关键词 "3D 动画" 的搜索结果, 共 24 条, 只显示前 480 条
The repository SMMS creates an MCP server for instance-level semantic maps and provides a series of functional modules for 3D instance objects in semantic maps.
Model Context Protocol(MCP) for TRELLIS(SOTA text-to-3d/image-to-3d) models
Mirror of
RhinoMCP connects Rhino to Claude AI through the Model Context Protocol (MCP), enabling AI-assisted 3D modeling and architectural design.
Unified Cognitive Processing Framework - MCP server for Cline and more
MCP超级助手 MCP SuperAssistant 扩展是为了弥合 Perplexity、ChatGPT、Grok 等 AI 平台与模型上下文协议 (MCP) 工具之间的差距而创建的。虽然这些 AI 平台在常识和推理方面功能强大,但它们缺乏执行特定工具或直接访问外部系统的能力。此扩展通过提供一种无缝的方式来检测、执行和集成这些平台中的 MCP 工具,从而解决了该问题。 ## 安装说明 h
Meta发布AssetGen 2.0 AI模型,可高效生成3D资产 Meta发布了AssetGet 2.0版本,Meta表示,2.0显著提升了细节和保真度,其中包括几何一致性和极其精细的细节。“AssetGen 2.0为行业树立了全新标准,并利用生成式AI突破了可能性的界限。” 从技术原理来看,AssetGen 1.0需要根据提示生成目标素材的多个2D图像视图,然后
