关键词 "DM campaigns" 的搜索结果, 共 18 条, 只显示前 480 条
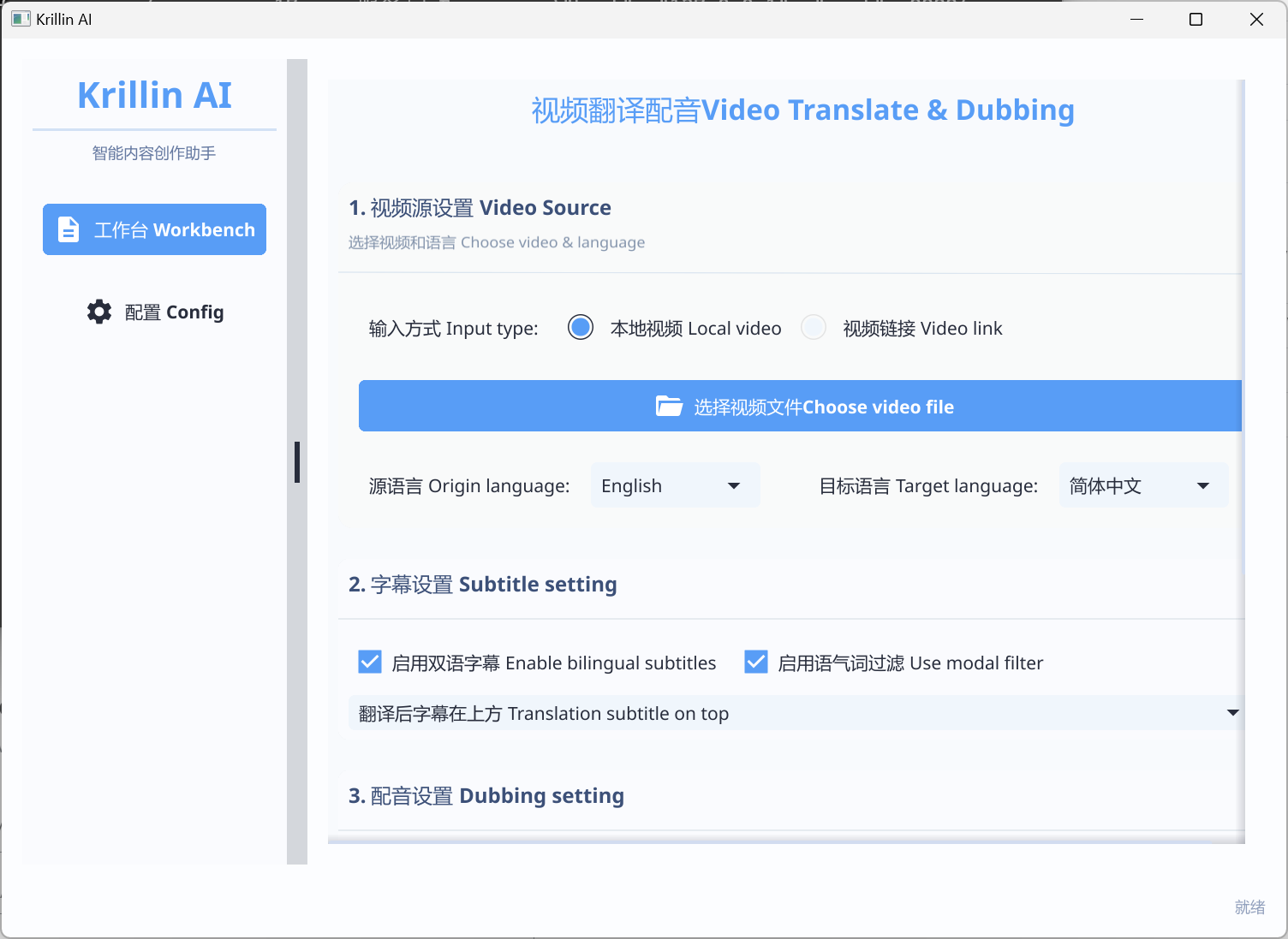
极简部署AI视频翻译配音工具 KrillinAI-一款AI视频翻译配音工具 提供了从视频下载,音频提取,音频转录,文本切割,翻译,对齐,到最终合成适配抖音,哔哩哔哩,小红书,视频号,快手等主流平台格式的一站式解决方案。 基于AI大模型的视频翻译和配音工具,专业级翻译,一键部署全流程,可以生成适配抖音,小红书,哔哩哔哩,视频号,TikTok,Youtube Shorts等形态的
WorldMem 是南洋理工大学、北京大学和上海 AI Lab 推出的创新 AI 世界生成模型。模型基于引入记忆机制,解决传统世界生成模型在长时序下缺乏一致性的关键问题。在WorldMem中,智能体在多样化场景中自由探索,生成的世界在视角和位置变化后能保持几何一致性。WorldMem 支持时间一致性建模,模拟动态变化(如物体对环境的影响)。模型在 Minecraft 数据集上进行大规模训练,在真实
GitFriend 是基于 React、TypeScript 和 AI 技术推出的 AI GitHub 辅助工具,能简化 GitHub 的使用流程,提升开发效率。GitFriend支持基于 AI 聊天功能为用户提供 Git 和 GitHub 的问题解答,自动生成定制化的 README 文件,帮助用户快速创建项目文档。工具用户友好的界面及动态交互体验,适合开发者、项目管理者及初学者使用。 GitF
