关键词 "论文" 的搜索结果, 共 24 条, 只显示前 480 条
橙篇是由百度推出的一款AI写作工具,基于百度文库的庞大内容库和尖端AI技术,为用户提供了强大的长文件处理和内容创作能力。用户可以利用橙篇AI轻松理解、总结超大量、多格式、长篇幅的文件,并通过即时问答功能获得所需信息。此外,橙篇还支持长文生成、深度编辑和多模态创作,极大地丰富了用户的创作手段。橙篇的研发基于百度文库12亿内容的积累,结合了20万精调数据和1.4亿用户的行为数据,以及百度文库、百度学术
心流是阿里巴巴推出的基于星辰大模型的AI搜索助手,通过智能技术提升用户的知识获取效率。集成了近3000万篇学术论文资源,覆盖Nature、IEEE、ArXiv等权威期刊,支持学术问答、AI精读、段落总结、智能翻译和名词解释等功能,能帮助研究人员和学生快速理解和分析论文内容。心流提供DeepSeek渠道,联网搜索协助思考过程,具备通用问答、慢推理、私人知识库等功能,适用于市场调研、文档分析、内容创作
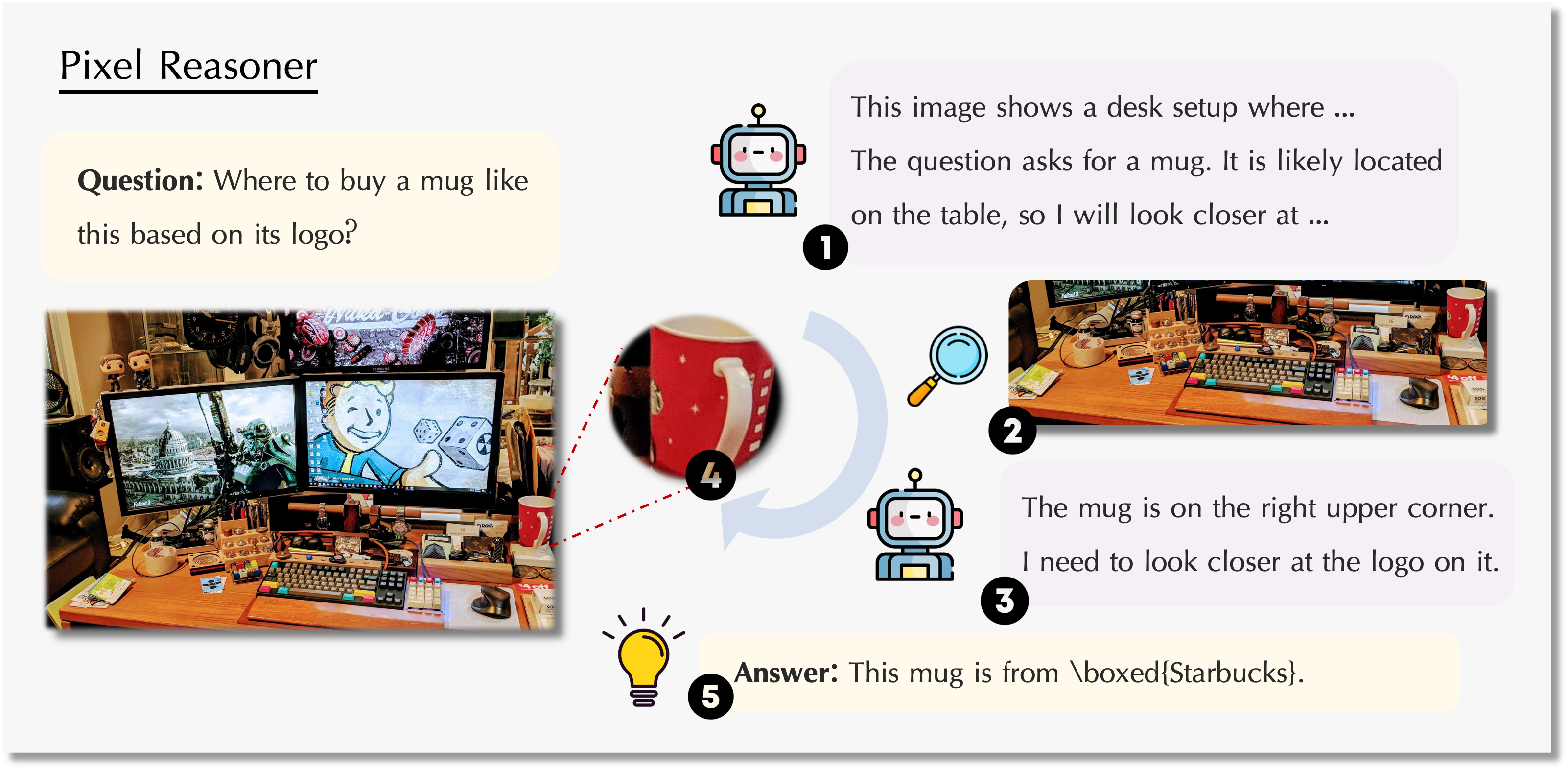
视觉语言模型(VLM),基于像素空间推理增强模型对视觉信息的理解和推理能力。模型能直接在视觉输入上进行操作,如放大图像区域或选择视频帧,更细致地捕捉视觉细节。Pixel Reasoner用两阶段训练方法,基于指令调优让模型熟悉视觉操作,用好奇心驱动的强化学习激励模型探索像素空间推理。Pixel Reasoner在多个视觉推理基准测试中取得优异的成绩,显著提升视觉密集型任务的性能。 Pixel R