Lovart 全球首个设计 Agent 体验 Lovart 的三个特点: 一、全链路设计和执行,一句话搞定 以前的文生图工具,它们所提供的任务是“生成图片”这一环。 而设计 Agent,则像一位“设计执行官”,覆盖从创意拆解到专业交付的整个视觉流程。 从意图拆解 → 任务链 → 最后成品,一句话全搞定。 单次可以执行上
昆仑万维正式开源(17B+)Matrix-Game大模型,即Matrix-Zero世界模型中的可交互视频生成大模型。Matrix-Game是Matrix系列在交互式世界生成方向的正式落地,也是工业界首个开源的10B+空间智能大模型,它是一个面向游戏世界建模的交互式世界基础模型,专为开放式环境中的高质量生成与精确控制而设计。 空间智能作为AI时代的重要前沿技术,正在重塑我们与虚拟世界的
Step1X-3D是什么 Step1X-3D 是StepFun联合LightIllusions推出的高保真、可控的 3D 资产生成框架。基于严格的数据整理流程,从超过 500 万个 3D 资产中筛选出 200 万个高质量数据,创建标准化的几何和纹理属性数据集。Step1X-3D 支持多模态条件输入,如文本和语义标签,基于低秩自适应(LoRA)微调实现灵活的几何控制。Step1X-3D 推动了 3
VACE(Video Creation and Editing)是阿里巴巴通义实验室推出的一站式视频生成与编辑框架。基于整合多种视频任务(如参考视频生成、视频到视频编辑、遮罩编辑等)到一个统一模型中,实现高效的内容创作和编辑功能。VACE的核心在于Video Condition Unit(VCU),将文本、图像、视频和遮罩等多种模态输入整合为统一的条件单元,支持多种任务的灵活组合。开源的 Wan2
