关键词 "3D 世界" 的搜索结果, 共 24 条, 只显示前 480 条
SmolVLA 是 Hugging Face 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。 SmolVLA的主要功能 多模态输入处理:SmolVLA 能处理多种输入,包括多幅图像、语言指令以及
Huxe AI 是创新的个人音频伴侣应用,由谷歌旗下热门 AI 播客应用 NotebookLM 的核心团队成员创立。通过生成式 AI 技术,将用户关心的内容转化为个性化的音频体验。用户可以连接日历、邮件和兴趣领域,获取每日简报和定制化音频内容。能根据用户输入的主题生成深入研究的音频内容,提供智能互动,实时调整内容以满足用户需求。配备了生成式用户界面,为用户提供与音频相辅相成的视觉信息。 Huxe
Playmate是广州趣丸科技团队推出的人脸动画生成框架。框架基于3D隐式空间引导扩散模型,用双阶段训练框架,根据音频和指令精准控制人物的表情和头部姿态,生成高质量的动态肖像视频。Playmate基于运动解耦模块和情感控制模块,实现对生成视频的精细控制,显著提升视频质量和情感表达的灵活性。Playmate在音频驱动肖像动画领域取得重大进展,提供对情感和姿态的精细控制,能生成多种风格的动态肖像,具有
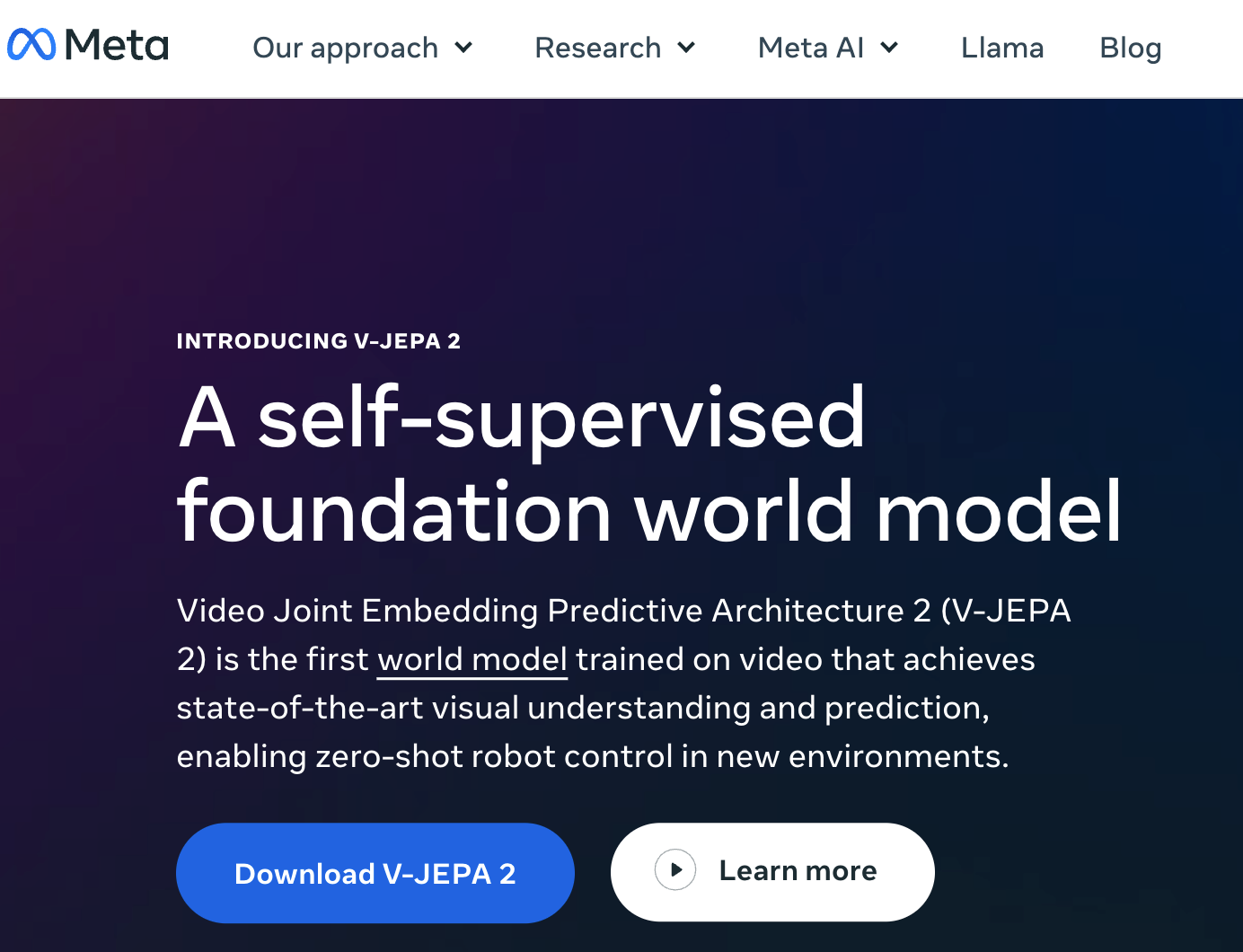
Meta 又有新的动作,推出基于视频训练的世界模型 V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。 Meta 表示,他们在追求高级机器智能(AMI)的目标过程中,关键在于开发出能像人类一样认知世界、规划陌生任务执行方案,并高效适应不断变化环境的
