关键词 "3D avatars" 的搜索结果, 共 22 条, 只显示前 480 条
ChatPs 是创新的 Photoshop 插件,通过自然语言交互简化图像编辑流程。无需掌握复杂的 Photoshop 操作技巧或快捷键,只需用日常语言下达指令,ChatPs 可精准识别执行任务,例如选中图层、翻译文本、抠图、调整图像等。针对设计场景进行了专门训练,能满足从新手到资深设计师的多元需求,大幅减少重复性操作,提升设计效率。ChatPs 覆盖了 Photoshop 的核心功能,结合 AI
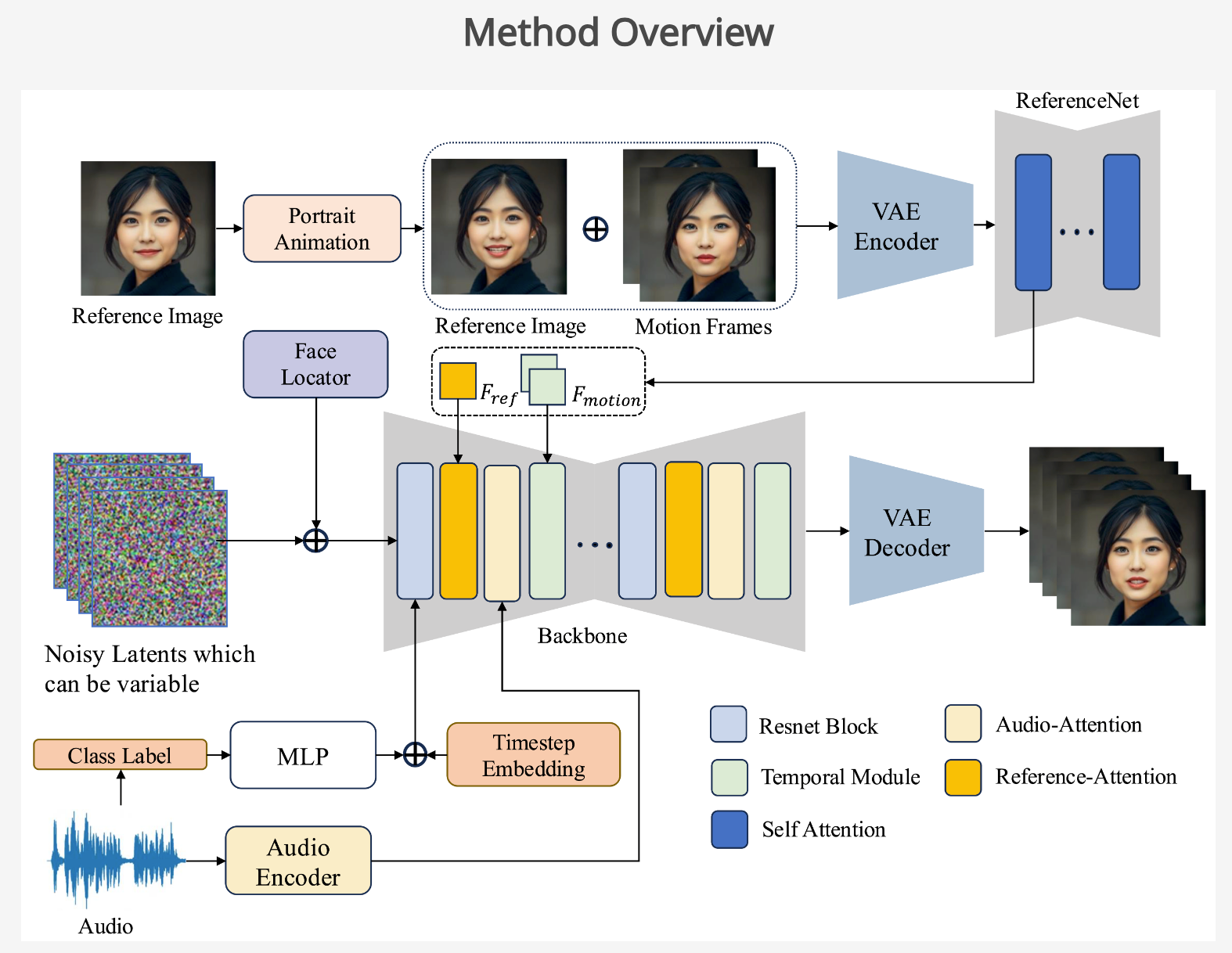
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
Seaweed APT2是字节跳动推出的创新的AI视频生成模型,通过自回归对抗后训练(AAPT)技术,将双向扩散模型转化为单向自回归生成器,实现高效、高质量的视频生成。模型能在单次网络前向评估(1NFE)中生成包含多帧视频的潜空间帧,显著降低了计算复杂性,通过输入回收机制和键值缓存(KV Cache)技术,支持长时间视频生成,解决了传统模型在长视频生成中常见的动作漂移和物体变形问题。能在单块GPU
EmbodiedGen 是用于具身智能(Embodied AI)应用的生成式 3D 世界引擎和工具包。能快速生成高质量、低成本且物理属性合理的 3D 资产和交互环境,帮助研究人员和开发者构建具身智能体的测试环境。EmbodiedGen 包含多个模块,如从图像或文本生成 3D 模型、纹理生成、关节物体生成、场景和布局生成等,支持从简单物体到复杂场景的创建。生成的 3D 资产可以直接用于机器人仿真和
Dive3D是北京大学和小红书公司合作推出的文本到3D生成框架。框架基于分数的匹配(Score Implicit Matching,SIM)损失替代传统的KL散度目标,有效避免模式坍塌问题,显著提升3D生成内容的多样性。Dive3D在文本对齐、人类偏好和视觉保真度方面表现出色,在GPTEval3D基准测试中取得优异的定量结果,证明了在生成高质量、多样化3D资产方面的强大能力。 Dive3D的项目