Medeo是创新的AI驱动视频制作工具。用户输入简短描述,Medeo能快速生成包含完整剧情、配音和字幕的高清视频。Medeo支持多种视频类型,如故事片、产品演示、培训视频等。Medeo提供从URL生成新闻视频、基于脚本生成悬疑小说视频及生成吉卜力风格动画等功能。Medeo能帮助用户大大节省时间和精力,让视频创作变得简单高效。 Medeo的主要功能 快速生成视频:输入描述快速生成含剧情、
FaceShot是同济大学、上海 AI Lab和南京理工大学推出的新型无需训练的肖像动画生成框架。用外观引导的地标匹配模块和基于坐标的地标重定位模块,为各种角色生成精确且鲁棒的地标序列,基于潜在扩散模型的语义对应关系,跨越广泛的角色类型生成面部动作序列。将地标序列输入预训练的地标驱动动画模型生成动画视频。FaceShot突破对现实肖像地标的限制,适用于任何风格化的角色和驱动视频,或作为插件与任何地
WorldMem 是南洋理工大学、北京大学和上海 AI Lab 推出的创新 AI 世界生成模型。模型基于引入记忆机制,解决传统世界生成模型在长时序下缺乏一致性的关键问题。在WorldMem中,智能体在多样化场景中自由探索,生成的世界在视角和位置变化后能保持几何一致性。WorldMem 支持时间一致性建模,模拟动态变化(如物体对环境的影响)。模型在 Minecraft 数据集上进行大规模训练,在真实
MSQA(Multi-modal Situated Question Answering)是大规模多模态情境推理数据集,提升具身AI代理在3D场景中的理解与推理能力。数据集包含251K个问答对,覆盖9个问题类别,基于3D场景图和视觉-语言模型在真实世界3D场景中收集。MSQA用文本、图像和点云的交错多模态输入,减少单模态输入的歧义。引入MSNN(Multi-modal Next-step Navi
