关键词 "3D 建模" 的搜索结果, 共 24 条, 只显示前 480 条
Lovart 全球首个设计 Agent 体验 Lovart 的三个特点: 一、全链路设计和执行,一句话搞定 以前的文生图工具,它们所提供的任务是“生成图片”这一环。 而设计 Agent,则像一位“设计执行官”,覆盖从创意拆解到专业交付的整个视觉流程。 从意图拆解 → 任务链 → 最后成品,一句话全搞定。 单次可以执行上
昆仑万维正式开源(17B+)Matrix-Game大模型,即Matrix-Zero世界模型中的可交互视频生成大模型。Matrix-Game是Matrix系列在交互式世界生成方向的正式落地,也是工业界首个开源的10B+空间智能大模型,它是一个面向游戏世界建模的交互式世界基础模型,专为开放式环境中的高质量生成与精确控制而设计。 空间智能作为AI时代的重要前沿技术,正在重塑我们与虚拟世界的
Step1X-3D是什么 Step1X-3D 是StepFun联合LightIllusions推出的高保真、可控的 3D 资产生成框架。基于严格的数据整理流程,从超过 500 万个 3D 资产中筛选出 200 万个高质量数据,创建标准化的几何和纹理属性数据集。Step1X-3D 支持多模态条件输入,如文本和语义标签,基于低秩自适应(LoRA)微调实现灵活的几何控制。Step1X-3D 推动了 3
WorldMem 是南洋理工大学、北京大学和上海 AI Lab 推出的创新 AI 世界生成模型。模型基于引入记忆机制,解决传统世界生成模型在长时序下缺乏一致性的关键问题。在WorldMem中,智能体在多样化场景中自由探索,生成的世界在视角和位置变化后能保持几何一致性。WorldMem 支持时间一致性建模,模拟动态变化(如物体对环境的影响)。模型在 Minecraft 数据集上进行大规模训练,在真实
Being-M0 基于业界首个百万级动作数据集 MotionLib,用创新的 MotionBook 编码技术,将动作序列转化为二维图像进行高效表示和生成。Being-M0 验证了大数据+大模型在动作生成领域的技术可行性,显著提升动作生成的多样性和语义对齐精度,实现从人体动作到多款人形机器人的高效迁移,为通用动作智能奠定基础。 Being-M0的主要功能 文本驱动动作生成:根据输入的自然语言
MSQA(Multi-modal Situated Question Answering)是大规模多模态情境推理数据集,提升具身AI代理在3D场景中的理解与推理能力。数据集包含251K个问答对,覆盖9个问题类别,基于3D场景图和视觉-语言模型在真实世界3D场景中收集。MSQA用文本、图像和点云的交错多模态输入,减少单模态输入的歧义。引入MSNN(Multi-modal Next-step Navi
