关键词 "3D 动画" 的搜索结果, 共 24 条, 只显示前 480 条
HRAvatar是清华大学联合IDEA团队推出的单目视频重建技术,支持从普通单目视频中生成高质量、可重光照的3D头像。HRAvatar用可学习的形变基和线性蒙皮技术,基于精准的表情编码器减少追踪误差,提升重建质量。HRAvatar将头像外观分解为反照率、粗糙度和菲涅尔反射等属性,结合物理渲染模型,实现真实的重光照效果。HRAvatar在多个指标上优于现有方法,支持实时渲染(约155 FPS),为数
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
Google Beam是谷歌推出的AI驱动的3D视频通信平台。基于先进的AI技术和3D成像,将2D视频流转换为逼真的3D效果,让远程通话更自然、更直观。用户能像面对面一样进行眼神交流和读懂细微表情,增强沟通效果。Google Beam支持实时语音翻译,打破语言障碍,让全球用户无缝交流。平台基于Google Cloud的强大支持,具备企业级可靠性,支持无缝集成到现有工作流程中。 Google Be
通义万相AI视频是阿里推出的一款完全免费的AI视频生成工具,支持文生视频和图生视频两种方式,可以根据用户提供的文字提示词或图片,自动创作出具有影视级画面质感的高清视频(最长6秒)。通义万相AI视频支持多种艺术风格,包括但不限于古风、科幻、动画等,并且特别优化了对中式元素的理解和表现。通义万相AI视频能处理多语言输入,支持“灵感扩写”功能,一键帮用户完善提示词,还自带“音频生成”功能,视频生成自带音
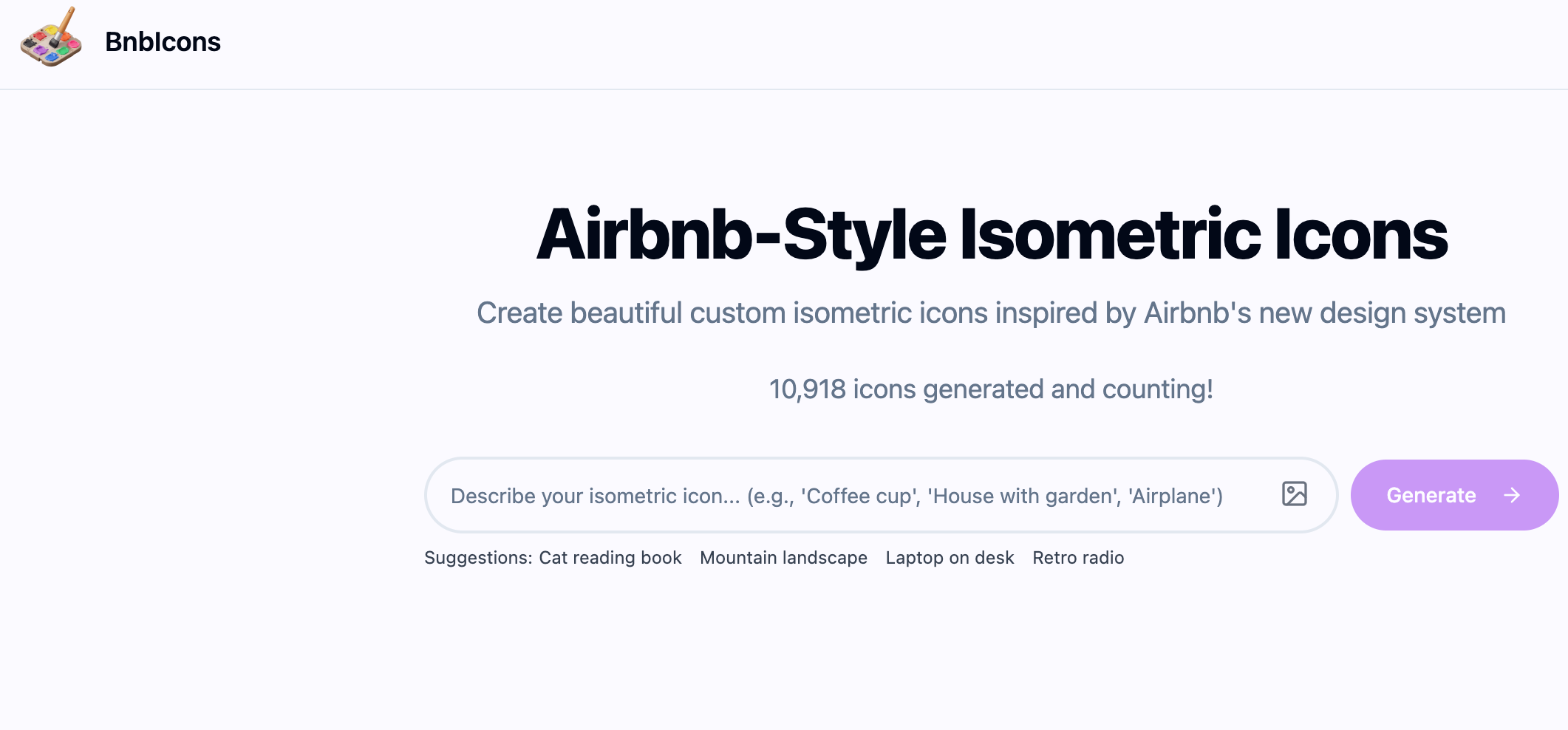
BnbIcons是AI驱动的图标生成工具,能创建类似Airbnb风格的等轴测图标。用户只需输入文字描述或上传参考图片,AI能生成符合要求的图标。提供464+个预制图标,涵盖多种类别和风格,可快速找到所需图标。用户可以批量创建图标,输入一系列类别,可生成整套匹配的图标,节省设计时间。 BnbIcons的主要功能 AI辅助图标生成:通过AI技术,根据用户输入的文本描述或上传的参考图片,快速
3DTown 是哥伦比亚大学联合Cybever AI等机构推出的从单张俯视图生成3D城镇场景框架。框架基于区域化生成和空间感知的3D修复技术,将输入图像分解为重叠区域,基于预训练的3D对象生成器分别生成每个区域的3D内容,基于掩码修正流修复过程填补缺失的几何结构,同时保持结构连续性。3DTown 支持生成具有高几何质量和纹理保真度的连贯3D场景,在多种风格的场景生成中表现出色,优于现有的先进方法。
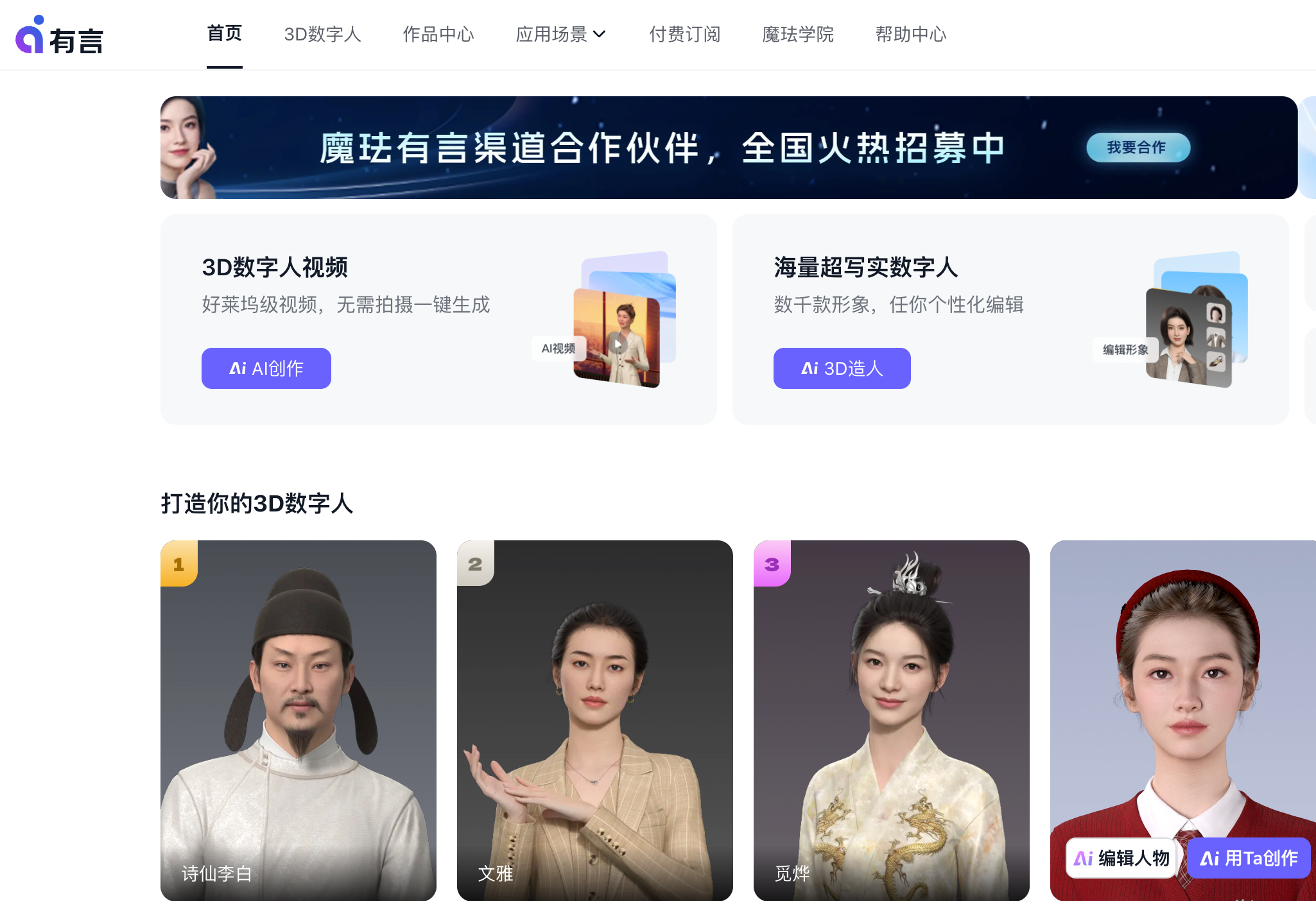