Vid2World是清华大学联合重庆大学推出的创新框架,支持将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。模型基于视频扩散因果化和因果动作引导两大核心技术,解决传统VDM在因果生成和动作条件化方面的不足。Vid2World在机器人操作和游戏模拟等复杂环境中表现出色,支持生成高保真、动态一致的视频序列,支持基于动作的交互式预测。Vid2World为提升世界模
Qlib 是一个开源的、面向 AI 的量化投资平台,旨在利用 AI 技术挖掘量化投资的潜力,赋能研究,创造价值,涵盖从探索想法到落地生产的全过程。Qlib 支持多种机器学习建模范式,包括监督学习、市场动态建模和强化学习。 越来越多不同范式的 SOTA Quant 研究成果/论文正在 Qlib 中发布,以协作解决量化投资领域的关键挑战。例如,1)使用监督学习从丰富且异构的金融数据中挖掘市场复杂的非
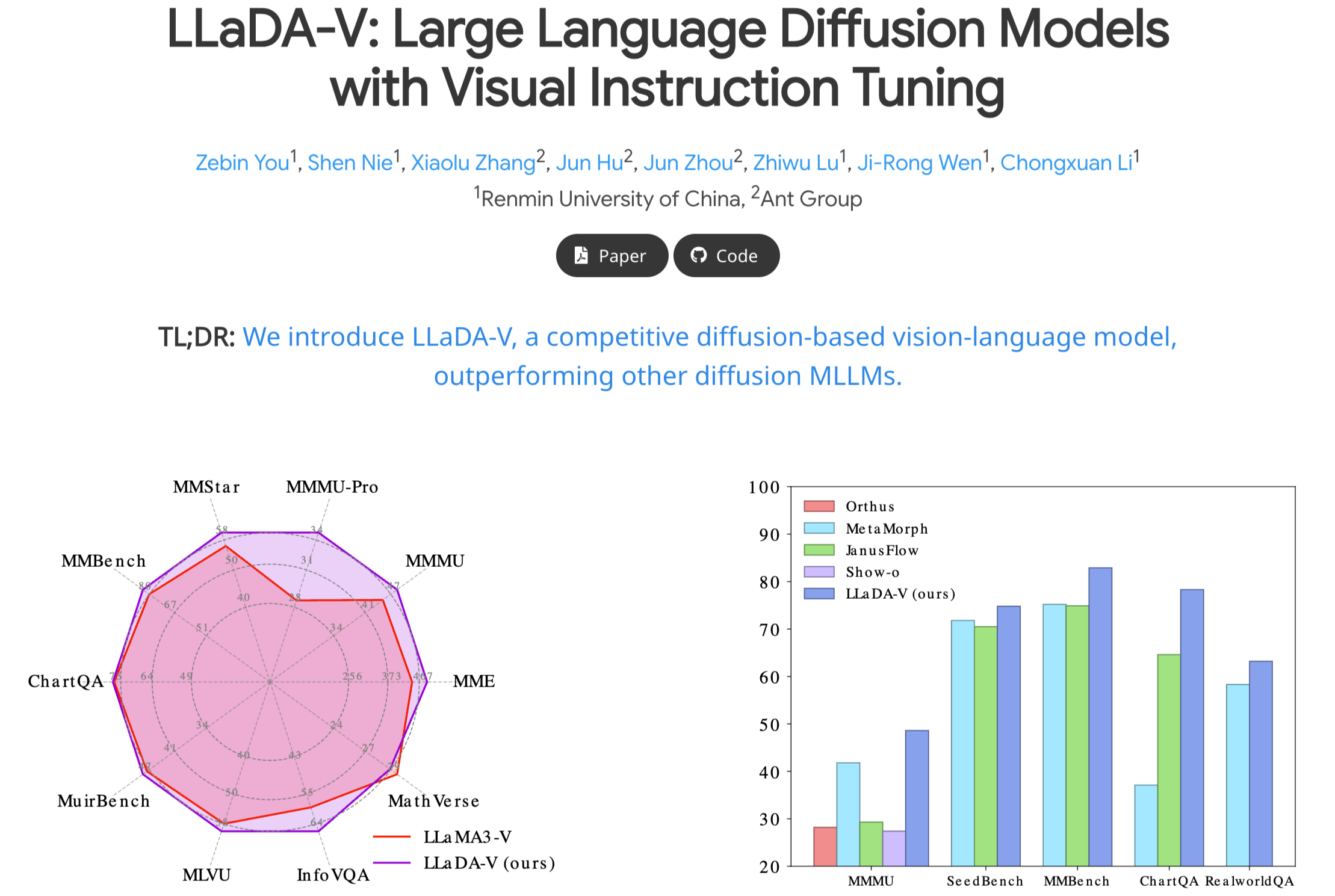