ChatPs 是创新的 Photoshop 插件,通过自然语言交互简化图像编辑流程。无需掌握复杂的 Photoshop 操作技巧或快捷键,只需用日常语言下达指令,ChatPs 可精准识别执行任务,例如选中图层、翻译文本、抠图、调整图像等。针对设计场景进行了专门训练,能满足从新手到资深设计师的多元需求,大幅减少重复性操作,提升设计效率。ChatPs 覆盖了 Photoshop 的核心功能,结合 AI
Seaweed APT2是字节跳动推出的创新的AI视频生成模型,通过自回归对抗后训练(AAPT)技术,将双向扩散模型转化为单向自回归生成器,实现高效、高质量的视频生成。模型能在单次网络前向评估(1NFE)中生成包含多帧视频的潜空间帧,显著降低了计算复杂性,通过输入回收机制和键值缓存(KV Cache)技术,支持长时间视频生成,解决了传统模型在长视频生成中常见的动作漂移和物体变形问题。能在单块GPU
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
EmbodiedGen 是用于具身智能(Embodied AI)应用的生成式 3D 世界引擎和工具包。能快速生成高质量、低成本且物理属性合理的 3D 资产和交互环境,帮助研究人员和开发者构建具身智能体的测试环境。EmbodiedGen 包含多个模块,如从图像或文本生成 3D 模型、纹理生成、关节物体生成、场景和布局生成等,支持从简单物体到复杂场景的创建。生成的 3D 资产可以直接用于机器人仿真和
北大团队通过对GPT-4o-Image的深入实验,突破性发现其在视觉特征提取环节中,相较于传统变分自编码器(VAE),更依赖语义编码器进行处理。这一关键洞察为统一模型架构设计开辟了全新路径。 基于上述研究成果,团队推出UniWorld-V1统一生成框架。该框架创新性融合高分辨率对比语义编码器与多模态大模型,仅需2.7M训练样本,即可实现图像理解、生成、编辑、感知等多任务处理。 实验数据显示,在