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
FairyGen 是大湾区大学推出的动画故事视频生成框架,支持从单个手绘角色草图出发,生成具有连贯叙事和一致风格的动画故事视频。框架借助多模态大型语言模型(MLLM)进行故事规划,基于风格传播适配器将角色的视觉风格应用到背景中,用 3D Agent重建角色生成真实的运动序列,基于两阶段运动适配器优化视频动画的连贯性与自然度。FairyGen 在风格一致性、叙事连贯性和运动质量方面表现出色,为个性化
圆周旅迹是专注于旅行规划的智能应用,帮助用户高效、便捷地安排旅行行程。通过简洁直观的界面设计和强大的AI功能,让用户能快速输入目的地、时间等信息,自动生成合理且个性化的行程安排。支持从社交平台一键导入链接、文字或图片,快速生成同款行程;提供3D全景地图导航和路径拖拽功能,帮助用户直观规划路线;方便旅行伙伴共同编辑行程并实时更新。圆周旅迹整合了实时交通数据,支持离线地图缓存,确保用户在无网络环境下也
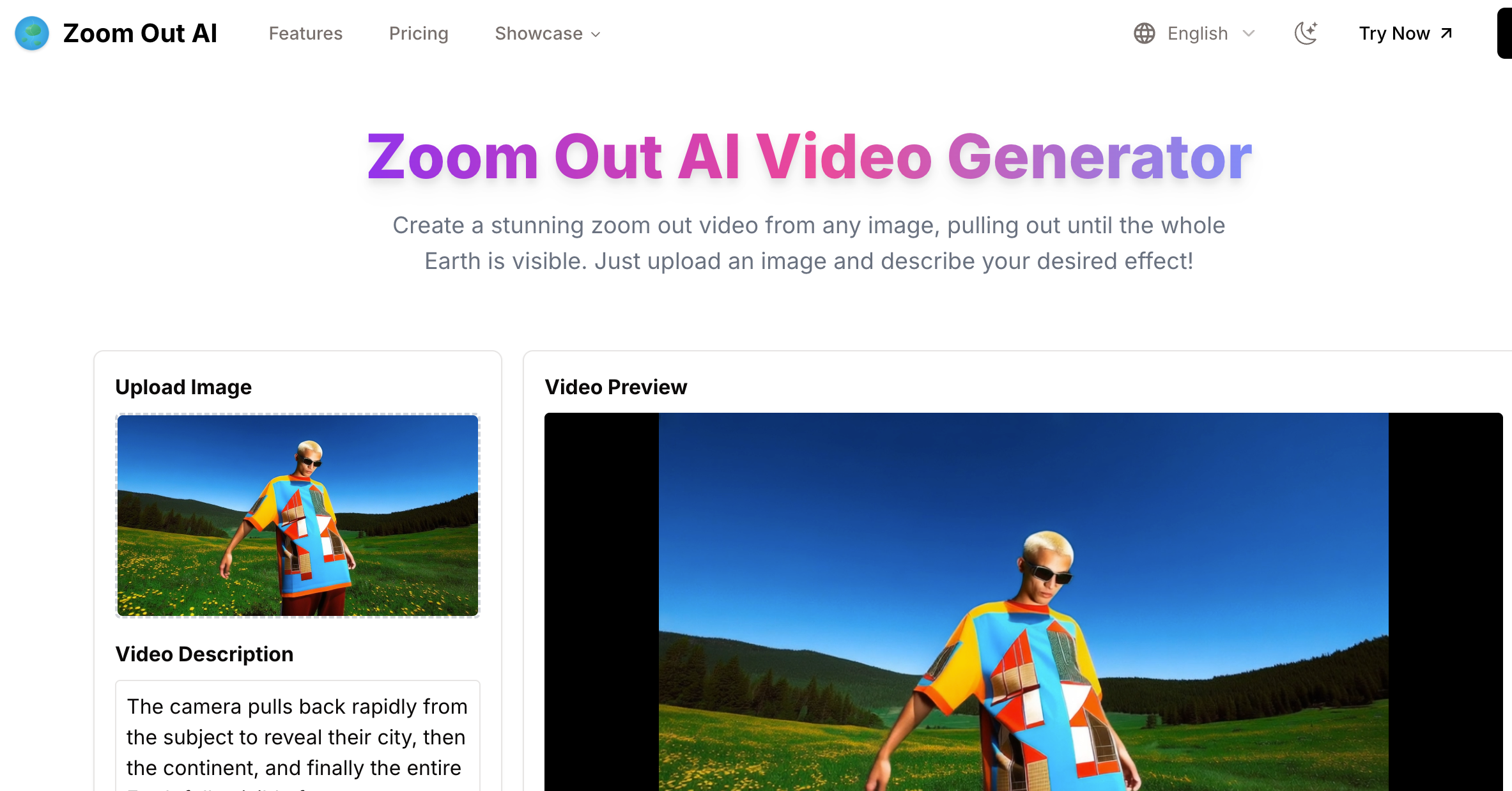
zoomoutai.pro 与众不同,因为它不仅仅是把图片放大。它会智能地猜测并补充缺失的部分,让图片看起来更清晰、更真实,而不是模糊或拉伸变形。它在浏览器里就能使用,不需要安装任何软件。很多工具只会把图片放大,但这个工具还能修复细节,让图片更好看。 Zoom Out AI 是一款免费工具,可将任何图像转换为缩小视频,直至看到地球。非常适合演示、创意项目和娱乐!无需下载或注册。