LLaDA-V是中国人民大学高瓴人工智能学院、蚂蚁集团推出的多模态大语言模型(MLLM),基于纯扩散模型架构,专注于视觉指令微调。模型在LLaDA的基础上,引入视觉编码器和MLP连接器,将视觉特征映射到语言嵌入空间,实现有效的多模态对齐。LLaDA-V在多模态理解方面达到最新水平,超越现有的混合自回归-扩散和纯扩散模型。 LLaDA-V的主要功能 图像描述生成:根据输入的图像生成详细的描述
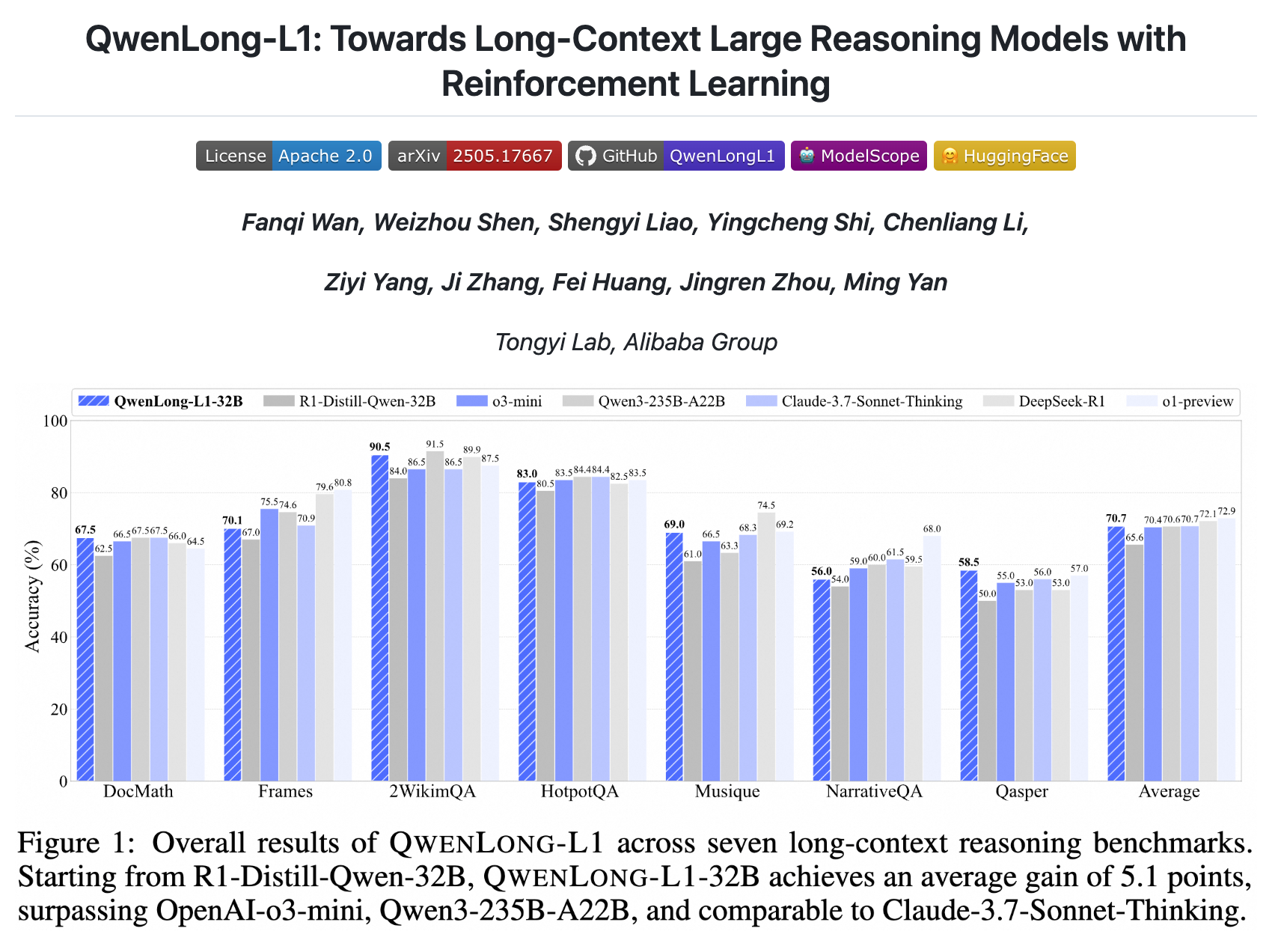
QwenLong-L1-32B 是阿里巴巴集团 Qwen-Doc 团队推出的,基于强化学习训练的首个长文本推理大模型。模型基于渐进式上下文扩展、课程引导的强化学习和难度感知的回顾性采样策略,显著提升在长文本场景下的推理能力。模型在多个长文本文档问答(DocQA)基准测试中表现优异,平均准确率达到了70.7%,超越OpenAI-o3-mini和Qwen3-235B-A22B等现有旗舰模型,且与Cla
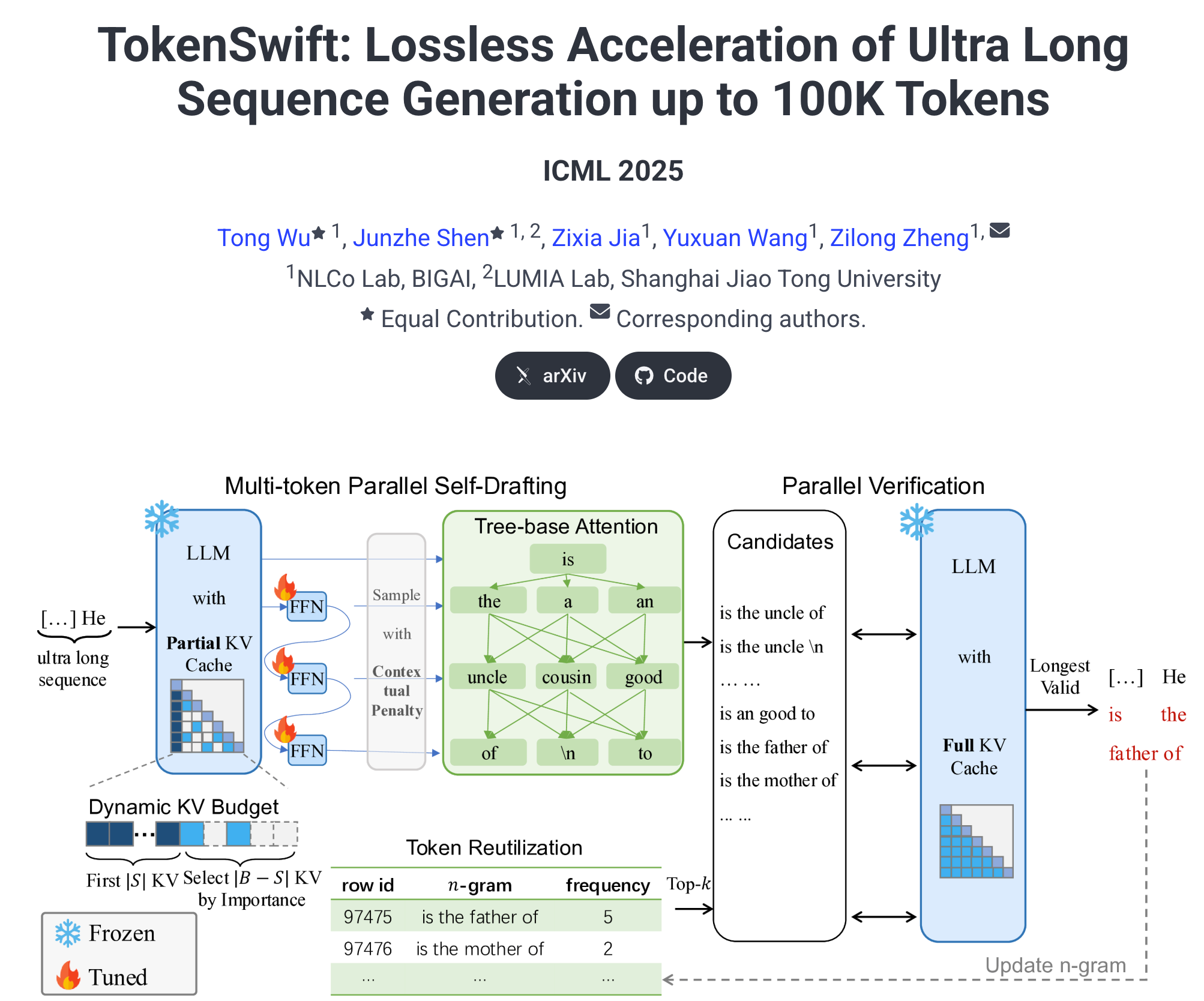
TokenSwift 是北京通用人工智能研究院团队推出的超长文本生成加速框架,能在90分钟内生成10万Token的文本,相比传统自回归模型的近5小时,速度提升了3倍,生成质量无损。TokenSwift 通过多Token生成与Token重用、动态KV缓存更新以及上下文惩罚机制等技术,减少模型加载延迟、优化缓存更新时间并确保生成多样性。支持多种不同规模和架构的模型,如1.5B、7B、8B、14B的MH
