关键词 "语音合成" 的搜索结果, 共 13 条, 只显示前 480 条
AiMakeSong 是基于人工智能的音乐和歌曲生成平台,支持用户通过简单的文本输入或歌词创作来生成高质量的音乐作品。用户可以选择将文字描述转化为音乐,或者将自己创作的歌词转化为完整的歌曲。平台提供了多种音乐风格和声音选项,包括流行、摇滚、说唱、古典等,以及男性、女性或乐器声音,满足不同用户的需求。 AiMakeSong的主要功能 文本转音乐:用户可以通过描述自己的音乐想法,将这些想法
MoonCast 是零样本播客生成系统,从纯文本源合成自然的播客风格语音。通过长上下文语言模型和大规模语音数据训练,能生成几分钟长的播客音频,支持中文和英文。生成语音的自然性和连贯性,在长音频生成中能保持高质量。MoonCast 使用特定的LLM提示来生成播客脚本,通过语音合成模块将其转换为最终的播客音频。用户可以通过简单的命令和预训练权重快速生成播客。 MoonCast的项目地址 项目官
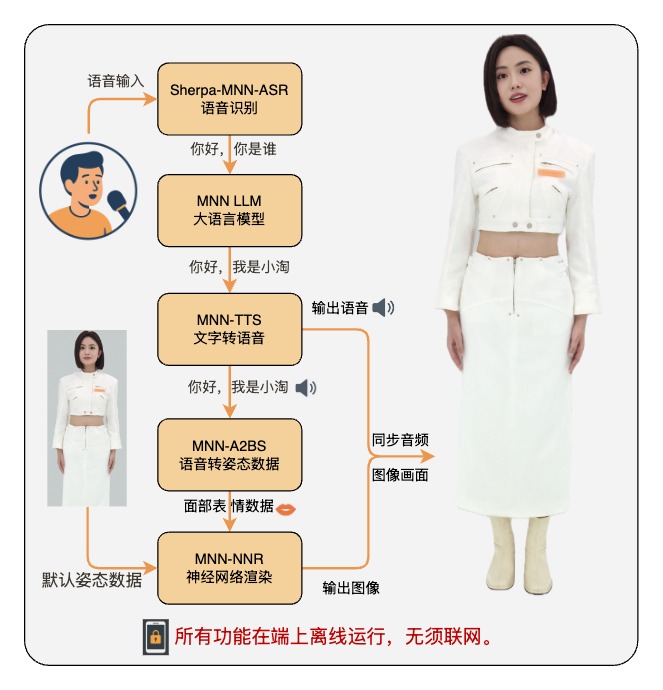
MNN轻量级高性能推理引擎 通用性 - 支持TensorFlow、Caffe、ONNX等主流模型格式,支持CNN、RNN、GAN等常用网络。 高性能 - 极致优化算子性能,全面支持CPU、GPU、NPU,充分发挥设备算力。 易用性 - 转换、可视化、调试工具齐全,能方便地部署到移动设备和各种嵌入式设备中。 什么是 TaoAvatar?它是阿里最新研究
HiAgent 是字节跳动推出的面向企业级客户的人工智能应用开发平台。帮助企业快速开发大模型应用和智能体(Agent),满足企业对数据安全和隐私的要求。通过低代码开发工具,HiAgent 降低了开发门槛,非技术背景的业务人员也能轻松上手,快速构建和部署 AI 应用。HiAgent 提供了丰富的行业模板和私有化部署选项,能满足不同企业的个性化需求。支持与企业现有系统的深度集成,帮助企业实现复杂流程的
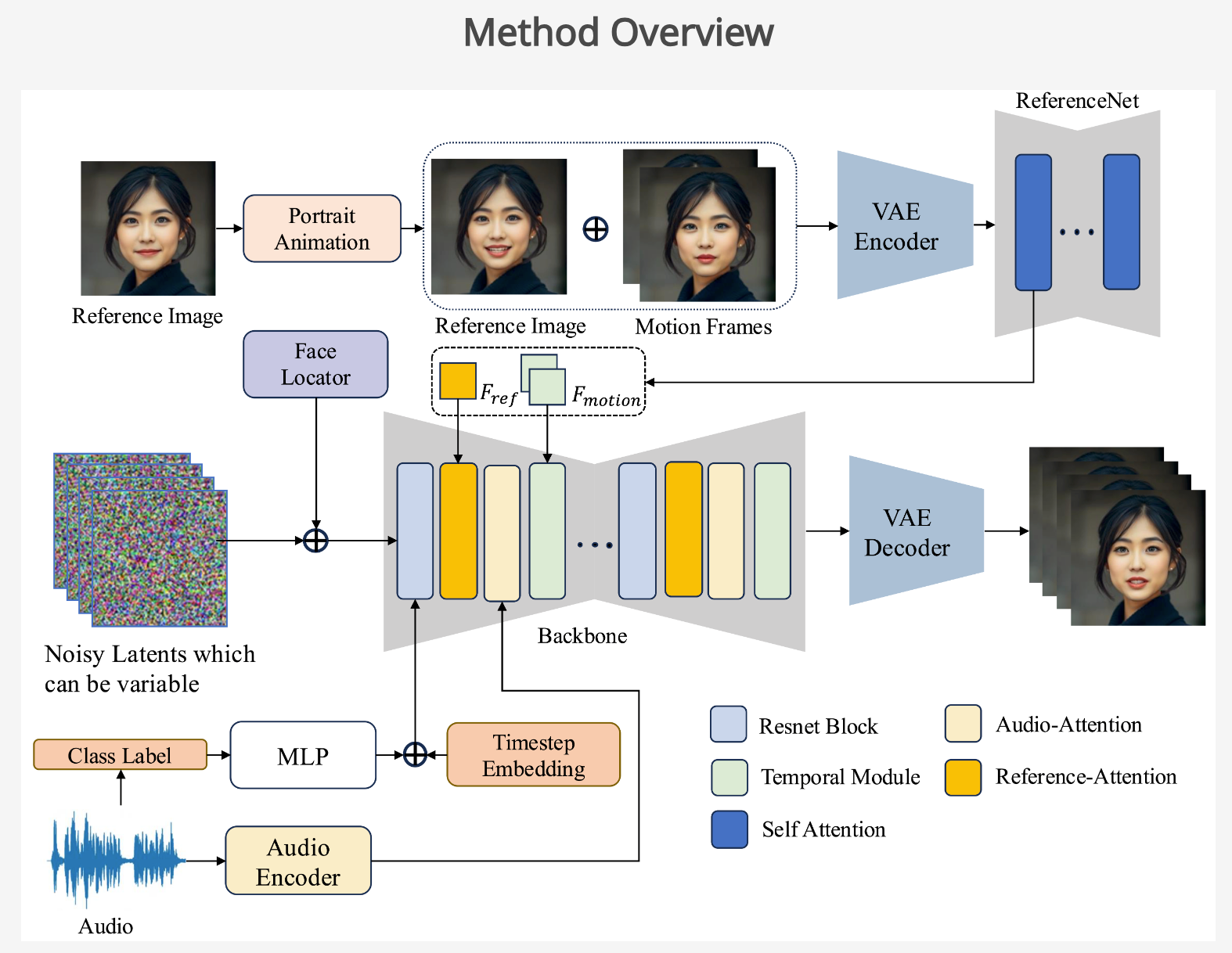
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
LeVo是腾讯AI实验室推出的AI唱歌模型,具备强大的音色克隆能力,仅需3秒音频即可精准复制目标音色,包括音调、情感和韵律,无需大量训练数据。LeVo支持分轨生成,可分别生成人声和伴奏音轨,为后期编辑提供便利。技术架构基于语言模型(LM),结合LeLM和音乐编解码器,能并行生成音轨,音质表现接近行业领先水平,在歌词对齐能力上表现卓越。 LeVo的项目地址 项目官网: https://lev