Dive3D是北京大学和小红书公司合作推出的文本到3D生成框架。框架基于分数的匹配(Score Implicit Matching,SIM)损失替代传统的KL散度目标,有效避免模式坍塌问题,显著提升3D生成内容的多样性。Dive3D在文本对齐、人类偏好和视觉保真度方面表现出色,在GPTEval3D基准测试中取得优异的定量结果,证明了在生成高质量、多样化3D资产方面的强大能力。 Dive3D的项目
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
Qwen VLo 是通义千问团队推出的多模态统一理解与生成模型。在多模态大模型的基础上进行了全面升级,能“看懂”世界,能基于理解进行高质量的再创造,实现了从感知到生成的跨越。能精准理解图像内容,在此基础上进行一致性和高质量的生成。用户可以通过自然语言指令要求模型对图像进行风格转换、场景重构或细节修饰,模型能灵活响应并生成符合预期的结果。Qwen VLo 支持多语言指令,打破语言壁垒,为全球用户提供
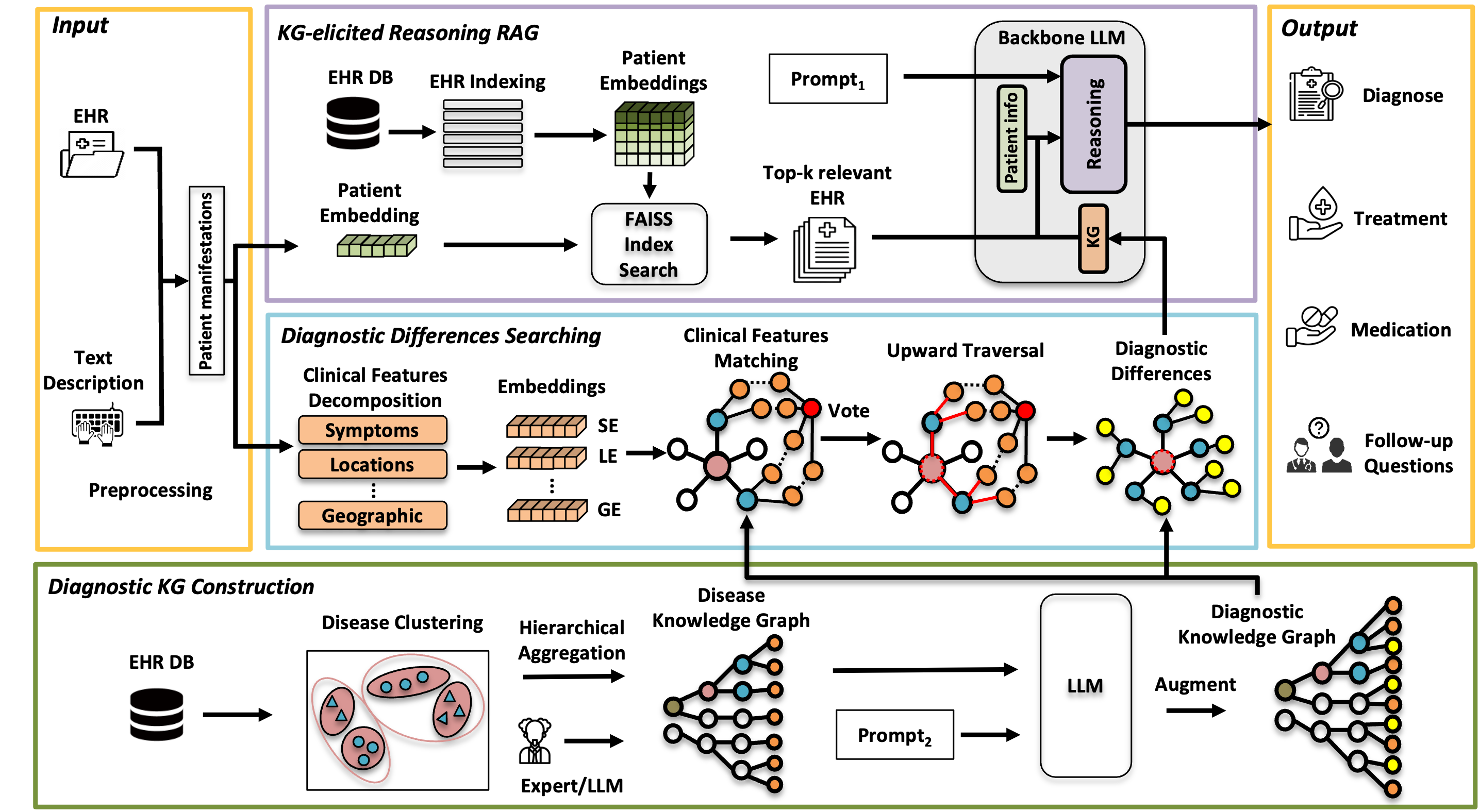
MedRAG是南洋理工大学研究团队提出的医学诊断模型,通过结合知识图谱推理增强大语言模型(LLM)的诊断能力。模型构建了四层细粒度诊断知识图谱,可精准分类不同病症表现,通过主动补问机制填补患者信息空白。MedRAG在真实临床数据集上诊断准确率提升了11.32%,具备良好的泛化能力,可应用于不同LLM基模型。MedRAG支持多模态输入,能实时解析症状并生成精准诊断建议。 MedRAG的主要功能