DICE-Talk是复旦大学联合腾讯优图实验室推出的新颖情感化动态肖像生成框架,支持生成具有生动情感表达且保持身份一致性的动态肖像视频。DICE-Talk引入情感关联增强模块,基于情感库捕获不同情感之间的关系,提升情感生成的准确性和多样性。框架设计情感判别目标,基于情感分类确保生成过程中的情感一致性。在MEAD和HDTF数据集上的实验表明,DICE-Talk在情感准确性、对口型和视觉质量方面均优于
Sketch2Anim 是爱丁堡大学联合Snap Research、东北大学推出的自动化框架,能将2D草图故事板直接转换为高质量的3D动画。基于条件运动合成技术,用3D关键姿势、关节轨迹和动作词精确控制动画的生成。框架包含两个核心模块,多条件运动生成器和2D、3D神经映射器。Sketch2Anim能生成自然流畅的3D动画,支持交互式编辑,极大地提高动画制作的效率和灵活性。 Sketch2Anim
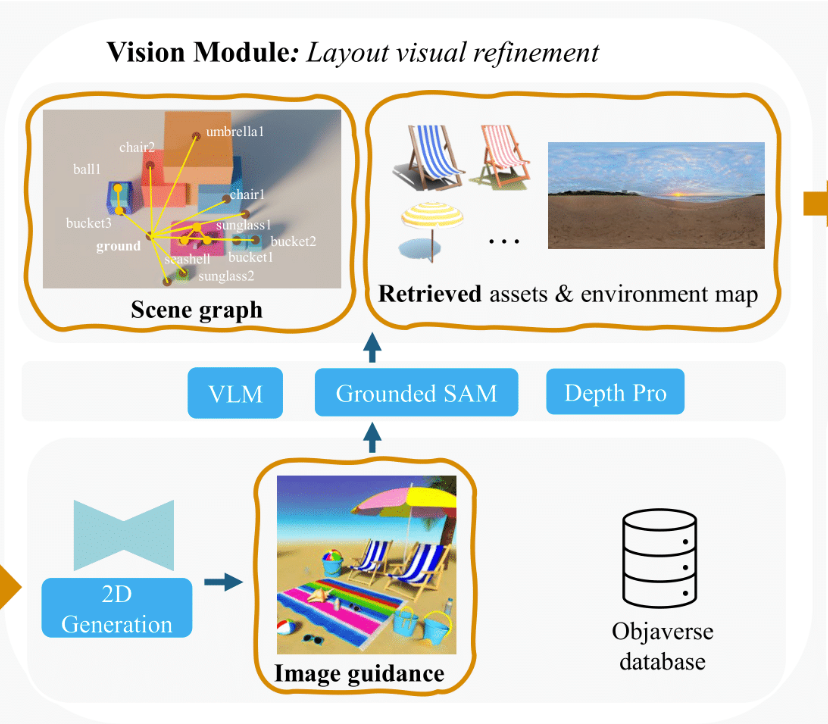
Scenethesis 是 NVIDIA 推出的创新框架,用在从文本生成交互式 3D 场景。框架结合大型语言模型(LLM)和视觉感知技术,基于多阶段流程实现高效生成,用 LLM 进行粗略布局规划,基于视觉模块细化布局生成图像指导,用优化模块调整物体姿态确保物理合理性,基于判断模块验证场景的空间连贯性。Scenethesis 能生成多样化的室内外场景,具有高度的真实感和物理合理性,广泛应用在虚拟内容
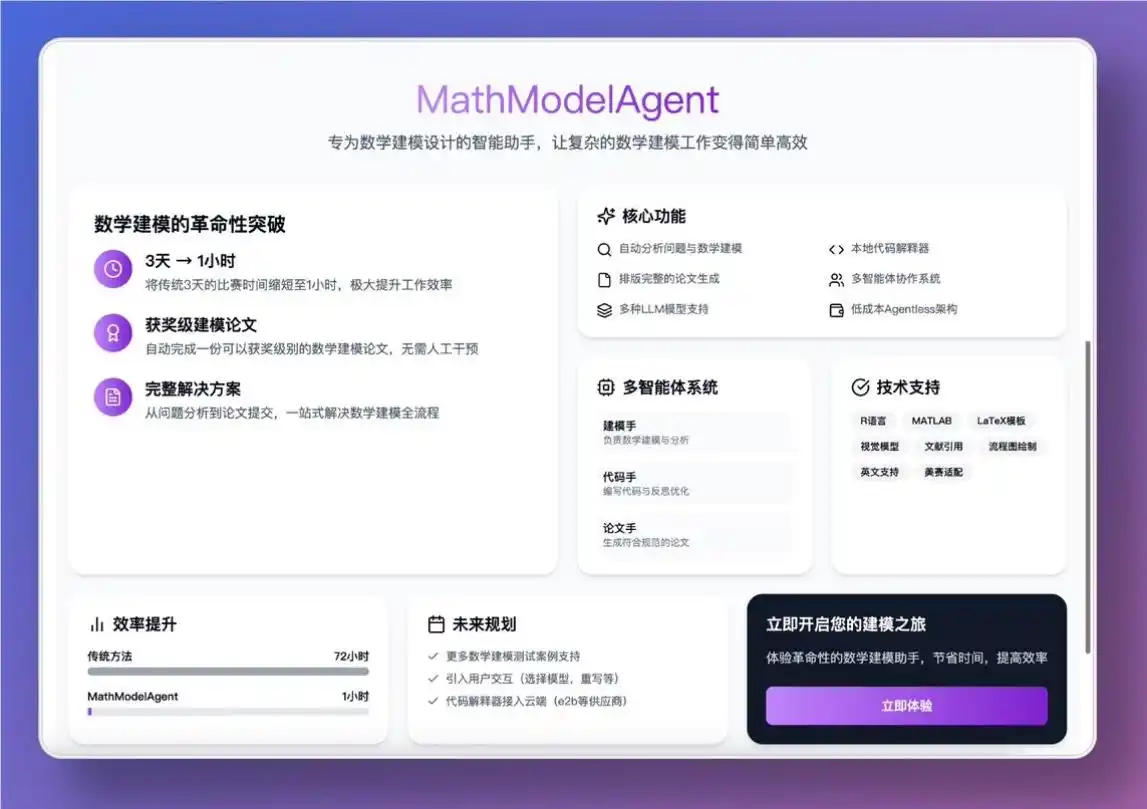
一款开源MathModelAgent的AI助手,专为数学建模设计的智能工具,能够自动完成从问题分析、模型构建、代码编写到论文撰写的全流程,展现了AI在学术与技术领域的深远潜力。 MathModelAgent:数学建模的革命性助手 MathModelAgent是一个多智能体协作系统,集成了多个专业模块,包括负责数学建模的“建模手”、代码编写与调试的“代码手”以及论
专长:分子建模与药物设计。Schrödinger 将基于物理的计算化学与机器学习相结合,以推动药物研发。其先进的分子建模软件不仅供公司内部使用,也供武田制药和百时美施贵宝等合作伙伴使用。Schrödinger 拥有不断增长的内部项目管线,包括肿瘤学和神经病学领域的在研项目,并因突破计算药物设计的界限而备受赞誉。 在比尔及梅琳达·盖茨基金会1000万美元的资助下,Schrödinger于8月开始扩
