关键词 "CV building" 的搜索结果, 共 24 条, 只显示前 480 条
MCP starter kit for building AI tools with Bun runtime - specialized for interactive quizzes
Building MCP Servers with Google Gemini
The Neuro-Symbolic Autonomy Framework integrates neural, symbolic, and autonomous learning methods into a single, continuously evolving AI agent-building system. This prototype demonstrates the SCMA c
Building MCP client and server for LLM
A Model Context Protocol (MCP) server for querying the CVE-Search API
This implementation follows the official MCP specification, including proper message framing, transport layer implementation, and complete protocol lifecycle management. It provides a foundation for b
This is a quick start guide that provides the basic building blocks to set up a remote Model Context Protocol (MCP) server using Azure Container Apps. The MCP server is built using Node.js and TypeScr
NOT for educational purposes: An MCP server for professional penetration testers including nmap, go/dirbuster, nikto, JtR, wordlist building, and more.
苹果 FastVLM 的模型让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊! 视觉语言模型的 “成长烦恼” 现在的视觉语
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
Seedance 1.0 lite是火山引擎推出的豆包视频生成模型的小参数量版本,支持文生视频和图生视频两种生成方式,支持生成5秒或10秒、480p或720p分辨率的视频。具备影视级视频生成质量,能精细控制人物外貌、衣着、表情动作等细节,支持360度环绕、航拍、变焦等多种运镜技术,生成的视频画质细腻、美感十足。模型广泛用在电商广告、娱乐特效、影视创作、动态壁纸等领域,能有效降低制作成本和周期。
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引入对比监督信号,进一步优化模型训练。SuperEdit不需要额外的视觉语言模型(VLM)或预训练任务,仅依赖高质量的监督信号,在多个基准测试中实现显著的性能提升。 Super
美团正在加速其 AI 战略布局,即将推出一款名为 “NoCode” 的 AI 编程工具,并已悄然注册了 “nocode.cn” 域名,目前该网站正处于灰度测试阶段,预示这款面向非技术用户的全新产品即将正式面世。 该工具由美团研发质量与效率团队打造,定位于新兴的 “Vibe Coding(氛围编程)” 赛道,通过对话式交互实现应用构建,主打 “人人可用” 的 AI 编程体验。 不同于 Curso
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
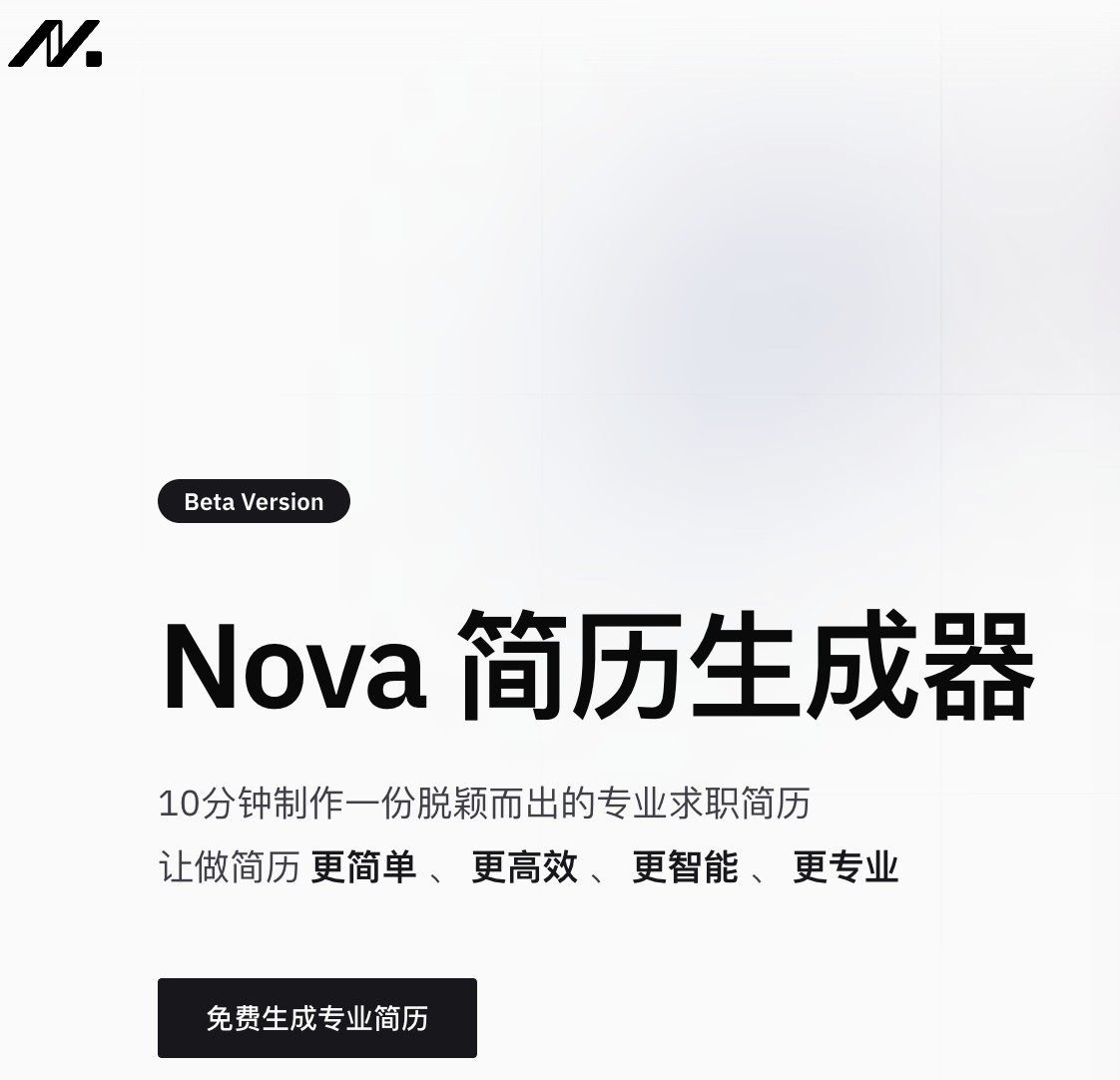
NovaCV 是基于人工智能技术的在线AI简历生成器,帮助用户快速制作专业、美观的求职简历。集成了领先的 AI 功能,如智能简历助手、一键生成工作描述、AI 润色引擎、智能纠错、中英文翻译等,确保简历内容精准且专业。NovaCV 提供了丰富的专业模板,覆盖主流行业,排版设计符合招聘者喜好,能帮助求职者在众多简历中脱颖而出。NovaCV 提供 API 服务,支持简历智能检查、文本解析和模板生成等功能
文本到图像的扩散模型的最新进展已取得显著成功,但它们往往难以完全捕捉用户的意图。现有的使用文本输入结合边界框或区域蒙版的方法无法提供精确的空间引导,常常导致对象方向错位或意外。为了解决这些限制,我们提出了涂鸦引导扩散(ScribbleDiff),这是一种无需训练的方法,它利用用户提供的简单涂鸦作为视觉提示来引导图像生成。然而,将涂鸦纳入扩散模型存在挑战,因为涂鸦具有稀疏和单薄的特性,很难确保准确的
只显示前20页数据,更多请搜索
Showing 409 to 432 of 437 results