FairyGen 是大湾区大学推出的动画故事视频生成框架,支持从单个手绘角色草图出发,生成具有连贯叙事和一致风格的动画故事视频。框架借助多模态大型语言模型(MLLM)进行故事规划,基于风格传播适配器将角色的视觉风格应用到背景中,用 3D Agent重建角色生成真实的运动序列,基于两阶段运动适配器优化视频动画的连贯性与自然度。FairyGen 在风格一致性、叙事连贯性和运动质量方面表现出色,为个性化
圆周旅迹是专注于旅行规划的智能应用,帮助用户高效、便捷地安排旅行行程。通过简洁直观的界面设计和强大的AI功能,让用户能快速输入目的地、时间等信息,自动生成合理且个性化的行程安排。支持从社交平台一键导入链接、文字或图片,快速生成同款行程;提供3D全景地图导航和路径拖拽功能,帮助用户直观规划路线;方便旅行伙伴共同编辑行程并实时更新。圆周旅迹整合了实时交通数据,支持离线地图缓存,确保用户在无网络环境下也
1.本研究提出了蛋白质折叠进化模拟器(PFES),这是一个从随机氨基酸序列开始,以原子分辨率模拟蛋白质进化的计算框架。 2.作者利用PFES证明,稳定的球状蛋白质折叠可以相对容易地从随机序列进化而来,每个位点只需0.2到3个突变,与LUCA以来观察到的进化变化相当或更少。 3.值得注意的是,大约一半进化出的蛋白质与已知的自然折叠(例如HTH、SH3和β三明治)相似,而其余的则是独一无二的,这凸
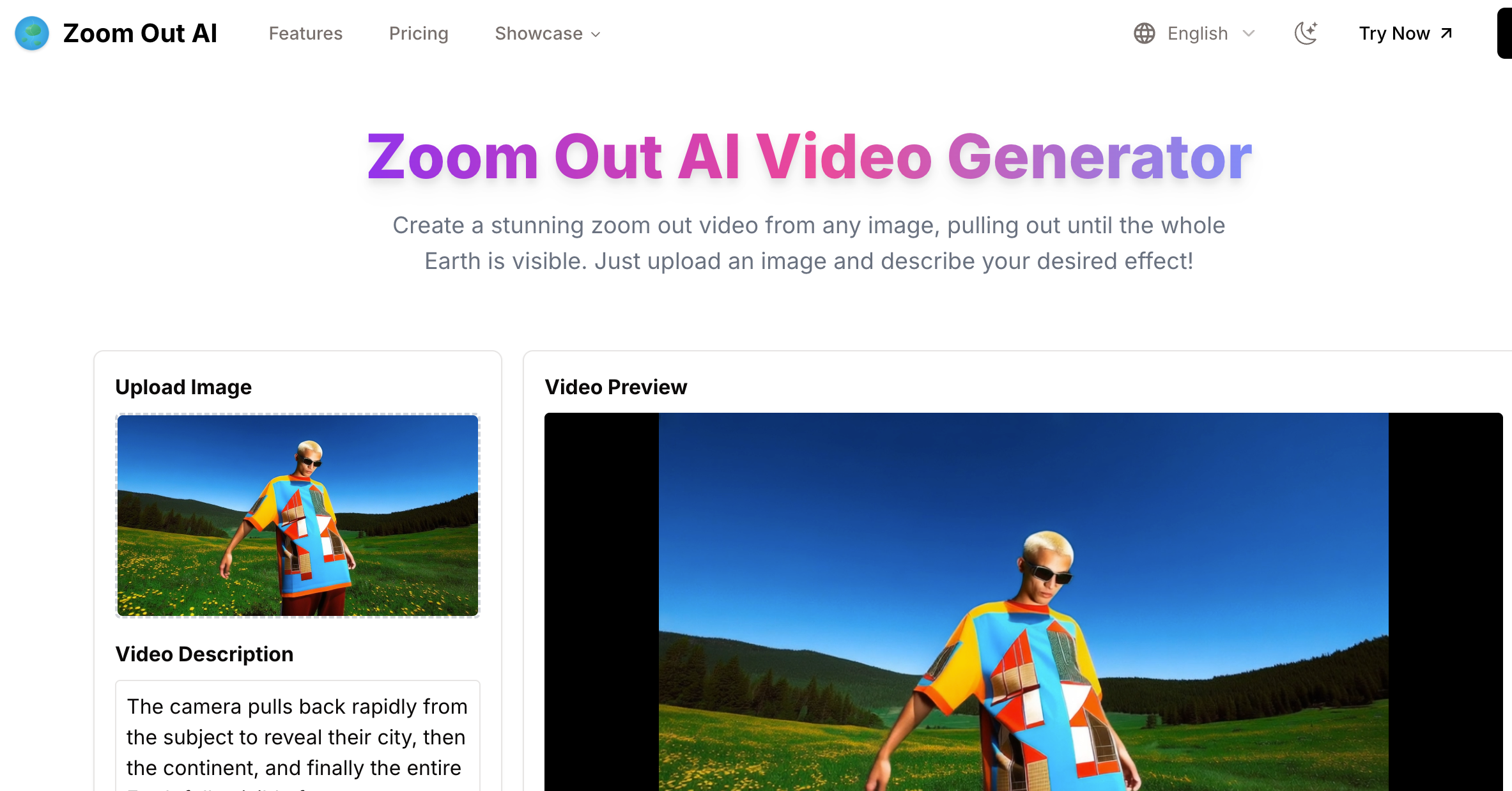
zoomoutai.pro 与众不同,因为它不仅仅是把图片放大。它会智能地猜测并补充缺失的部分,让图片看起来更清晰、更真实,而不是模糊或拉伸变形。它在浏览器里就能使用,不需要安装任何软件。很多工具只会把图片放大,但这个工具还能修复细节,让图片更好看。 Zoom Out AI 是一款免费工具,可将任何图像转换为缩小视频,直至看到地球。非常适合演示、创意项目和娱乐!无需下载或注册。