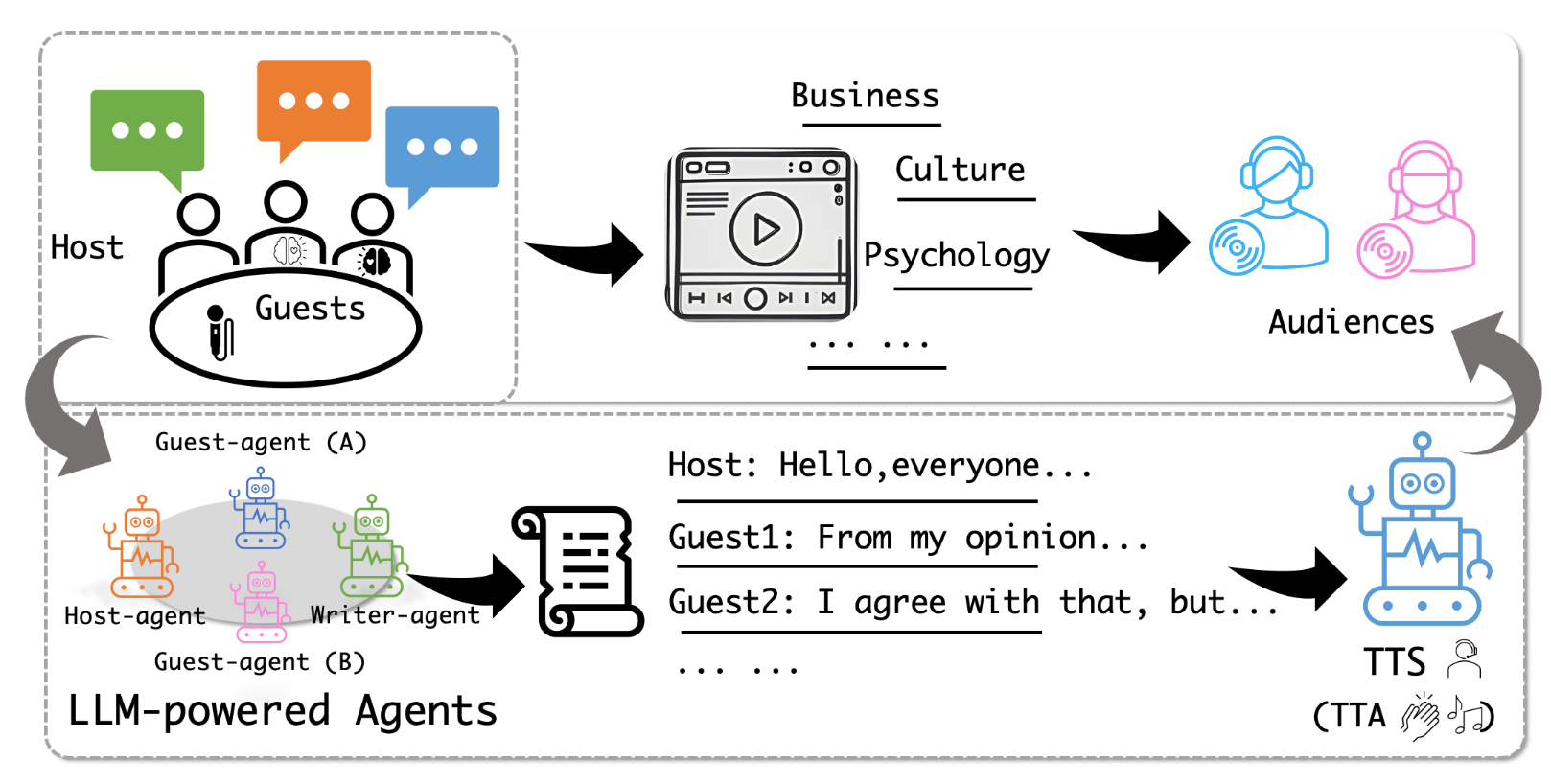
PodAgent 是香港中文大学、微软和小红书联合推出的播客生成框架。基于模拟真实的脱口秀场景,用多智能体协作系统(包括主持人、嘉宾和编剧)自动生成丰富且结构化的对话内容。PodAgent构建了多样化的声音库,用在精准匹配角色与声音,确保音频的自然度和沉浸感。PodAgent 引入基于大语言模型(LLM)的语音合成技术,生成富有表现力和情感的语音,让播客更具吸引力。PodAgent 推出了全面的评
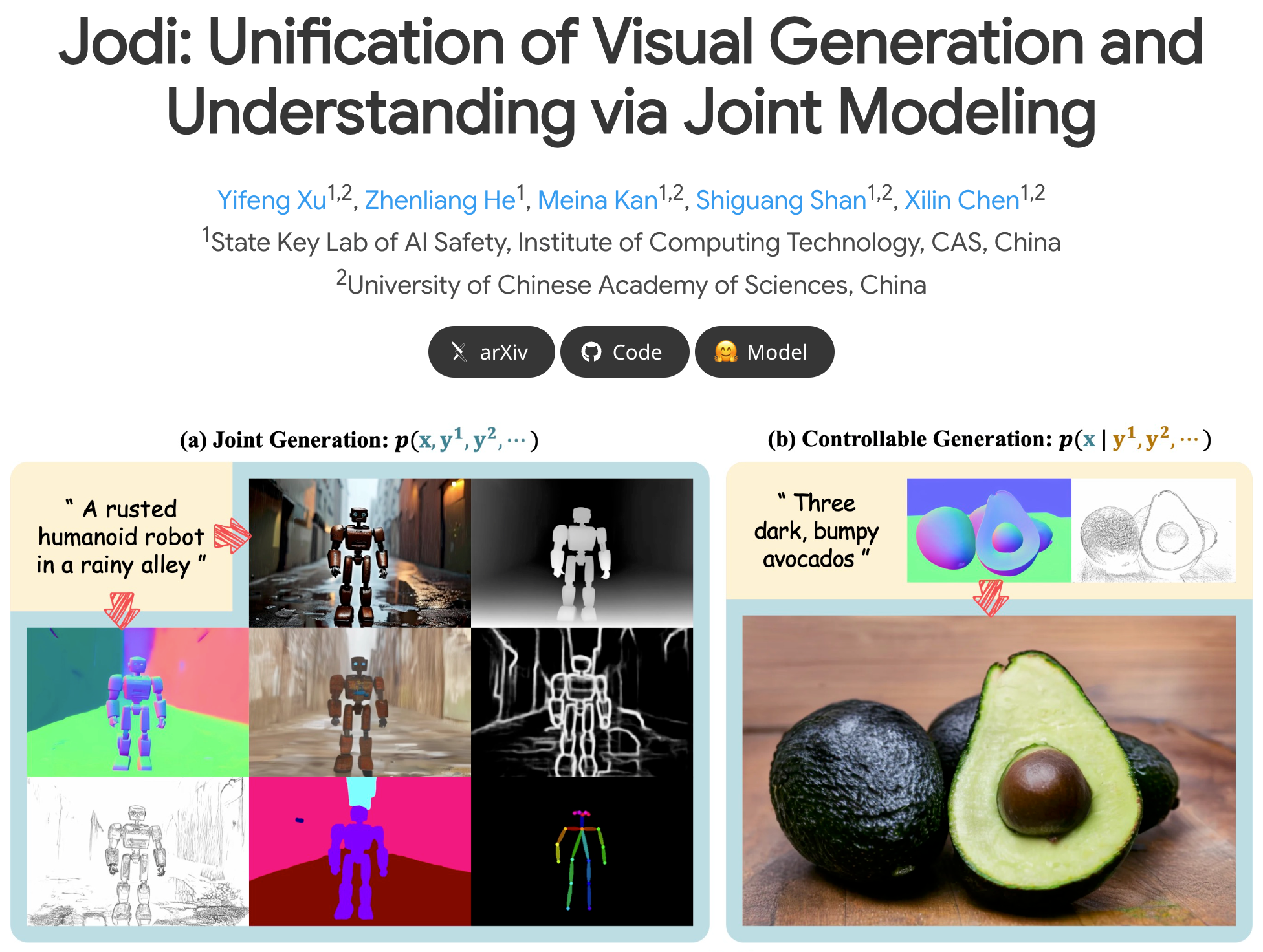
Jodi是中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,将视觉生成与理解统一起来。Jodi基于线性扩散Transformer和角色切换机制,执行联合生成(同时生成图像和多个标签)、可控生成(基于标签组合生成图像)及图像感知(从图像预测多个标签)三种任务。Jodi用包含20万张高质量图像和7个视觉域标签的Joint-1.6M数据集进行训练。Jodi在生成
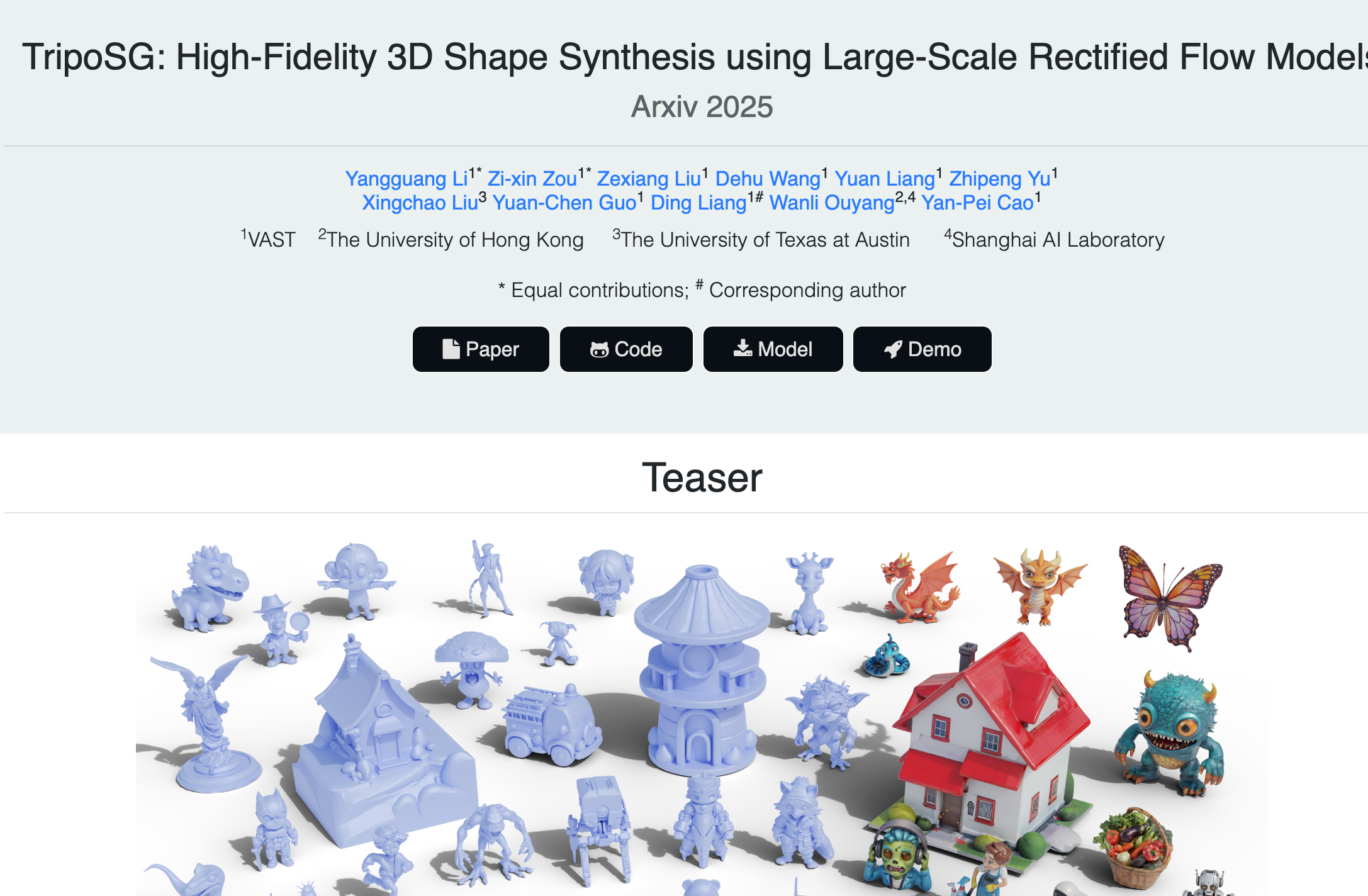
