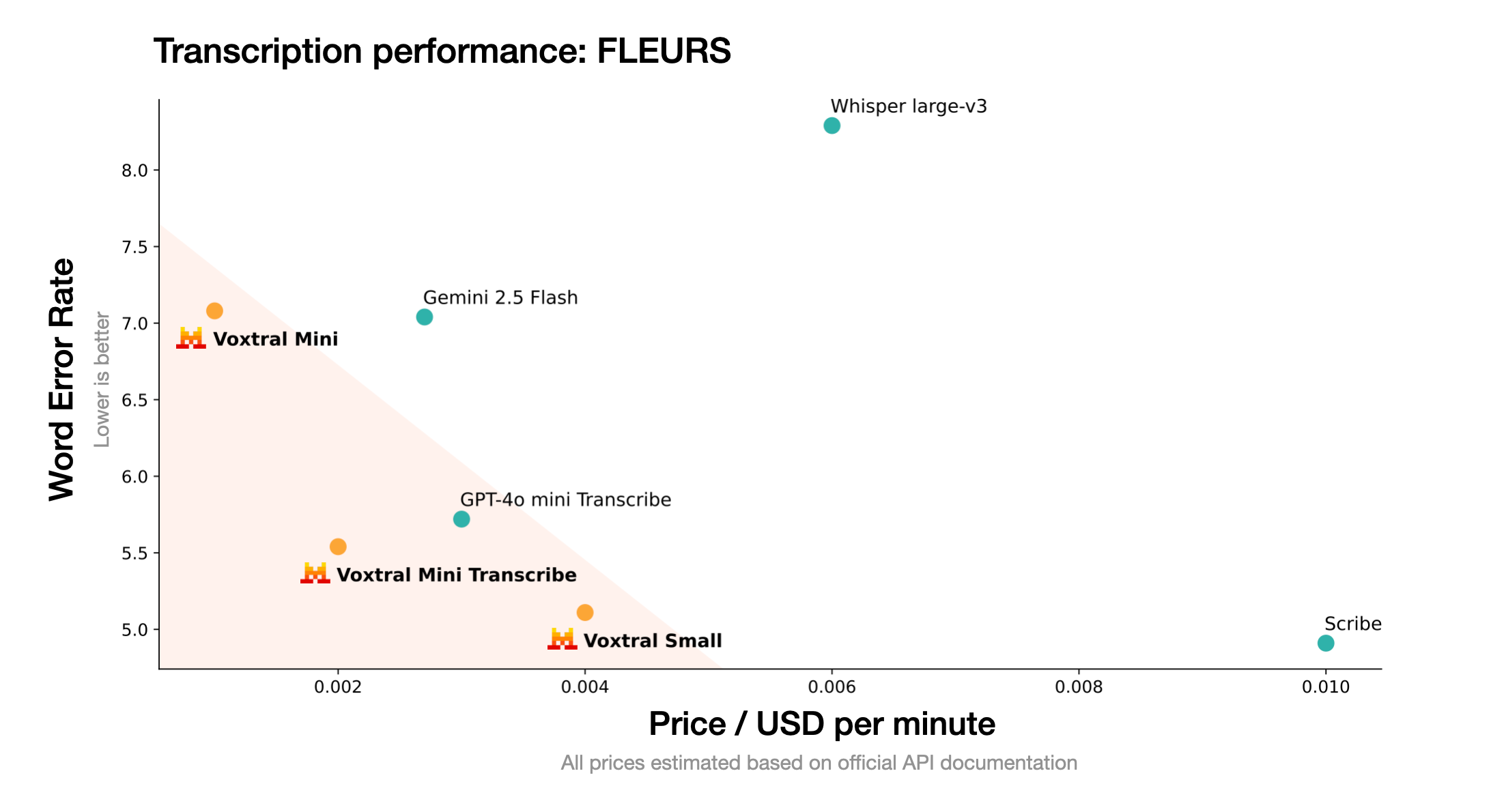
Voxtral 是 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。Voxtral提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音
Mistral AI,最新发布了首个开源语音模型:Voxtral语音理解模型系列! 该模型包含24B和3B两个参数规模的版本,均基于Apache 2.0许可证开源,同时提供API服务接口。 Voxtral模型支持32k token的上下文窗口,能够处理长达30分钟的音频转录任务或40分钟的语义理解任务,在各项基准测试指标上全面超越目前主流的开源语音转录模型Whisper large-v3。
FlowSpeech 是创新的 AI 文本转语音(TTS)工具,专注于将书面语转换为自然流畅的口语。通过上下文感知和多模态技术,解决了传统 TTS 在语调变化和情感表达上的不足,让 AI 生成的语音听起来更生动、自然。FlowSpeech 具备智能内容筛选功能,能自动识别并剪裁不适合朗读的内容,如广告信息和无意义字符串,显著提升语音输出质量。 如何使用FlowSpeech 网页端使用
AudioGenie是腾讯AI Lab团队推出的多模态音频生成工具,能从视频、文本、图像等多种模态输入生成音效、语音、音乐等多种音频输出。工具采用无训练的多智能体框架,通过生成团队和监督团队的双层架构实现高效协同。生成团队负责将复杂的输入分解为具体的音频子事件,通过自适应混合专家(MoE)协作机制动态选择最适合的模型进行生成。监督团队则负责时空一致性验证,通过反馈循环进行自我纠错,确保生成的音频高
Castwise 是为播客创作者设计的AI内容转化工具。工具能将播客音频快速转化为多种格式的内容,如节目笔记、公众号文章、小红书笔记、社交媒体帖子、字幕、思维导图等,极大地提高内容分发的效率。用户只需上传音频文件或提供链接,系统能高效处理、生成多种素材,支持多语言。Castwise 的目标是将播客转化为强大的营销引擎,帮助创作者实现“一次录制,多平台发布”,提升内容的传播范围和影响力。Castwi
Fish Speech 是一款由 Fish Audio 开源的文本转语音(TTS)工具,支持中、英、日三国语言。它经过 15 万小时的多语种数据训练,能生成接近人类水平的自然语音。其最新版本为 1.2,拥有以下核心优势:核心功能与技术亮点高效且低门槛:只需 4GB 显存即可运行,极大地降低了硬件要求。此外,快速的推理速度能让您在短时间内获得所需的语音输出,提升了整体使用体验。支持多种模型:集成了包
只显示前20页数据,更多请搜索
Showing 265 to 284 of 284 results