RoboBrain 2.0 是强大的开源具身大脑模型,能统一感知、推理和规划,支持复杂任务的执行。RoboBrain 2.0 包含 7B(轻量级)和 32B(全规模)两个版本,基于异构架构,融合视觉编码器和语言模型,支持多图像、长视频和高分辨率视觉输入,及复杂任务指令和场景图。模型在空间理解、时间建模和长链推理方面表现出色,适用机器人操作、导航和多智能体协作等任务,助力具身智能从实验室走向真实场景
RoboOS 2.0 是智谱开源的跨本体大小脑协同框架,专为具身智能设计。框架支持多机器人协作,基于集成MCP协议和无服务器架构实现轻量化部署,降低开发门槛。框架包含基于云计算的大脑模块,负责高级认知与多智能体协同;分布式小脑模块群,专司机器人专项技能执行;及实时共享内存机制,强化环境态势感知能力。RoboOS 2.0 提供标准化接口,消除硬件适配差异,用技能商店实现机器人技能模块的智能匹配与一键
PhotoG是全球首个内容营销端对端智能体,实现了基于大语言模型智能规划的全模态内容生成与自适应工具调用,致力于构建等同完整传统内容营销团队的全链路智能化。目前产品获得家具、鞋服、珠宝等领域数十家国际化品牌和超过十万海外用户的认可。 仅需一张产品图与自然语言,即可通过多智能体全自动生成基于市场调研和竞争格局的包含营销图片、营销视频、3D模型、营销文案、电商产品详情页、优化标题、描述和 SEO 等内
ImageBind是Meta公司推出的开源多模态AI模型,将文本、音频、视觉、温度和运动数据等六种不同类型的信息整合到一个统一的嵌入空间中。模型通过图像模态作为桥梁,实现其他模态数据的隐式对齐,无需直接的模态间配对数据。ImageBind在跨模态检索、零样本分类等任务中展现出色的性能,为创建沉浸式、多感官的AI体验提供新的可能性。 ImageBind的项目地址 项目官网:imagebind