TripoSG 是 VAST-AI-Research 团队推出的基于大规模修正流(Rectified Flow, RF)模型的高保真 3D 形状合成技术, 通过大规模修正流变换器架构、混合监督训练策略以及高质量数据集,实现了从单张输入图像到高保真 3D 网格模型的生成。TripoSG 在多个基准测试中表现出色,生成的 3D 模型具有更高的细节和更好的输入条件对齐。 TripoSG的主要功能
OmniAudio 是阿里巴巴通义实验室语音团队推出的从360°视频生成空间音频(FOA)的技术。为虚拟现实和沉浸式娱乐提供更真实的音频体验。通过构建大规模数据集Sphere360,包含超过10.3万个视频片段,涵盖288种音频事件,总时长288小时,为模型训练提供了丰富资源。OmniAudio 的训练分为两个阶段:自监督的coarse-to-fine流匹配预训练,基于大规模非空间音频资源进行自监
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视
MoonCast 是零样本播客生成系统,从纯文本源合成自然的播客风格语音。通过长上下文语言模型和大规模语音数据训练,能生成几分钟长的播客音频,支持中文和英文。生成语音的自然性和连贯性,在长音频生成中能保持高质量。MoonCast 使用特定的LLM提示来生成播客脚本,通过语音合成模块将其转换为最终的播客音频。用户可以通过简单的命令和预训练权重快速生成播客。 MoonCast的项目地址 项目官