🤱🏻 使用 Rust 将任何网页变成桌面应用程序。 🤱🏻利用Rust轻松构建轻量级多端桌面应用 Pake 支持 Mac、Windows 和 Linux。查看 README 文件,了解热门软件包、命令行打包和定制开发信息。欢迎在讨论区分享您的建议。 特征 🎐 比 Electron 包小近 20 倍(约 5M!) 🚀 借助 Rust Tauri,Pake 比基于 JS 的框架更加轻
BILIVE 是基于 AI 技术的开源工具,专为 B 站直播录制与处理设计。工具支持自动录制直播、渲染弹幕和字幕,支持语音识别、自动切片精彩片段,生成有趣的标题和风格化的视频封面。BILIVE 能自动将处理后的视频投稿至 B 站,综合多种模态模型,兼容超低配置机器,无需 GPU 即可运行,适合个人用户和小型服务器使用。 1. Introduction Have you notice
拥有20 多年经验的无与伦比的生命科学专业知识 信任与合规:轻松实现审计准备。 数据洞察与控制:可操作的洞察,以更快地做出决策。 内容管理:控制集成、合规协作。
类似 Manus 但基于 Deepseek R1 Agents 的本地模型。 Manus AI 的本地替代品,它是一个具有语音功能的大语言模型秘书,可以 Coding、访问你的电脑文件、浏览网页,并自动修正错误与反省,最重要的是不会向云端传送任何资料。