有言是由魔珐科技推出的一个一站式AIGC视频创作和3D数字人生成平台,通过提供海量超写实3D虚拟人角色,帮助用户无需真人出镜即可制作视频。该平台基于魔珐自研的AIGC技术,支持用户输入文字快速生成3D内容,并提供自定义编辑、字幕、动效、背景音乐等后期包装功能,简化视频制作流程,让创作变得高效而有趣。 有言的主要功能 一站式服务:有言整合了从内容生成到后期制作的全套流程,为用户提供了从开始到
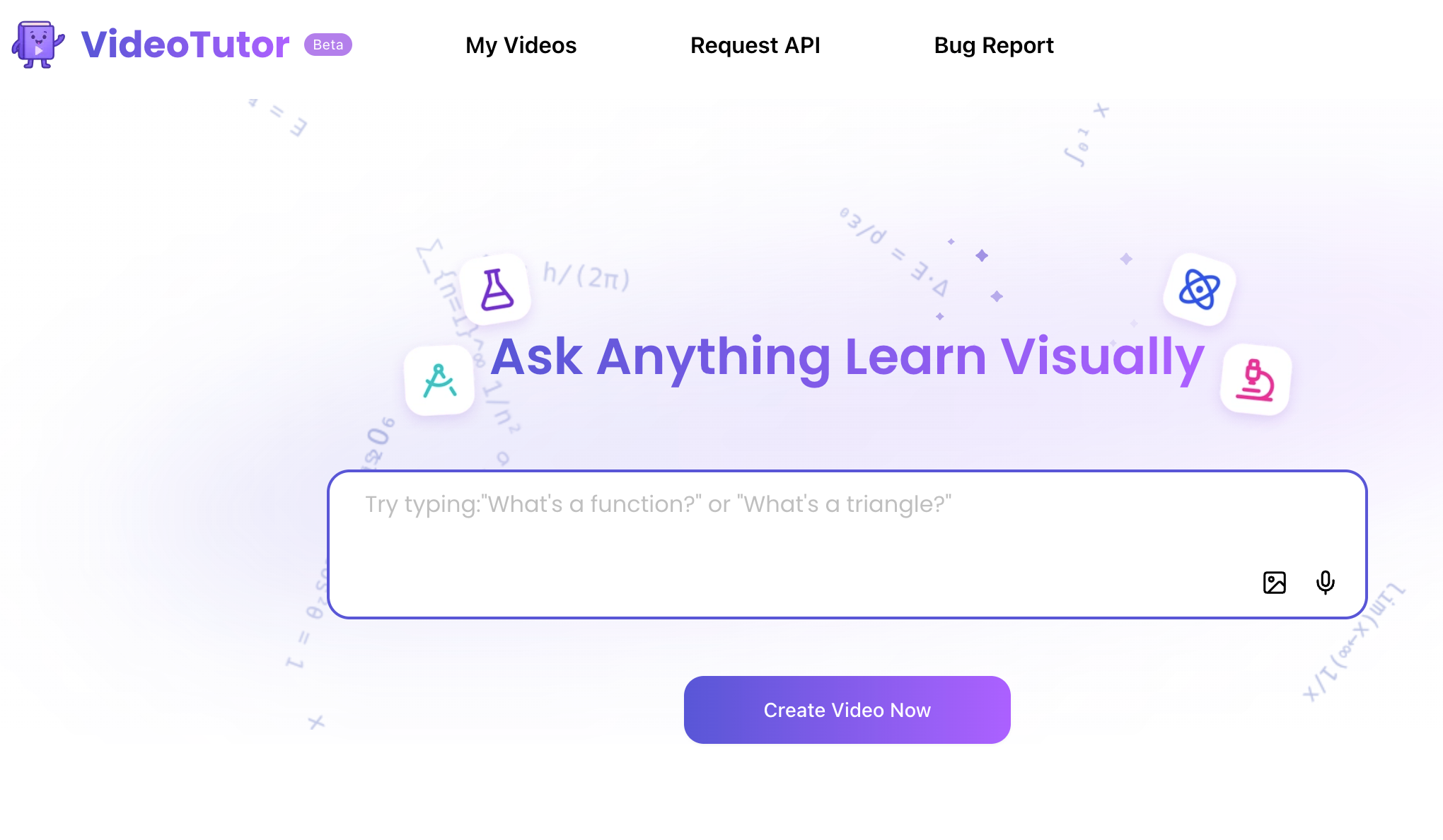
VideoTutor是AI教育辅助工具,生成动画讲解视频,帮助学生理解知识点和解题过程。VideoTutor支持SAT数学、AP数学、STEM知识和语言学习等学科领域。用户用文字、截图或语音输入问题,系统自动生成包含动画和语音说明的讲解视频。工具提供个性化学习内容,支持24小时在线学习,适合家长、学生和教师使用,在SAT数学备考方面表现出色。 VideoTutor的主要功能 AI视频生成:
Cartwheel 是 AI 3D 动画生成平台,基于文本到动画(Text-to-Motion)技术,让用户仅需输入文本描述,快速生成高质量的 3D 角色动画。平台结合深度学习模型与传统动画技术,支持动作捕捉、自动化运动合成,与主流 3D 软件无缝集成。Cartwheel 的目标是简化 3D 动画制作流程,帮助动画师和艺术家节省时间,专注于创造性工作。 Cartwheel的主要功能 文本驱