Sketch2Anim 是爱丁堡大学联合Snap Research、东北大学推出的自动化框架,能将2D草图故事板直接转换为高质量的3D动画。基于条件运动合成技术,用3D关键姿势、关节轨迹和动作词精确控制动画的生成。框架包含两个核心模块,多条件运动生成器和2D、3D神经映射器。Sketch2Anim能生成自然流畅的3D动画,支持交互式编辑,极大地提高动画制作的效率和灵活性。 Sketch2Anim
Seedance 1.0 lite是火山引擎推出的豆包视频生成模型的小参数量版本,支持文生视频和图生视频两种生成方式,支持生成5秒或10秒、480p或720p分辨率的视频。具备影视级视频生成质量,能精细控制人物外貌、衣着、表情动作等细节,支持360度环绕、航拍、变焦等多种运镜技术,生成的视频画质细腻、美感十足。模型广泛用在电商广告、娱乐特效、影视创作、动态壁纸等领域,能有效降低制作成本和周期。
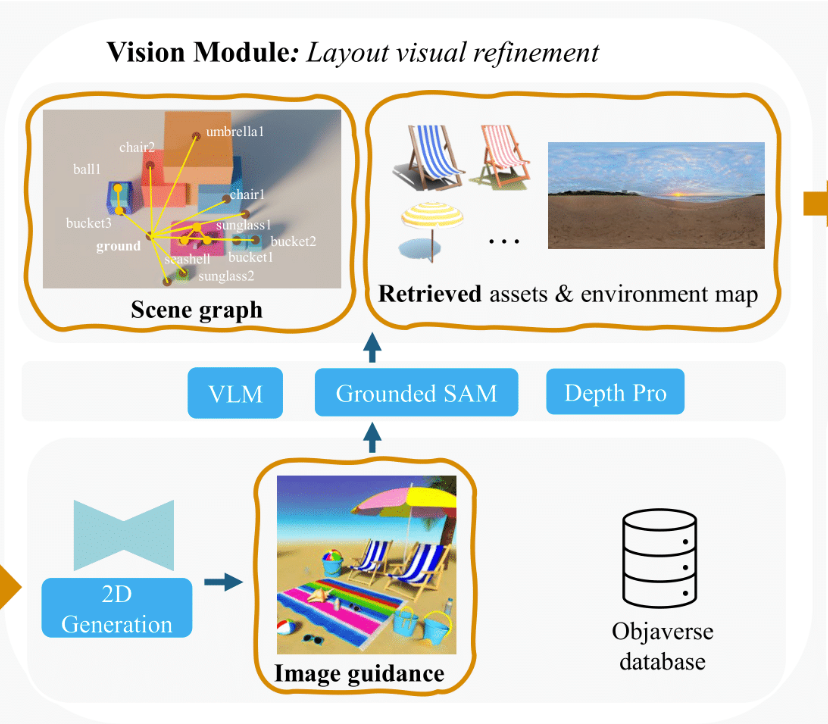
Scenethesis 是 NVIDIA 推出的创新框架,用在从文本生成交互式 3D 场景。框架结合大型语言模型(LLM)和视觉感知技术,基于多阶段流程实现高效生成,用 LLM 进行粗略布局规划,基于视觉模块细化布局生成图像指导,用优化模块调整物体姿态确保物理合理性,基于判断模块验证场景的空间连贯性。Scenethesis 能生成多样化的室内外场景,具有高度的真实感和物理合理性,广泛应用在虚拟内容
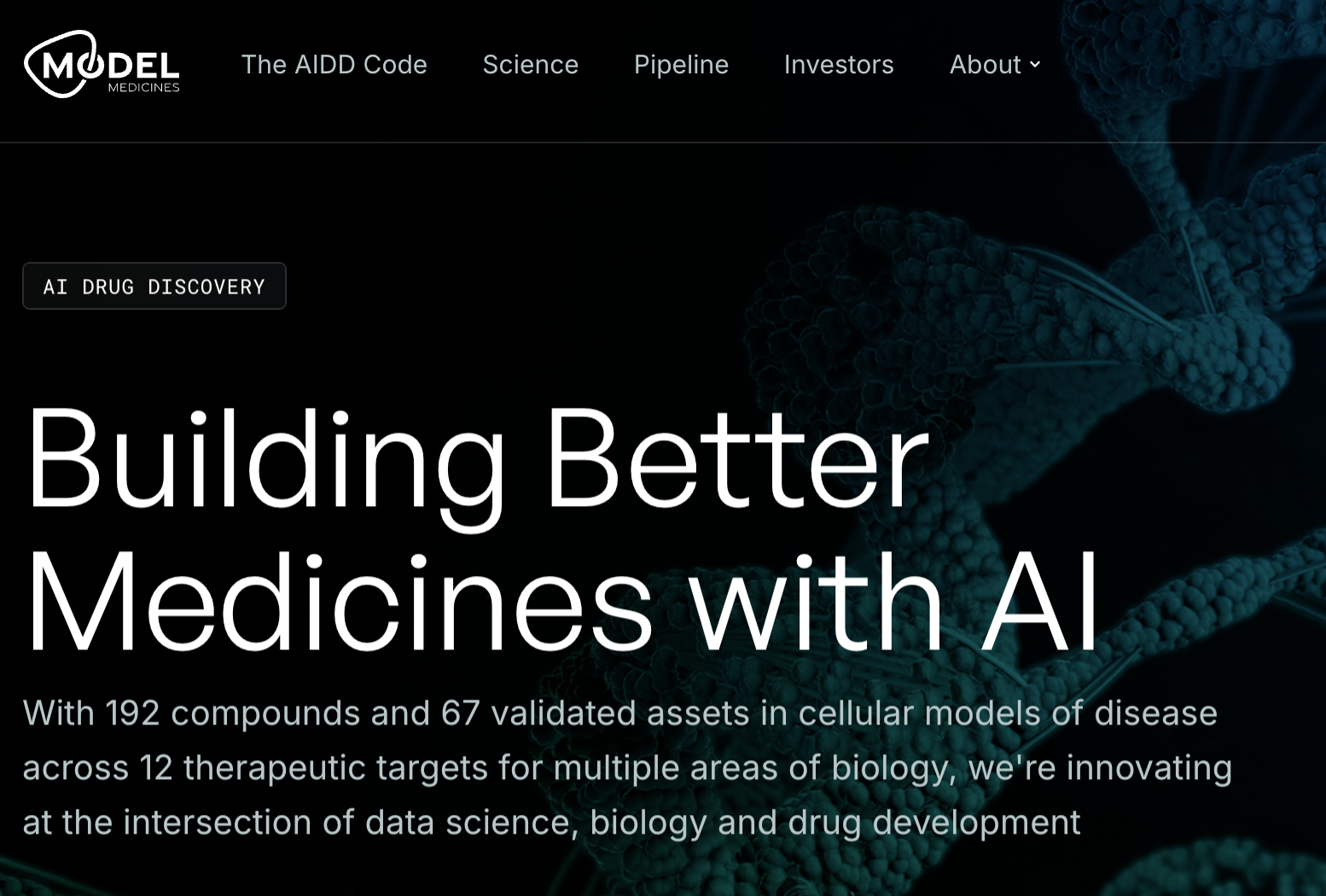
Model Medicines 拥有人工智能药物研发公司中公开研发管线规模最大的公司之一。该公司拥有 192 种化合物,针对 26 个治疗靶点。所有化合物均通过该公司的 GALILEO 平台发现,该平台旨在研究 3D 蛋白质结构中相互作用的原子“群”。 今年4月,Model及其合作伙伴的研究团队发布了一份预印本,确定了RdRp Thumb-1位点,该位点代表了正义单链RNA病毒中一个潜在的可用药