采用 DeepSeek R1 等推理模型构建,完全在本地硬体上运行,进而保证资料的隐私。 Features: 100% 本机运行:
Pyrefly 是一款快速的 Python 类型检查器,计划在 2025 年底取代 Meta 现有的 Pyre 类型检查器。 Pyrefly 旨在通过 IDE 功能和检查 Python 代码来提高开发速度。 主要特点: 类型推断:除了函数参数之外,Pyrefly 可以在大多数位置推断类型。它可以推断变量的类型和返回类型。 Flow Types:Pyrefly 可以理解程序的控制流以细化
AnimeGamer 是基于多模态大型语言模型(MLLM)构建的,可以生成动态动画镜头和角色状态更新,为用户提供无尽的动漫生活体验。它允许用户通过开放式语言指令与动漫角色互动,创建独特的冒险故事。该产品的主要优点包括:动态生成与角色交互的动画,能够在不同动漫之间创建交互,丰富的游戏状态预测等。 快速入门 🔮 环境设置 要设置推理环境,您
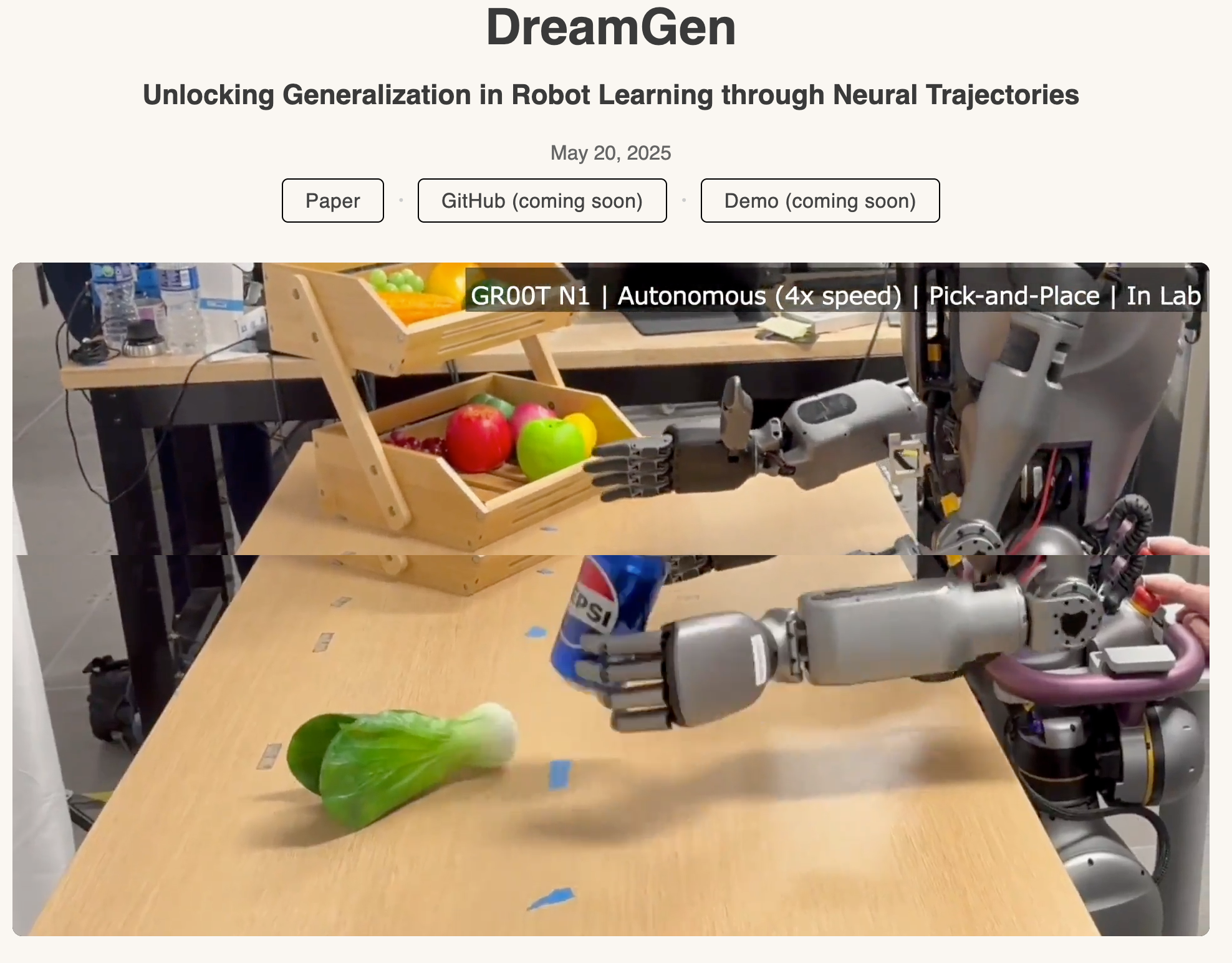
DreamGen是英伟达推出的创新的机器人学习技术,基于AI视频世界模型生成合成数据,让机器人能在梦境中学习新技能。DreamGen仅需少量现实视频数据,能生成大规模逼真的训练数据,实现机器人在新环境中的行为泛化和环境泛化。DreamGen的四步流程包括微调视频世界模型、生成虚拟数据、提取虚拟动作以及训练下游策略。DreamGen让机器人在没有真实世界数据支持的情况下,凭文本指令完成复杂任务,显著