幻舟AI是一站式AI短片创作平台,支持批量生成广告片、宣传片、动画片等。基于Midjourney、Runway等全球领先的AI模型,实现剧本创作、角色设计、分镜生成及视频制作的全流程服务。平台支持多种模型切换,满足不同风格和场景需求。幻舟AI高效整合创作资源,简化操作流程,提升创作效率,是影视创作者的有力工具。 幻舟AI的主要功能 剧本创作:自动生成故事剧本和分镜图,支持自定义编辑。 角
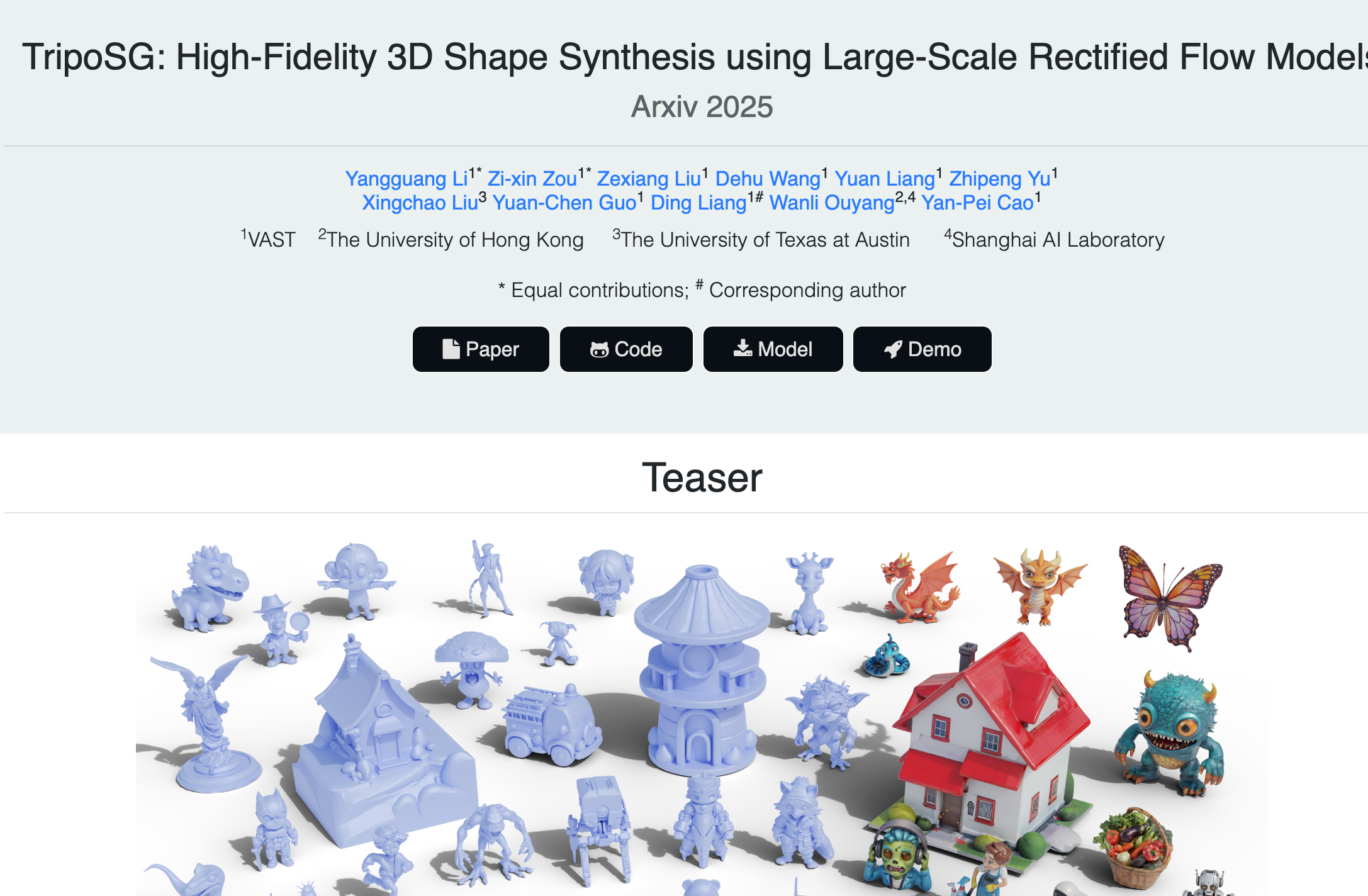
TripoSG 是 VAST-AI-Research 团队推出的基于大规模修正流(Rectified Flow, RF)模型的高保真 3D 形状合成技术, 通过大规模修正流变换器架构、混合监督训练策略以及高质量数据集,实现了从单张输入图像到高保真 3D 网格模型的生成。TripoSG 在多个基准测试中表现出色,生成的 3D 模型具有更高的细节和更好的输入条件对齐。 TripoSG的主要功能