专长:人工智能驱动的生物标志物发现。Genialis 利用计算生物学和机器学习来识别精准医疗的生物标志物。他们在免疫肿瘤学和中枢神经系统疾病领域的工作支持药物研发流程,并提高临床试验的成功率。 RNA生物标记公司Genialis正在创造一个能为患者、患者家庭和社区提供最佳医疗服务的世界。ResponderID™是Genialis的机器学习驱动的疾病建模框架,它提供可操作的生物标志物,并对新药进行
Model Medicines 拥有人工智能药物研发公司中公开研发管线规模最大的公司之一。该公司拥有 192 种化合物,针对 26 个治疗靶点。所有化合物均通过该公司的 GALILEO 平台发现,该平台旨在研究 3D 蛋白质结构中相互作用的原子“群”。 今年4月,Model及其合作伙伴的研究团队发布了一份预印本,确定了RdRp Thumb-1位点,该位点代表了正义单链RNA病毒中一个潜在的可用药
唯信(Wecomput™)致力于用计算技术驱动创新药研发、造福人类健康。 Wecomput融合人工智能、生物物理、高性能计算、生成生物学等技术,打造了独具特色的药物分子生成、设计与模拟平台,并致力于革新传统药物发现方式,驱动蛋白质、抗体、mRNA等创新药物的研发进程。核心团队成员来自国际知名AI制药公司、头部药企、知名互联网公司、985高校,在制药、生命科学、人工智能、软件开发等交叉领域有丰富的
Mujoco(Multi-Joint dynamics with Contact)是一款用于机器人学、生物力学等领域的高性能物理仿真引擎,其核心功能包括动力学模拟、接触力建模及多关节系统仿真。该工具提供直观的操作界面、丰富的物理参数配置以及灵活的约束条件设置,适用于复杂机械系统或生物运动的模拟分析。以下从操作功能、仿真交互机制、核心术语与参数三个维度展开说明。 MuJoCo是“多关节接触动力学”
AnimeGamer 是基于多模态大型语言模型(MLLM)构建的,可以生成动态动画镜头和角色状态更新,为用户提供无尽的动漫生活体验。它允许用户通过开放式语言指令与动漫角色互动,创建独特的冒险故事。该产品的主要优点包括:动态生成与角色交互的动画,能够在不同动漫之间创建交互,丰富的游戏状态预测等。 快速入门 🔮 环境设置 要设置推理环境,您
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
ScrapeGraphAI 是基于大型语言模型(LLM)驱动的智能网络爬虫工具包,专注于从各类网站和HTML内容中高效提取结构化数据。具备三大核心功能:SmartScraper可根据用户提示精准抓取网页中的结构化信息;SearchScraper基于AI驱动的搜索技术从搜索引擎结果中提取关键信息;Markdownify可将网页内容快速转换为整洁的Markdown格式,方便后续处理和存储。 Sc