Mujoco(Multi-Joint dynamics with Contact)是一款用于机器人学、生物力学等领域的高性能物理仿真引擎,其核心功能包括动力学模拟、接触力建模及多关节系统仿真。该工具提供直观的操作界面、丰富的物理参数配置以及灵活的约束条件设置,适用于复杂机械系统或生物运动的模拟分析。以下从操作功能、仿真交互机制、核心术语与参数三个维度展开说明。 MuJoCo是“多关节接触动力学”
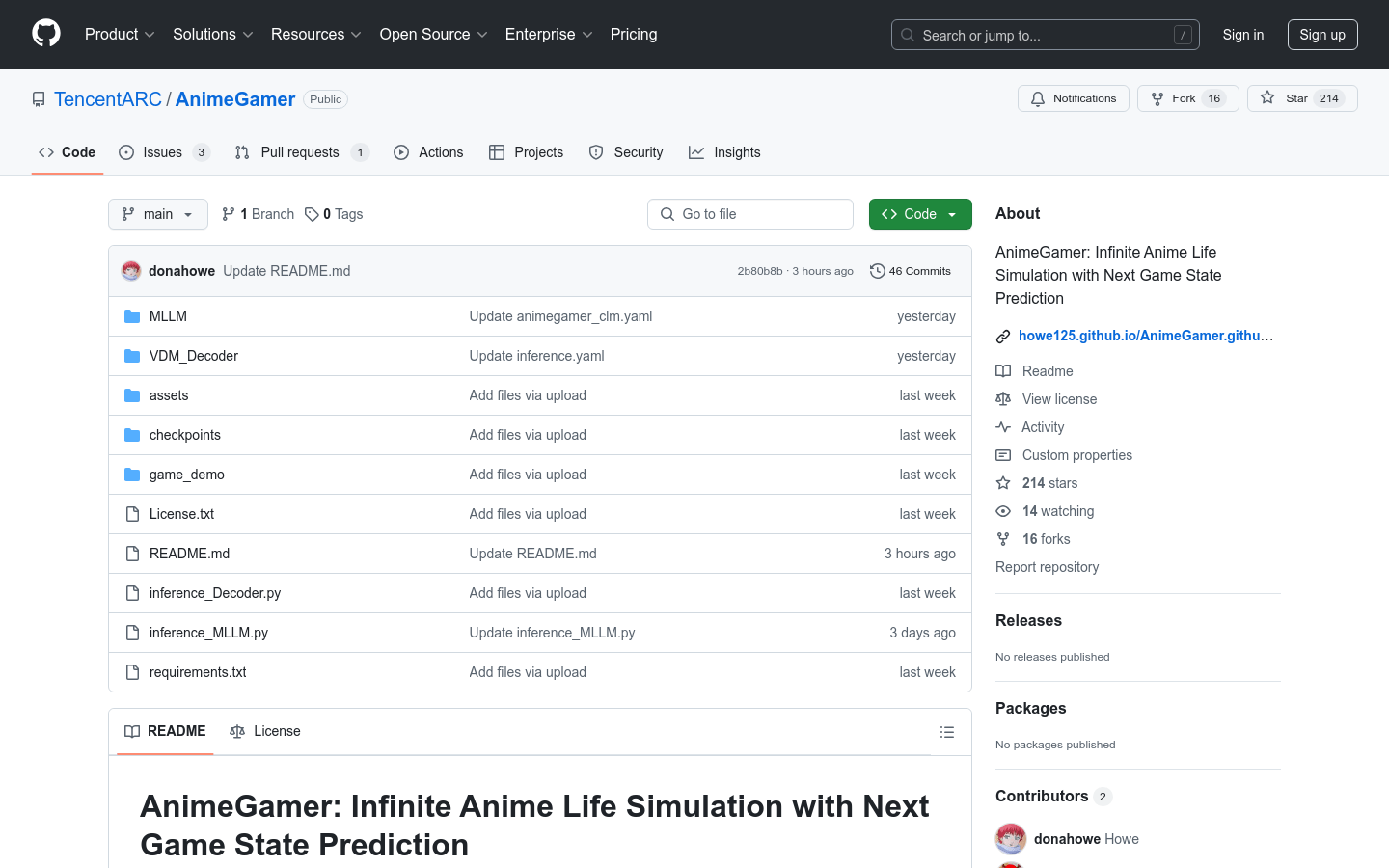
AnimeGamer 是基于多模态大型语言模型(MLLM)构建的,可以生成动态动画镜头和角色状态更新,为用户提供无尽的动漫生活体验。它允许用户通过开放式语言指令与动漫角色互动,创建独特的冒险故事。该产品的主要优点包括:动态生成与角色交互的动画,能够在不同动漫之间创建交互,丰富的游戏状态预测等。 快速入门 🔮 环境设置 要设置推理环境,您
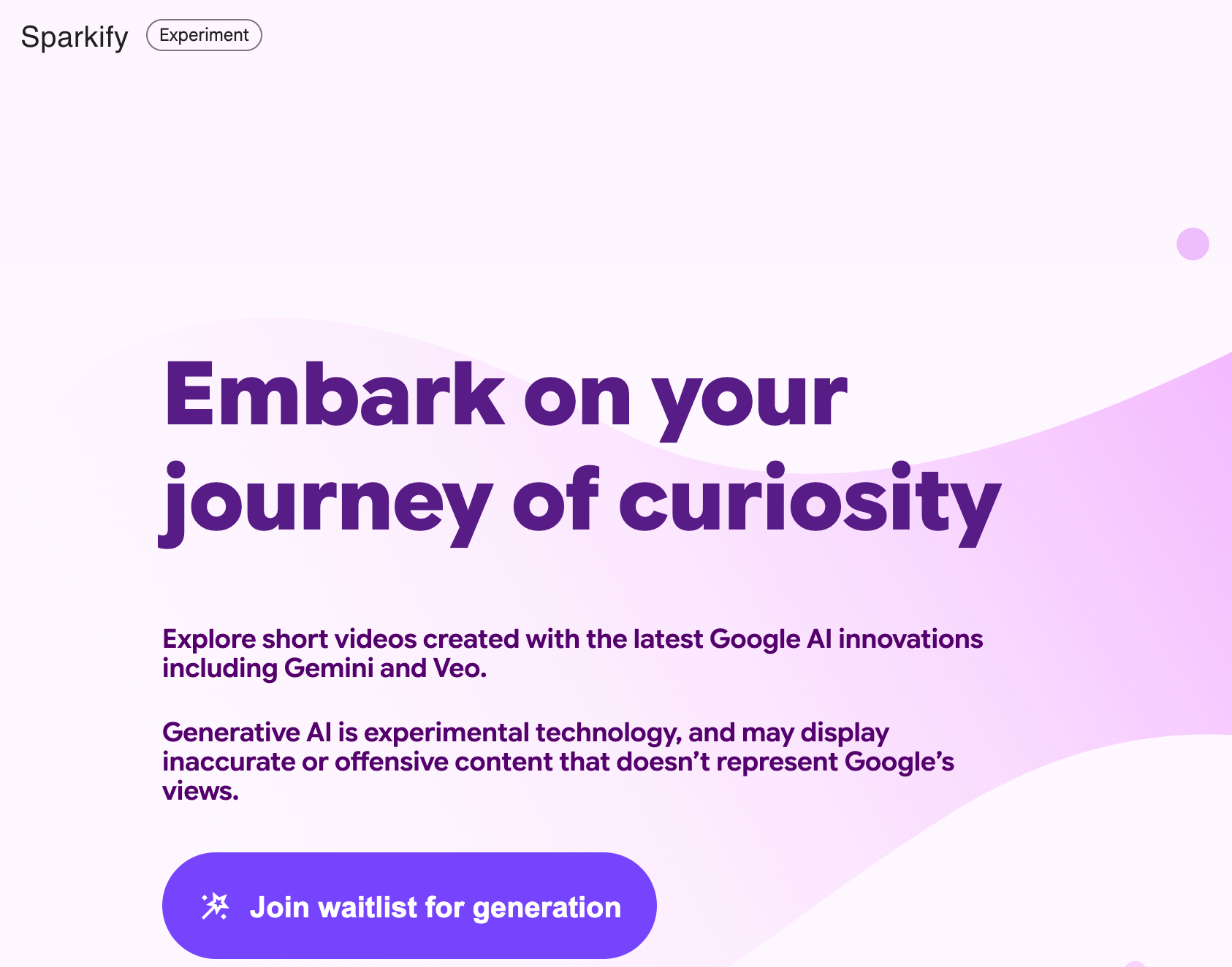
Sparkify是谷歌推出的AI动画视频生成工具,基于Gemini 2.5和Veo 2模型。用户输入问题或复杂概念后,Sparkify能在2分钟内生成直观的动画短视频,讲解知识点。Sparkify多模态处理能力结合Google Search数据,确保内容准确且与最新信息同步。Sparkify适用于教育、科普和企业培训等领域,提升理解效率和传播效果。Sparkify目前处于内测阶段,访问官网加入等候
Aurora是微软研究院推出的13亿参数的大气基础模型,基于从海量大气数据中提取有价值信息,用在预测全球天气模式、空气污染和海洋波浪等大气过程。模型用预训练和微调的架构,处理不同分辨率和压力水平的数据。Aurora在多个预测任务中表现出色,包括高分辨率天气预测、空气污染预测和热带气旋轨迹预测,计算速度比传统数值天气模型快约5000倍。模型提高了预测精度,降低计算成本,为应对气候变化和极端天气事件提
只显示前20页数据,更多请搜索
Showing 361 to 384 of 417 results