Playmate是广州趣丸科技团队推出的人脸动画生成框架。框架基于3D隐式空间引导扩散模型,用双阶段训练框架,根据音频和指令精准控制人物的表情和头部姿态,生成高质量的动态肖像视频。Playmate基于运动解耦模块和情感控制模块,实现对生成视频的精细控制,显著提升视频质量和情感表达的灵活性。Playmate在音频驱动肖像动画领域取得重大进展,提供对情感和姿态的精细控制,能生成多种风格的动态肖像,具有
Meta 又有新的动作,推出基于视频训练的世界模型 V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。 Meta 表示,他们在追求高级机器智能(AMI)的目标过程中,关键在于开发出能像人类一样认知世界、规划陌生任务执行方案,并高效适应不断变化环境的
ChatPs 是创新的 Photoshop 插件,通过自然语言交互简化图像编辑流程。无需掌握复杂的 Photoshop 操作技巧或快捷键,只需用日常语言下达指令,ChatPs 可精准识别执行任务,例如选中图层、翻译文本、抠图、调整图像等。针对设计场景进行了专门训练,能满足从新手到资深设计师的多元需求,大幅减少重复性操作,提升设计效率。ChatPs 覆盖了 Photoshop 的核心功能,结合 AI
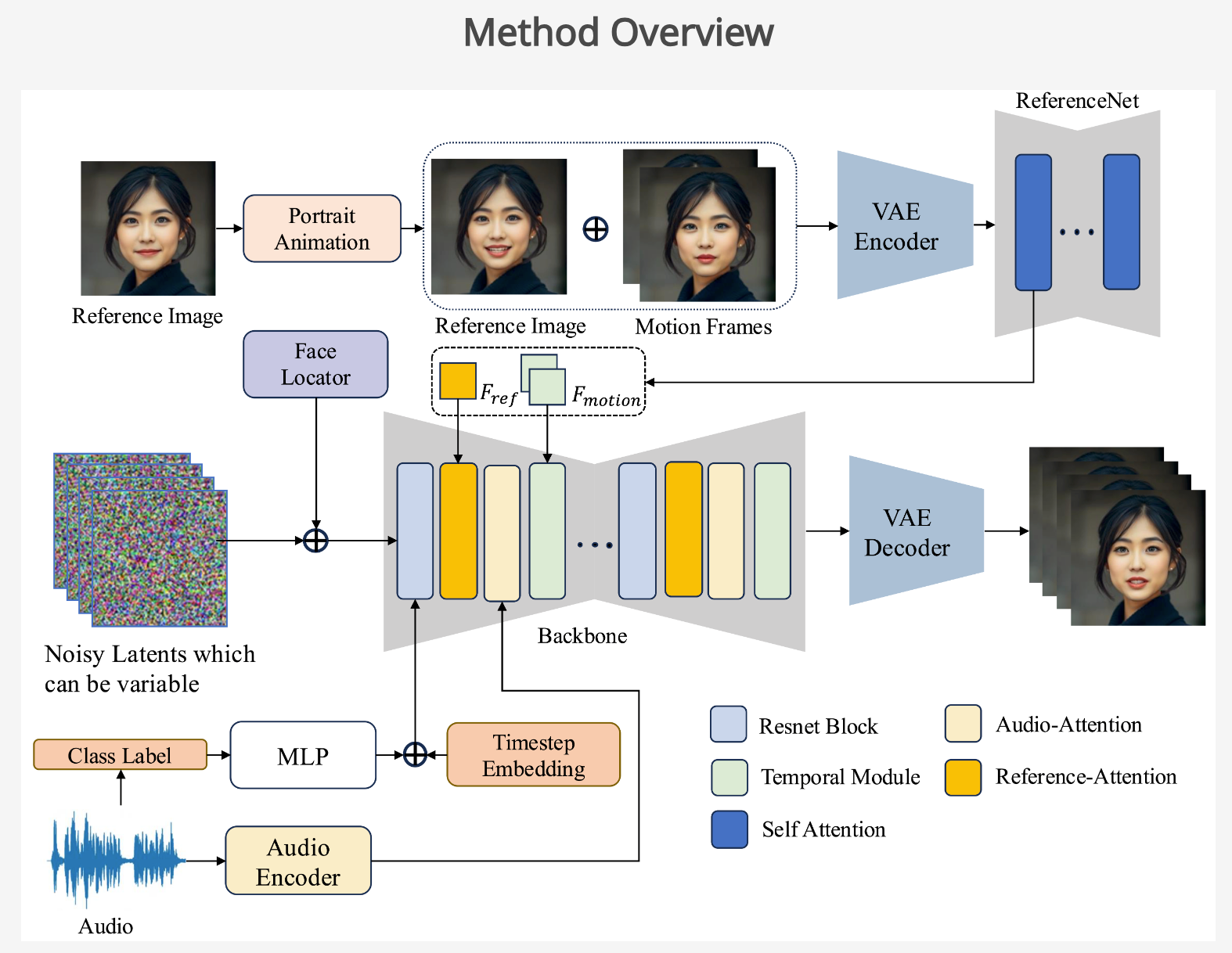
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