Aurora是微软研究院推出的13亿参数的大气基础模型,基于从海量大气数据中提取有价值信息,用在预测全球天气模式、空气污染和海洋波浪等大气过程。模型用预训练和微调的架构,处理不同分辨率和压力水平的数据。Aurora在多个预测任务中表现出色,包括高分辨率天气预测、空气污染预测和热带气旋轨迹预测,计算速度比传统数值天气模型快约5000倍。模型提高了预测精度,降低计算成本,为应对气候变化和极端天气事件提
HRAvatar是清华大学联合IDEA团队推出的单目视频重建技术,支持从普通单目视频中生成高质量、可重光照的3D头像。HRAvatar用可学习的形变基和线性蒙皮技术,基于精准的表情编码器减少追踪误差,提升重建质量。HRAvatar将头像外观分解为反照率、粗糙度和菲涅尔反射等属性,结合物理渲染模型,实现真实的重光照效果。HRAvatar在多个指标上优于现有方法,支持实时渲染(约155 FPS),为数
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
Google Beam是谷歌推出的AI驱动的3D视频通信平台。基于先进的AI技术和3D成像,将2D视频流转换为逼真的3D效果,让远程通话更自然、更直观。用户能像面对面一样进行眼神交流和读懂细微表情,增强沟通效果。Google Beam支持实时语音翻译,打破语言障碍,让全球用户无缝交流。平台基于Google Cloud的强大支持,具备企业级可靠性,支持无缝集成到现有工作流程中。 Google Be
通义万相AI视频是阿里推出的一款完全免费的AI视频生成工具,支持文生视频和图生视频两种方式,可以根据用户提供的文字提示词或图片,自动创作出具有影视级画面质感的高清视频(最长6秒)。通义万相AI视频支持多种艺术风格,包括但不限于古风、科幻、动画等,并且特别优化了对中式元素的理解和表现。通义万相AI视频能处理多语言输入,支持“灵感扩写”功能,一键帮用户完善提示词,还自带“音频生成”功能,视频生成自带音
3DTown 是哥伦比亚大学联合Cybever AI等机构推出的从单张俯视图生成3D城镇场景框架。框架基于区域化生成和空间感知的3D修复技术,将输入图像分解为重叠区域,基于预训练的3D对象生成器分别生成每个区域的3D内容,基于掩码修正流修复过程填补缺失的几何结构,同时保持结构连续性。3DTown 支持生成具有高几何质量和纹理保真度的连贯3D场景,在多种风格的场景生成中表现出色,优于现有的先进方法。
只显示前20页数据,更多请搜索
Showing 217 to 240 of 279 results