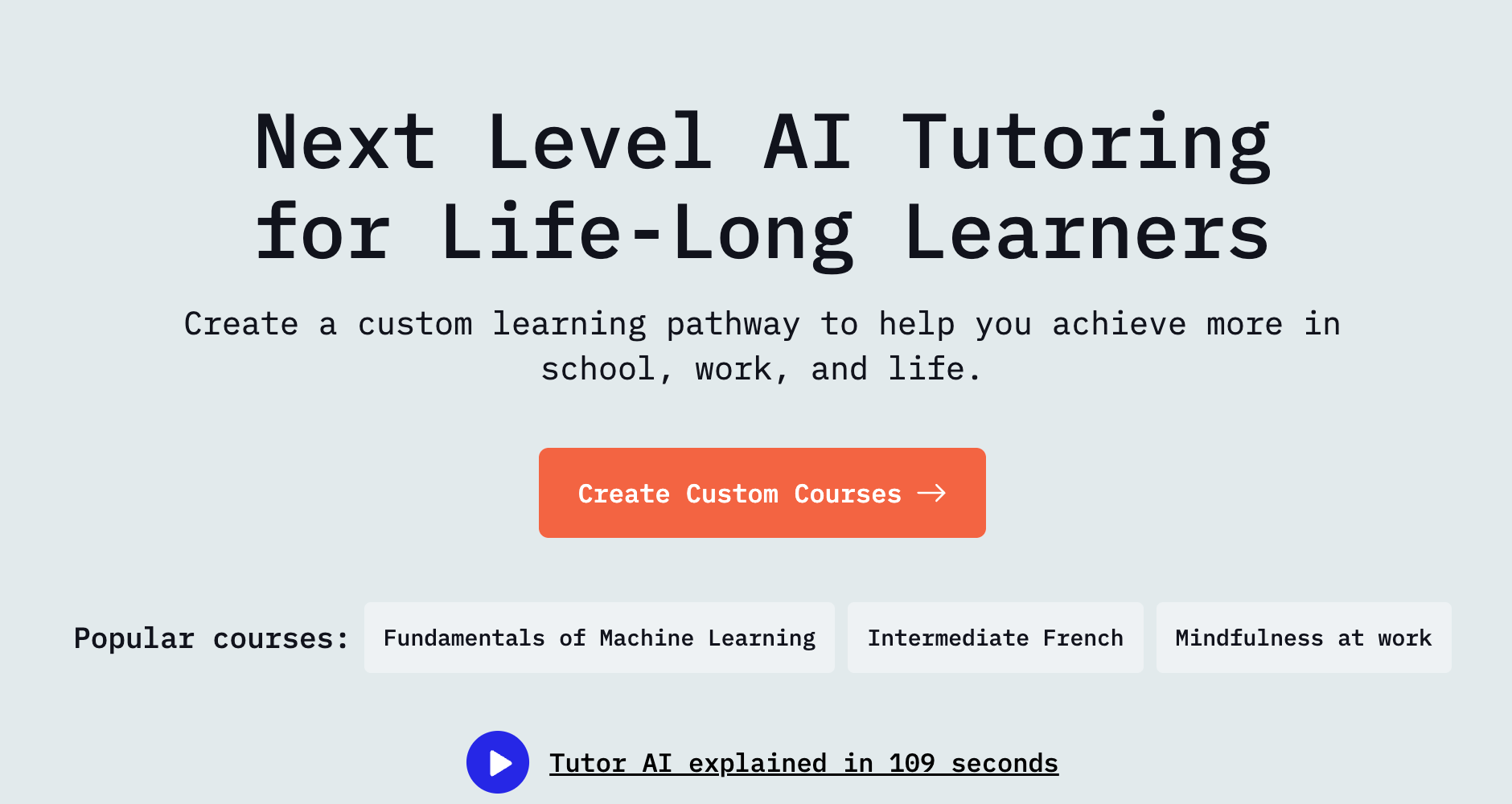
Tutor AI 是一个专为终身学习者设计的AI辅导平台。基于创建个性化学习路径,帮助用户在学业、工作和生活中取得更多成就。Tutor AI 基于先进的AI技术,根据用户的学习风格和知识水平,提供定制化的教学内容和练习。Tutor AI 覆盖广泛的学科领域,包括数学、编程、语言学习等热门主题。Tutor AI 的智能算法能实时分析学习者的表现,动态调整教学策略,确保学习过程既高效又有趣。Tutor
Ludo.ai 是强大的AI游戏开发平台,能帮助开发者从创意构思到实际开发的全过程。平台提供丰富的功能,包括游戏概念生成、AI 驱动的 3D 资产和图像生成、自定义精灵动画、视频生成、可玩原型制作、市场趋势分析、代码生成等。基于这些工具,开发者能快速生成创意、优化设计、验证想法,加速开发流程。 Ludo.ai的官网地址 官网地址:https://ludo.ai/
TextureNoise 是强大的在线3D纹理生成与编辑工具,帮助用户快速高效地创建高质量纹理。通过快速生成功能,能在几秒钟内生成令人惊叹的纹理,显著提升工作流程效率,节省时间。TextureNoise 提供画笔工具,支持用户对纹理的特定区域进行精确编辑和细节修饰,确保所有编辑和修复无缝融合,保持纹理的整体一致性。支持通用文件格式,与任何数字内容创作软件(如Blender、Maya等)完全兼容。
只显示前20页数据,更多请搜索
Showing 265 to 288 of 318 results