MAGREF(Masked Guidance for Any‑Reference Video Generation)是字节跳动推出的多主体视频生成框架。MAGREF仅需一张参考图像和文本提示,能生成高质量、主体一致的视频,支持单人、多人及人物与物体、背景的复杂交互场景。基于区域感知动态掩码和像素级通道拼接机制,MAGREF能精准复刻身份特征,保持视频中人物、物体和背景的协调性与一致性,适用内容创作
Seaweed APT2是字节跳动推出的创新的AI视频生成模型,通过自回归对抗后训练(AAPT)技术,将双向扩散模型转化为单向自回归生成器,实现高效、高质量的视频生成。模型能在单次网络前向评估(1NFE)中生成包含多帧视频的潜空间帧,显著降低了计算复杂性,通过输入回收机制和键值缓存(KV Cache)技术,支持长时间视频生成,解决了传统模型在长视频生成中常见的动作漂移和物体变形问题。能在单块GPU
EmbodiedGen 是用于具身智能(Embodied AI)应用的生成式 3D 世界引擎和工具包。能快速生成高质量、低成本且物理属性合理的 3D 资产和交互环境,帮助研究人员和开发者构建具身智能体的测试环境。EmbodiedGen 包含多个模块,如从图像或文本生成 3D 模型、纹理生成、关节物体生成、场景和布局生成等,支持从简单物体到复杂场景的创建。生成的 3D 资产可以直接用于机器人仿真和