智声云配(DubbingX) 是 AI 智能配音工具,提供语音合成(TTS)、音色迁移、歌声转换等多种功能。工具支持中文、英文、日文、粤语等多语言,拥有近2500种情绪语态,支持高度定制,满足游戏、影视、动漫、有声书等多场景需求。工具音色版权合规,支持商用,能显著降低配音成本。智声云配结合专业高校和全球配音演员资源,致力于为用户提供高质量、多样化的音频解决方案。 智声云配官网:https://d
来福是北京耳朵时间科技推出的AI私人电台应用,应用主打AI语音驱动的“陪伴型内容”,结合语音合成与场景感知实现个性化播报,为用户提供沉浸式的音频体验。用户用语音交互点播节目、提问或聊天,享受7×24小时的声音陪伴。应用融合播客、智能语音助手与定制内容推荐的多重属性,用AI生成内容替代传统主播,重新定义私人电台的使用体验。 来福官网: https://laifu.fm/ 也可以下载APP使用
AudioGenie是腾讯AI Lab团队推出的多模态音频生成工具,能从视频、文本、图像等多种模态输入生成音效、语音、音乐等多种音频输出。工具采用无训练的多智能体框架,通过生成团队和监督团队的双层架构实现高效协同。生成团队负责将复杂的输入分解为具体的音频子事件,通过自适应混合专家(MoE)协作机制动态选择最适合的模型进行生成。监督团队则负责时空一致性验证,通过反馈循环进行自我纠错,确保生成的音频高
AIVoiceGen is a user-friendly AI voice generation platform focused on text-to-speech. It offers free access with no registration required, featuring diverse voices across languages, accents, and tones
小米集团AI实验室新一代 Kaldi 团队发布了基于 Flow Matching 架构的ZipVoice系列语音合成(TTS)模型——ZipVoice(零样本单说话人语音合成模型)与ZipVoice-Dialog(零样本对话语音合成模型)。作为 zipformer 在语音生成任务上的应用和探索,ZipVoice解决了现有零样本语音合成模型的参数量大、合成速度慢的痛点,在轻量化建模和推理加速上取得了
Fish Speech 是一款由 Fish Audio 开源的文本转语音(TTS)工具,支持中、英、日三国语言。它经过 15 万小时的多语种数据训练,能生成接近人类水平的自然语音。其最新版本为 1.2,拥有以下核心优势:核心功能与技术亮点高效且低门槛:只需 4GB 显存即可运行,极大地降低了硬件要求。此外,快速的推理速度能让您在短时间内获得所需的语音输出,提升了整体使用体验。支持多种模型:集成了包
只显示前20页数据,更多请搜索
Showing 241 to 253 of 253 results