SmolVLA 是 Hugging Face 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。 SmolVLA的主要功能 多模态输入处理:SmolVLA 能处理多种输入,包括多幅图像、语言指令以及
Playmate是广州趣丸科技团队推出的人脸动画生成框架。框架基于3D隐式空间引导扩散模型,用双阶段训练框架,根据音频和指令精准控制人物的表情和头部姿态,生成高质量的动态肖像视频。Playmate基于运动解耦模块和情感控制模块,实现对生成视频的精细控制,显著提升视频质量和情感表达的灵活性。Playmate在音频驱动肖像动画领域取得重大进展,提供对情感和姿态的精细控制,能生成多种风格的动态肖像,具有
Teamo是夕小瑶团队推出的创新的多Agent协作AI生产力平台。通过模拟真实团队协作,由CEO Agent指挥多个专业Agent(如搜索员、咨询顾问、写作员等)协同工作,高效完成复杂任务。核心功能是“超级搜写”,能快速理解用户需求,深度调研信息,生成高质量的文稿。Teamo采用Agent2Agent(A2A)协作模式,可自主调度全球AI模型,通过并行工作和协同竞争,打破传统AI的局限。适用于科研
普林斯顿与复旦推出HistBench和HistAgent,首个人文AI评测基准 普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。 历史是关于时间中的人的