PhotoG是全球首个内容营销端对端智能体,实现了基于大语言模型智能规划的全模态内容生成与自适应工具调用,致力于构建等同完整传统内容营销团队的全链路智能化。目前产品获得家具、鞋服、珠宝等领域数十家国际化品牌和超过十万海外用户的认可。 仅需一张产品图与自然语言,即可通过多智能体全自动生成基于市场调研和竞争格局的包含营销图片、营销视频、3D模型、营销文案、电商产品详情页、优化标题、描述和 SEO 等内
Ludo.ai 是强大的AI游戏开发平台,能帮助开发者从创意构思到实际开发的全过程。平台提供丰富的功能,包括游戏概念生成、AI 驱动的 3D 资产和图像生成、自定义精灵动画、视频生成、可玩原型制作、市场趋势分析、代码生成等。基于这些工具,开发者能快速生成创意、优化设计、验证想法,加速开发流程。 Ludo.ai的官网地址 官网地址:https://ludo.ai/
TextureNoise 是强大的在线3D纹理生成与编辑工具,帮助用户快速高效地创建高质量纹理。通过快速生成功能,能在几秒钟内生成令人惊叹的纹理,显著提升工作流程效率,节省时间。TextureNoise 提供画笔工具,支持用户对纹理的特定区域进行精确编辑和细节修饰,确保所有编辑和修复无缝融合,保持纹理的整体一致性。支持通用文件格式,与任何数字内容创作软件(如Blender、Maya等)完全兼容。
探索空间智能前沿的最新进展,并创建持久、可导航且可控制的 3D 世界。此外,还将在Marble.worldlabs.ai上推出 Marble 模型的有限访问 Beta 预览版,用户可以在此查看和创建 3D 世界。给定一个图像或文本提示,我们的模型就能生成一个 3D 世界,让你可以随心所欲地探索——没有时间限制、没有变形、没有不一致性。与我们之前的结果相比,我们生成的世界更大、风格更加多样,并且拥有
LatticeWorld 是一个开创性的多模态 3D 世界生成框架,由网易、香港城市大学、北京航空航天大学、清华大学等机构共同推出。它将大语言模型与工业级 3D 渲染引擎 Unreal Engine 5(UE5)相结合,能通过简单的文本描述和视觉指令,快速生成具备高动态环境、真实物理仿真和实时渲染的大规模交互式 3D 世界。与传统手工创作相比,LatticeWorld 的效率提升超过 90 倍,且