DMind是DMind研究机构发布的专为Web3领域优化的大型语言模型。针对区块链、去中心化金融和智能合约等场景深度优化,使用Web3数据微调采用RLHF技术对齐。DMind在Web3专项基准测试中表现优异,性能远超一线通用模型,推理成本仅为主流大模型的十分之一。包含DMind-1和DMind-1-mini两个版本,前者适合复杂指令和多轮对话,后者轻量级,响应快、延迟低,适合代理部署和链上工具。
FaceAge是一款AI人脸识别扫描模型,它通过数万张患者照片和公共图像数据库进行训练,能够精准判断个人衰老迹象。 模型描述 FaceAge 深度学习流程包括两个阶段:面部定位和提取阶段,以及带有输出线性回归器的特征嵌入阶段,可提供生物年龄的连续估计。 第一阶段通过在照片中定位人脸并在其周围定义一个边界框来预处理输入数据。然后对图像进行裁剪、调整大小,并在所有 RGB 通道上对像
Vid2World是清华大学联合重庆大学推出的创新框架,支持将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。模型基于视频扩散因果化和因果动作引导两大核心技术,解决传统VDM在因果生成和动作条件化方面的不足。Vid2World在机器人操作和游戏模拟等复杂环境中表现出色,支持生成高保真、动态一致的视频序列,支持基于动作的交互式预测。Vid2World为提升世界模
