关键词 "AI语音识别" 的搜索结果, 共 11 条, 只显示前 480 条
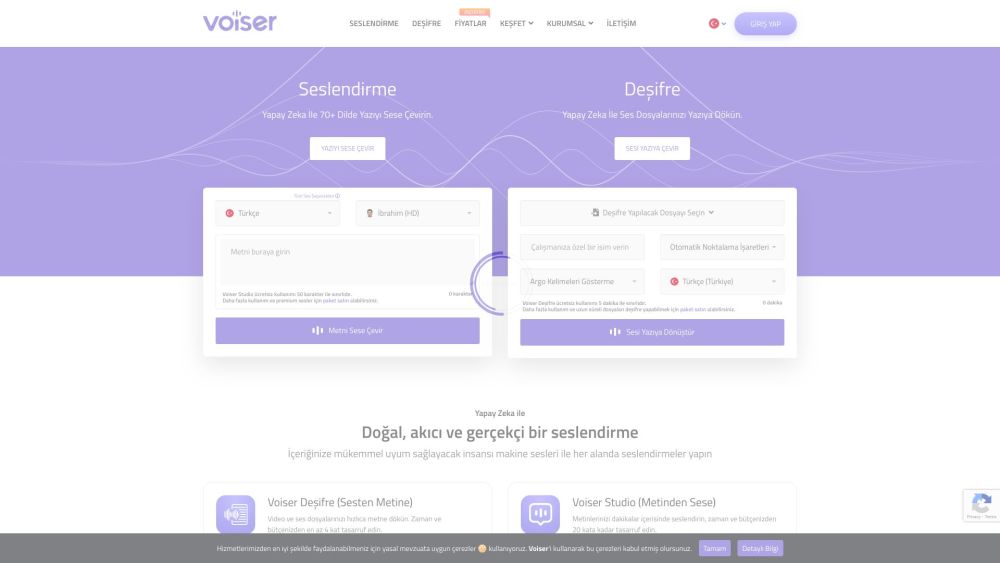
Voiser is an AI program that converts text to speech and speech to text with human-like voices.
AI virtual maths tutor for children aged 5 to 13
Dump your thoughts. Perfect memory.
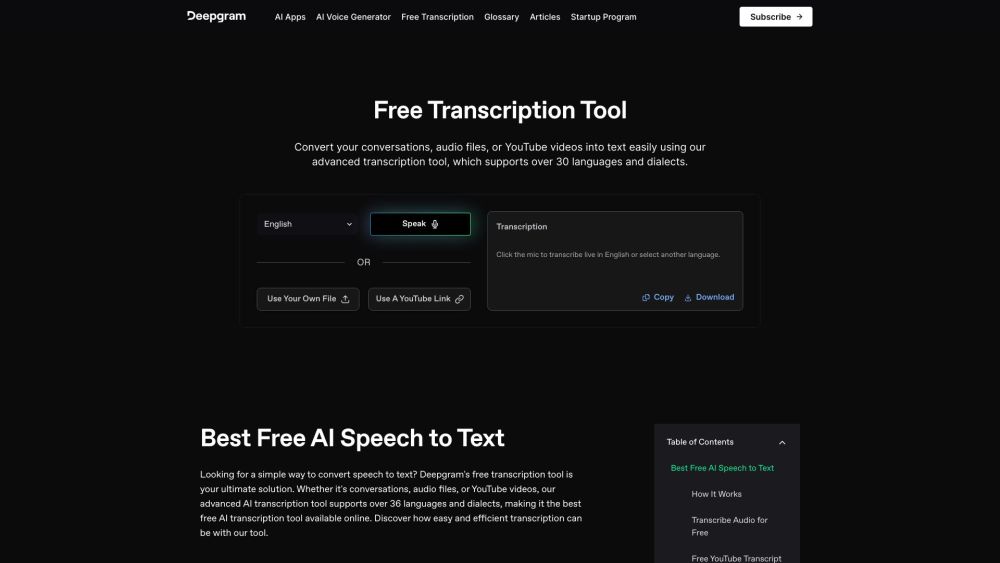
Free AI transcription tool for converting audio to text.
Real-time speech-to-text and text-to-speech APIs powered by Deepgram's voice AI models
Voicemaker® converts text to human-like voices, offering various voice profiles and customization options.