星月写作是专为中文内容创作者设计的AI写作助手,能根据用户输入的关键词、主题或大纲,快速生成高质量的文本内容。支持小说创作、公众号文章撰写,小红书文案、抖音脚本、学术论文工作报告等,星月写作能提供强大的支持。支持多种风格和语气,用户可以根据需求自由选择,比如正式、幽默或口语化。星月写作具备智能续写、润色、灵感激发等功能,帮助用户突破创作瓶颈,提升内容质量。提供丰富的素材库和智能工具集成,如词典查询
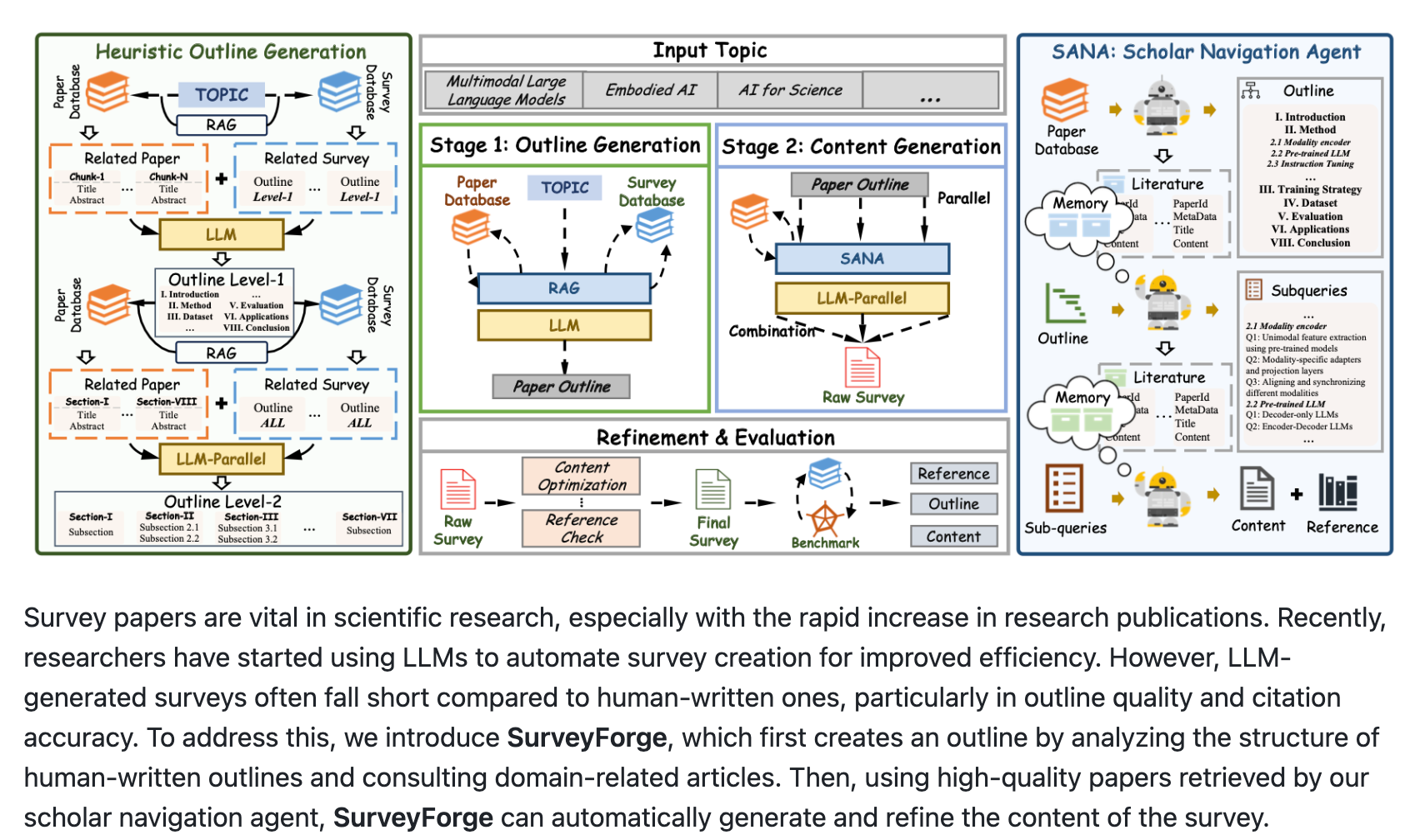
上海人工智能实验室、复旦、上交大等开源的一款自动撰写综述论文的AI工具:SurveyForge 实验结果,SurveyForge的大纲质量接近人工撰写水平,在参考文献质量、大纲质量和内容质量方面优于AutoSurvey等现有方法 生成约64k token的综述成本不到0.5美元,耗时约10分钟 SurveyForge分为两个阶段: 1、生成大纲,通过分析人工撰写的综述文章的大纲结构和参考领域相
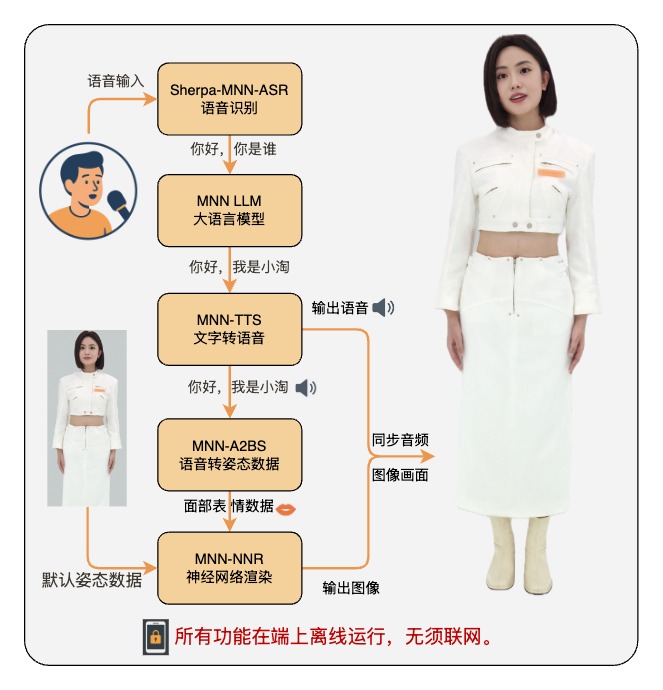