VFX8 是一站式 AI 制片工场,基于人工智能技术赋能影视制作全流程。用户只需输入一个创意想法,VFX8 能提供从前期策划、分镜头脚本生成、角色设计到视频生成的全流程服务。具备智能分镜制作功能,能批量生成电影级分镜头脚本,确保角色形象的一致性;支持全风格的影视角色设计,满足不同风格需求。VFX8 配备长篇剧集视觉资产管理系统,帮助创作者高效管理剧集的视觉元素,确保风格统一。 VFX8的主要功能
Dive3D是北京大学和小红书公司合作推出的文本到3D生成框架。框架基于分数的匹配(Score Implicit Matching,SIM)损失替代传统的KL散度目标,有效避免模式坍塌问题,显著提升3D生成内容的多样性。Dive3D在文本对齐、人类偏好和视觉保真度方面表现出色,在GPTEval3D基准测试中取得优异的定量结果,证明了在生成高质量、多样化3D资产方面的强大能力。 Dive3D的项目
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
FairyGen 是大湾区大学推出的动画故事视频生成框架,支持从单个手绘角色草图出发,生成具有连贯叙事和一致风格的动画故事视频。框架借助多模态大型语言模型(MLLM)进行故事规划,基于风格传播适配器将角色的视觉风格应用到背景中,用 3D Agent重建角色生成真实的运动序列,基于两阶段运动适配器优化视频动画的连贯性与自然度。FairyGen 在风格一致性、叙事连贯性和运动质量方面表现出色,为个性化
圆周旅迹是专注于旅行规划的智能应用,帮助用户高效、便捷地安排旅行行程。通过简洁直观的界面设计和强大的AI功能,让用户能快速输入目的地、时间等信息,自动生成合理且个性化的行程安排。支持从社交平台一键导入链接、文字或图片,快速生成同款行程;提供3D全景地图导航和路径拖拽功能,帮助用户直观规划路线;方便旅行伙伴共同编辑行程并实时更新。圆周旅迹整合了实时交通数据,支持离线地图缓存,确保用户在无网络环境下也
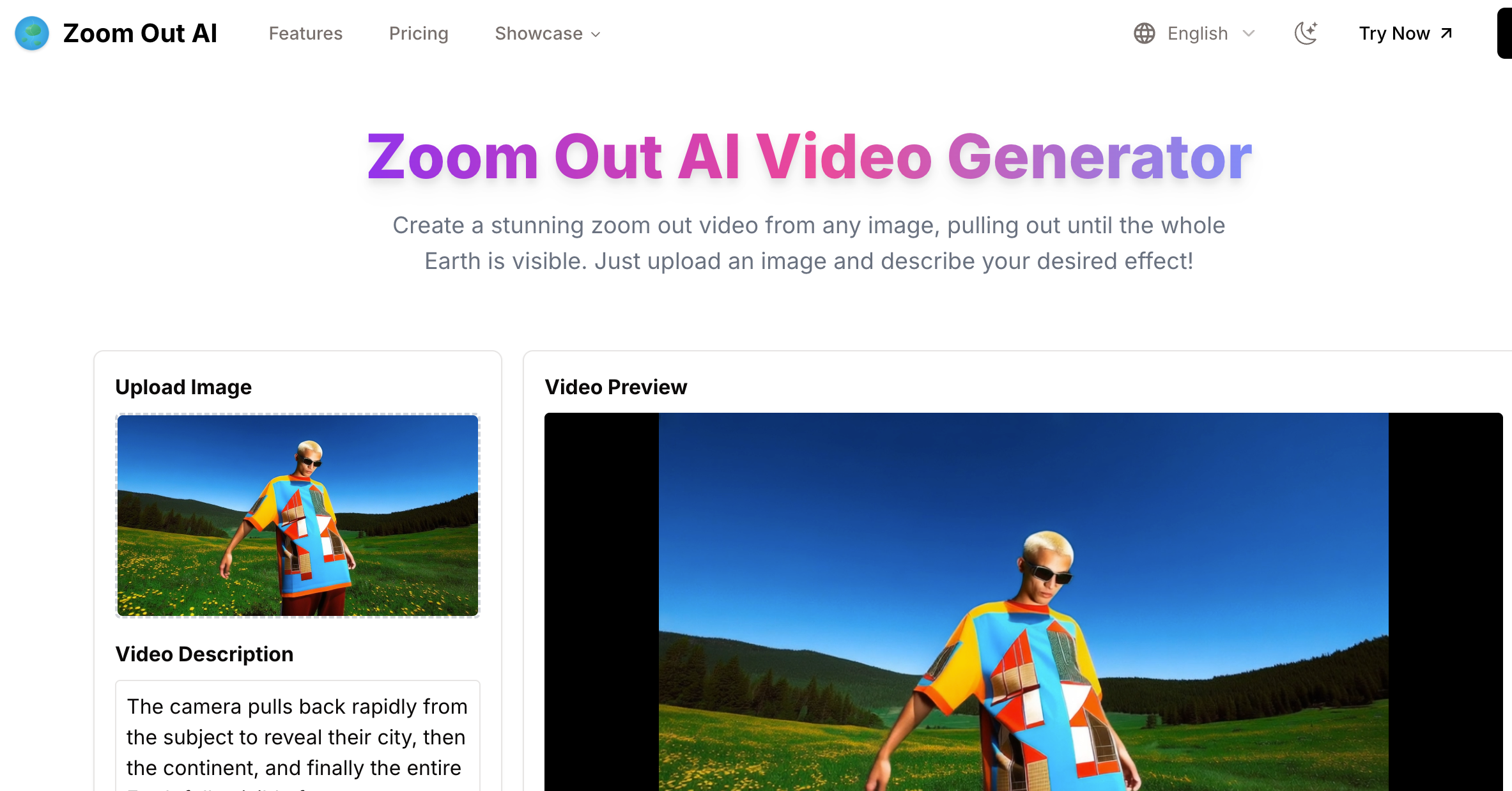
zoomoutai.pro 与众不同,因为它不仅仅是把图片放大。它会智能地猜测并补充缺失的部分,让图片看起来更清晰、更真实,而不是模糊或拉伸变形。它在浏览器里就能使用,不需要安装任何软件。很多工具只会把图片放大,但这个工具还能修复细节,让图片更好看。 Zoom Out AI 是一款免费工具,可将任何图像转换为缩小视频,直至看到地球。非常适合演示、创意项目和娱乐!无需下载或注册。
只显示前20页数据,更多请搜索
Showing 385 to 408 of 417 results