WonderPlay:WonderPlay 是由斯坦福大学和犹他大学共同推出的一款创新型框架,它能将一张静态图片和用户自定义的动作,转化为一个动态的 3D 场景。该框架的核心在于其独特的物理模拟与视频生成闭环技术。它首先利用物理求解器模拟粗略的 3D 动态,然后驱动视频生成器合成更逼真的视频,最后用生成的视频来更新 3D 场景。这种“模拟与生成”的循环,确保了最终效果既符合物理规律,又具备极高的视
BodyVisualizer.org is a fitness - focused platform centered on body visualization, boasting advanced 3D technology. Function - wise, it offers real - time 3D body modeling for instant accurate body mo
lynx 是由字节跳动研发的高保真个性化视频生成模型,仅需输入一张人像照片,即可生成身份高度一致的动态视频。该模型基于扩散 transformer(dit)架构构建,并创新性地引入了 id-adapter 和 ref-adapter 两个轻量级适配模块,分别用于精准控制人物身份和精细保留面部细节。lynx 配备专用人脸编码器提取面部特征,结合 x-nemo 技术增强表情表现力,通过 lbm 算法模
RTFM(Real-Time Frame Model)是李飞飞团队推出的实时生成式世界模型。模型能在单块H100 GPU上运行,实时生成3D场景,支持持久交互。RTFM通过观看大量视频数据学习光影、材质和空间关系,将复杂的物理渲染问题转化为基于数据的感知问题。RTFM为每一帧赋予空间坐标,用“上下文腾挪”技术,只关注附近帧生成新画面,实现高效且持久的世界构建。RTFM展示了未来世界模型的潜力,为实