MNN轻量级高性能推理引擎 通用性 - 支持TensorFlow、Caffe、ONNX等主流模型格式,支持CNN、RNN、GAN等常用网络。 高性能 - 极致优化算子性能,全面支持CPU、GPU、NPU,充分发挥设备算力。 易用性 - 转换、可视化、调试工具齐全,能方便地部署到移动设备和各种嵌入式设备中。 什么是 TaoAvatar?它是阿里最新研究
一款论文转多模态海报工具:Paper2Poster,给它一篇论文,可自动生成一张学术海报,生成质量高制作成本低 生成的海报可读性较好,结构清晰、用词精简,比GPT-4清晰可读,比PPTAgent布局合理 输入论文PDF全自动处理,可以自动提取重点,进行智能排版设计,自动调整布局,维持论文逻辑顺序并控制信息密度
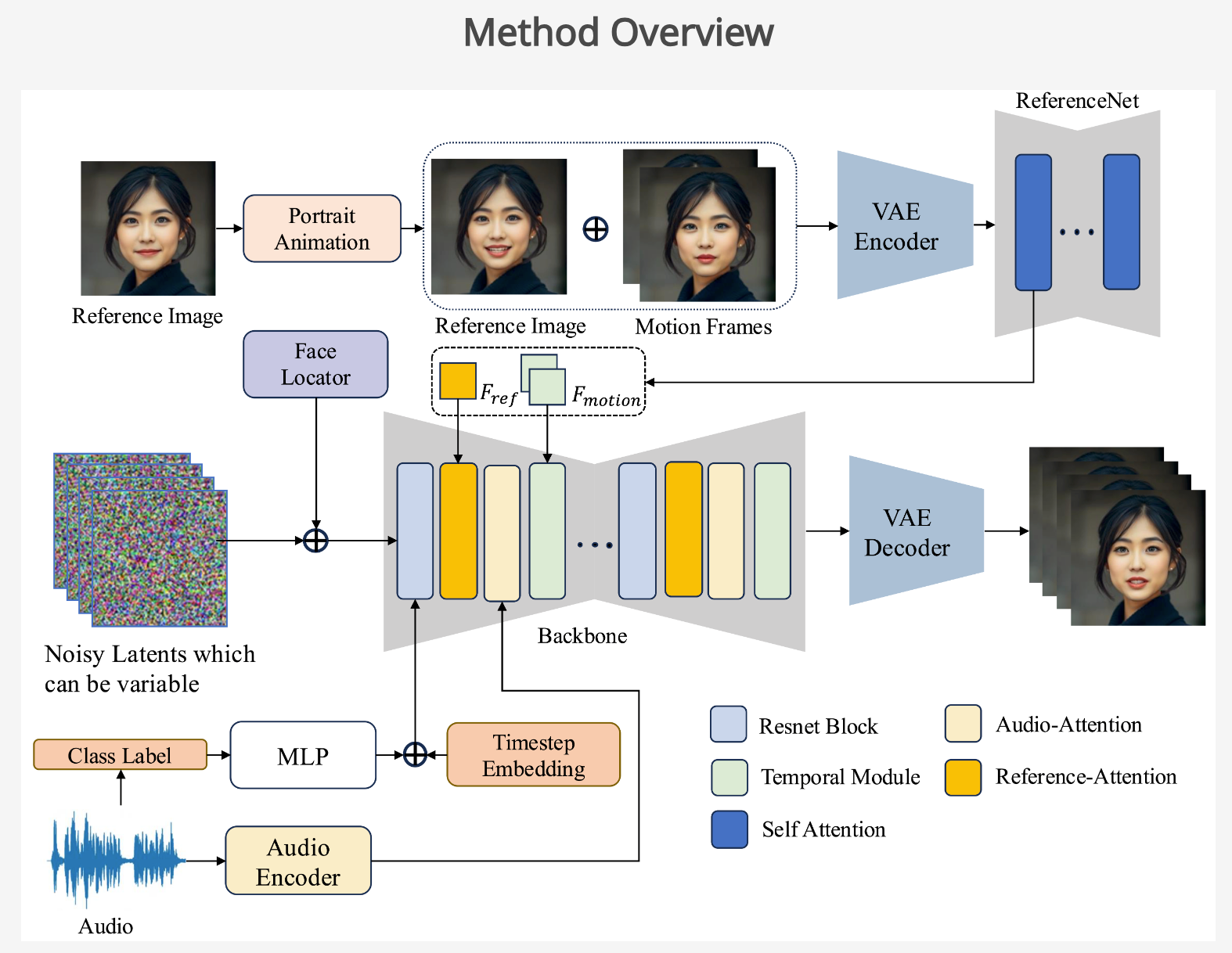
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
Seaweed APT2是字节跳动推出的创新的AI视频生成模型,通过自回归对抗后训练(AAPT)技术,将双向扩散模型转化为单向自回归生成器,实现高效、高质量的视频生成。模型能在单次网络前向评估(1NFE)中生成包含多帧视频的潜空间帧,显著降低了计算复杂性,通过输入回收机制和键值缓存(KV Cache)技术,支持长时间视频生成,解决了传统模型在长视频生成中常见的动作漂移和物体变形问题。能在单块GPU
只显示前20页数据,更多请搜索
Showing 241 to 264 of 309 results