多语言效率工具,支持高精度录音转文本、智能会议总结和自动思维导图生成,覆盖110+语言。办公场景中应用广泛,适合会议和文档处理。
VoiceCanvas 是开源的多语言语音合成平台。基于 AI 技术提供高质量的文字转语音服务,支持超过 50 种语言,集成 OpenAI TTS、AWS Polly 和 MiniMax 等多种语音服务。VoiceCanvas 提供个人声音克隆功能,用户上传几秒音频样本能创建个性化声音。VoiceCanvas适合内容创作者、教育工作者和企业用户,显著提升语音内容制作效率。 VoiceCanvas
OmniAudio 是阿里巴巴通义实验室语音团队推出的从360°视频生成空间音频(FOA)的技术。为虚拟现实和沉浸式娱乐提供更真实的音频体验。通过构建大规模数据集Sphere360,包含超过10.3万个视频片段,涵盖288种音频事件,总时长288小时,为模型训练提供了丰富资源。OmniAudio 的训练分为两个阶段:自监督的coarse-to-fine流匹配预训练,基于大规模非空间音频资源进行自监
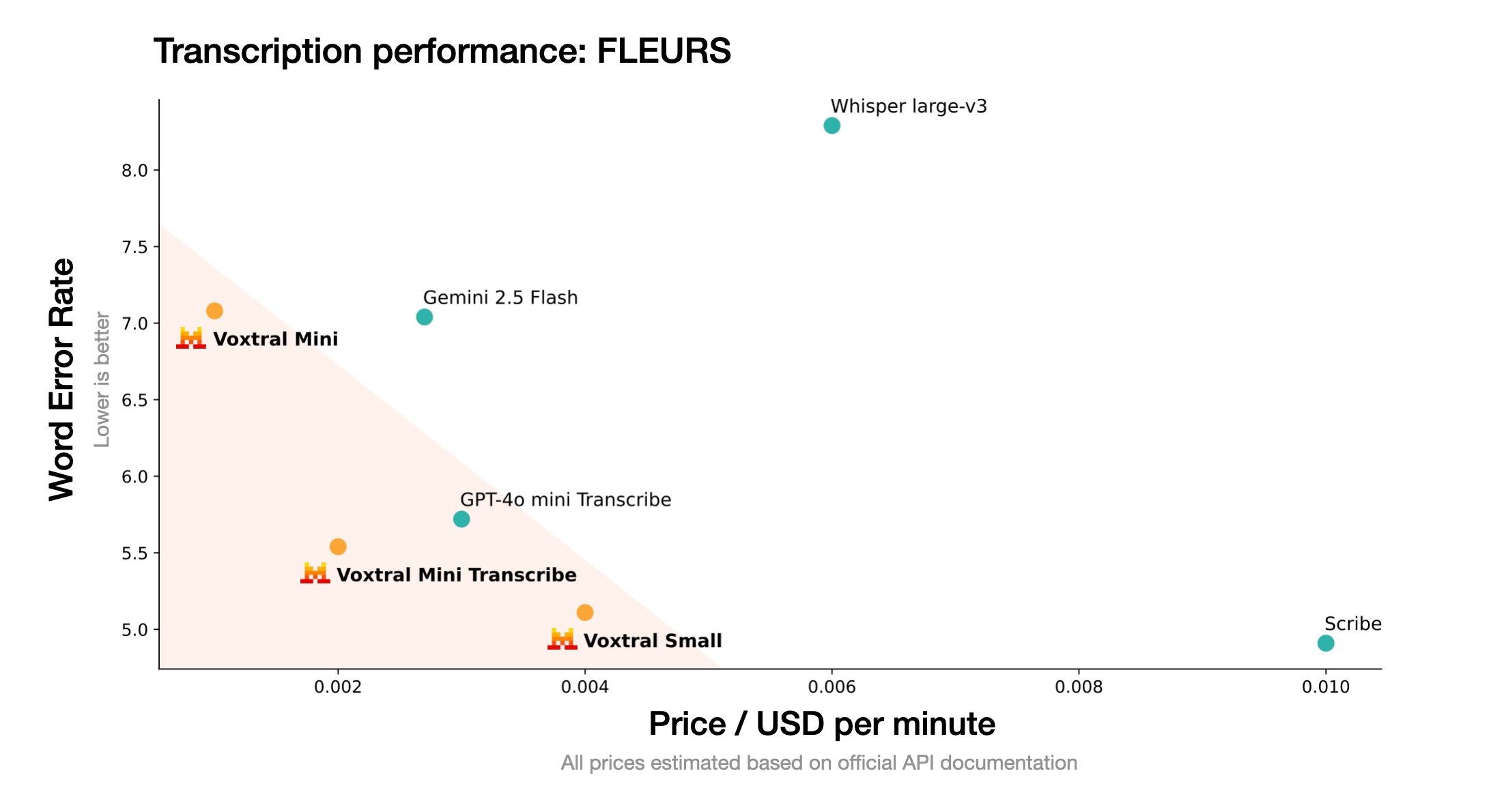
Voxtral 是 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。Voxtral提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音
阿里巴巴推出FunAudio-ASR语音识别大模型,专为解决企业落地难题。模型通过创新的Context增强模块,有效优化了“幻觉”“串语种”等关键问题。在高噪声等复杂场景下,其识别准确率显著提升,幻觉率从78.5%降至10.7%。目前,FunAudio-ASR 已在钉钉的“AI听记”、视频会议、DingTalk A1硬件等多个场景中应用,验证了其在真实企业环境中的稳定性和高精度识别能力,特别是在垂
只显示前20页数据,更多请搜索
Showing 241 to 251 of 251 results