Percify 是强大的 AI 数字人生成平台,专注于创建逼真的虚拟形象(avatar)视频内容。用户上传一张人脸图片和音频,通过简单的文字描述,能生成具有自然表情、精准口型同步和高质量语音的无限时长视频。平台能满足从初学者到专业创作者的需求,支持高清视频导出和语音克隆等功能。Percify 适用艺术家、品牌、游戏开发者等,帮助用户快速生成高质量的虚拟形象和视频内容,提升创作效率。Percify的
TesserAct 是创新的 4D 具身世界模型,能预测 3D 场景随时间的动态演变,响应具身代理的动作。通过训练 RGB-DN(RGB、深度和法线)视频数据来学习,超越了传统的 2D 模型,能将详细的形状、配置和时间变化纳入预测中。TesserAct 的核心优势在于其时空一致性,支持新视角合成,显著提升了策略学习的性能。TesserAct的主要功能4D 场景生成:TesserAct 能生成包含
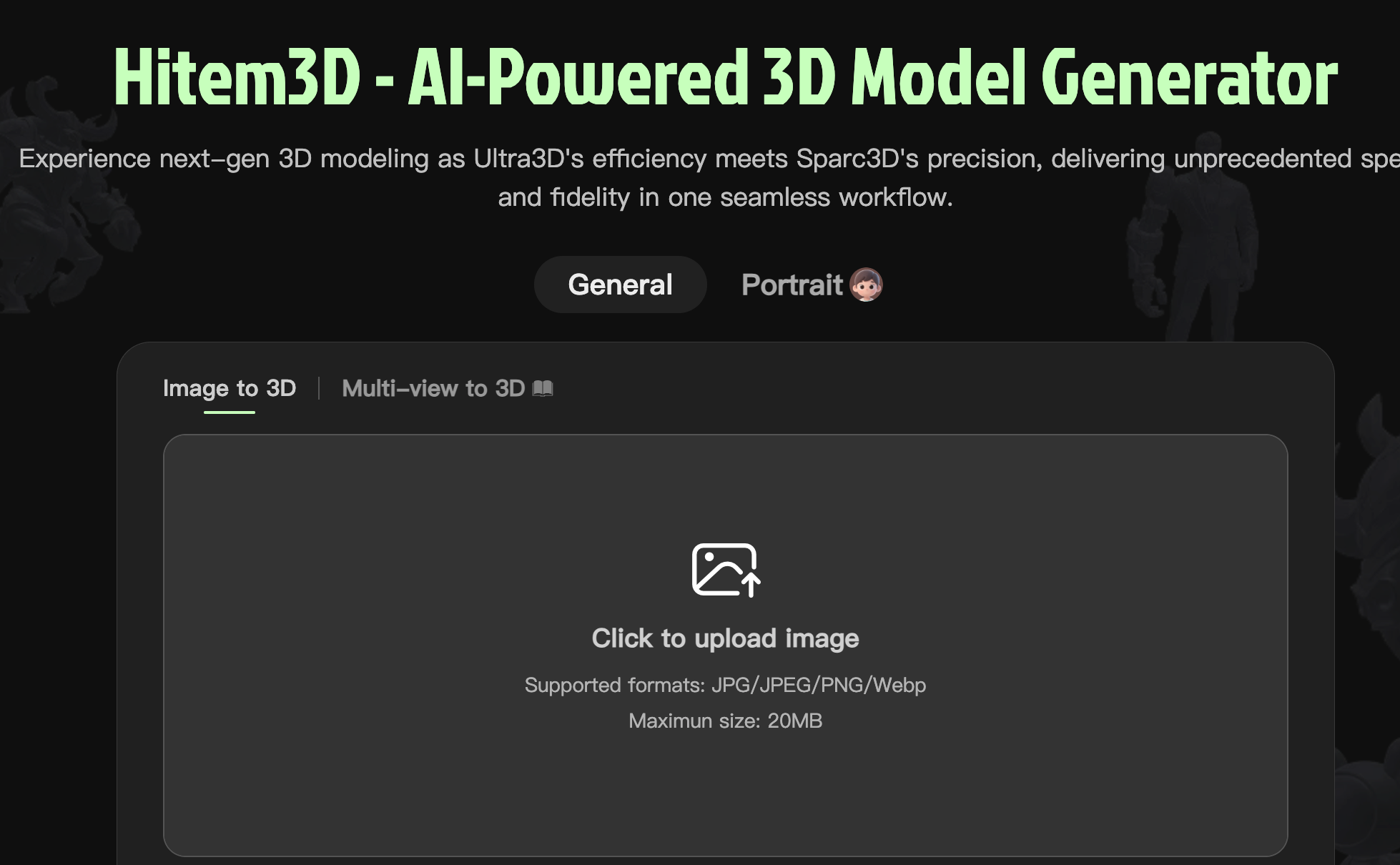
Hitem3D 是 AI 驱动的 3D 模型生成工具。工具结合 ULTRA3D 的高效性和 Sparc3D 的高精度,能将用户上传的图片快速转化为高质量的 3D 模型,适用游戏开发、电商展示、工业设计、教育研究等多种场景。基于先进的技术,Hitem3D 实现了从 2D 到 3D 的无缝转换,为创作者、设计师和开发者提供一个高效、低成本的解决方案,助力快速实现创意和项目落地。Hitem3D的官网地址
Seed3D 1.0 turns images into high-fidelity, physics-ready 3D assets in minutes. DiT-based generation, PBR materials, 6K textures, Omniverse/Unity/USDZ compatibility.
只显示前20页数据,更多请搜索
Showing 337 to 358 of 358 results