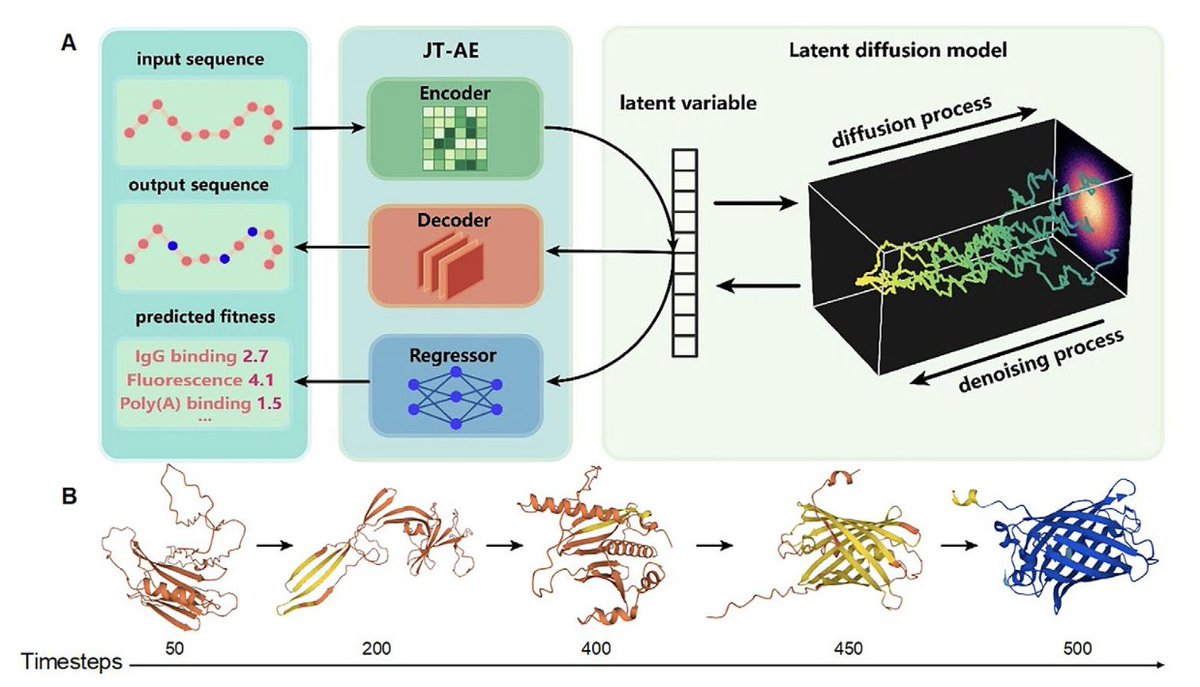
1.PRO-LDM 引入了一种模块化潜在扩散模型,用于全长蛋白质序列设计,该模型兼具无条件生成和功能优化,将准确性与计算效率完美结合。 2. 一项重大创新在于在潜在空间中应用扩散,显著降低采样成本,同时保持生成序列的保真度和多样性。 3. PRO-LDM 通过将条件潜在扩散与监督适应度预测相结合,实现了具有目标特性(例如荧光、溶解度、热/化学稳定性)的蛋白质序列的可控设计。 4. 通过无分类
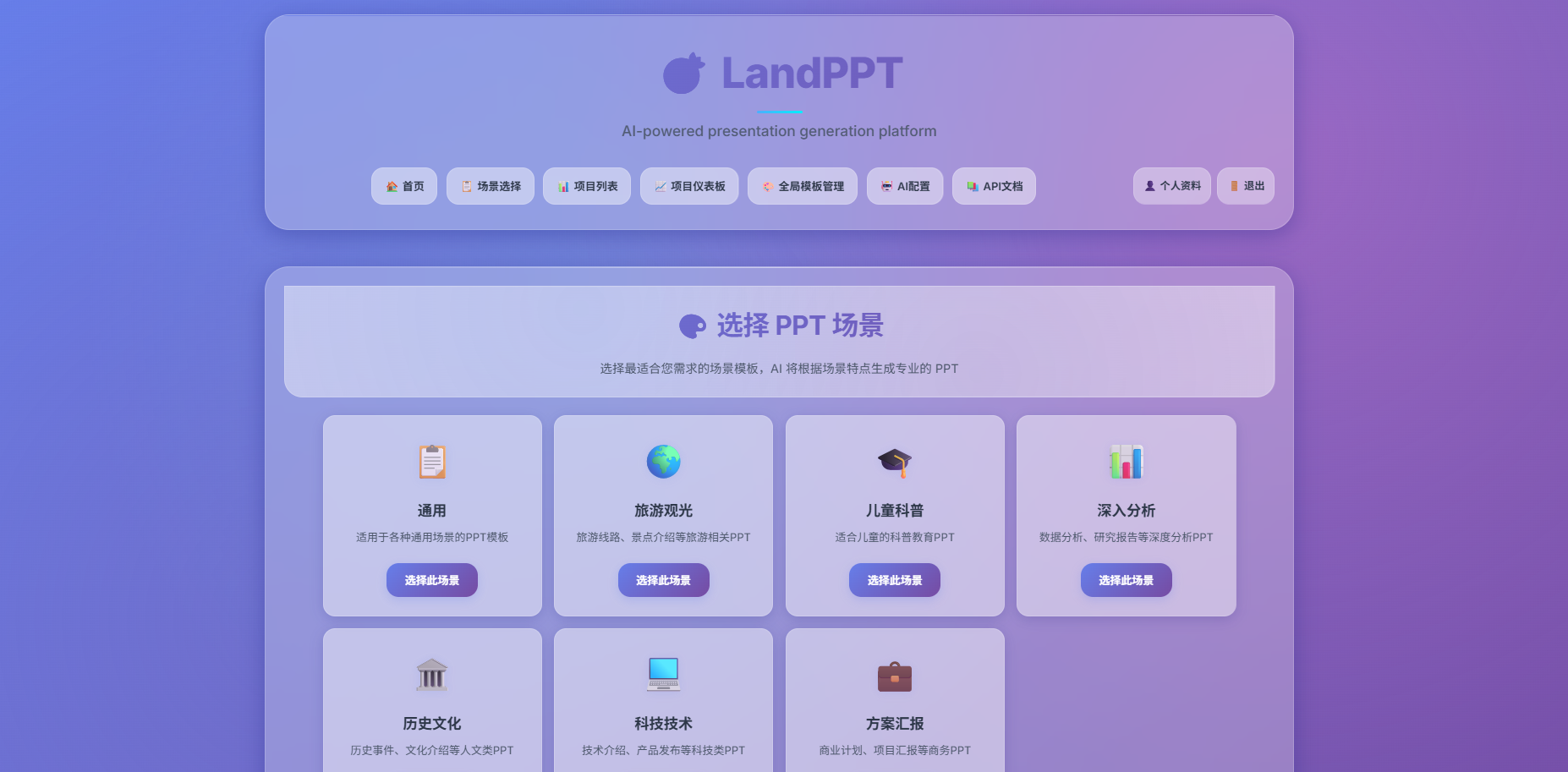
LandPPT 是AI演示文稿生成平台,能将文档内容快速转换为专业的 PPT 演示文稿。LandPPT支持 OpenAI、Claude、Gemini 等多种 AI 模型,兼容 PDF、Word、Markdown 等文件格式,支持智能解析内容,生成结构清晰的大纲和精美的 PPT 页面。平台提供丰富的模板系统和自定义功能,用户基于现代化的 Web 界面进行可视化编辑、实时预览和多格式导出。LandPP
Glass 是Pickle 团队推出的开源隐形 AI 桌面助手。Glass能在后台实时捕捉屏幕内容和音频,将其转化为结构化知识。Glass核心功能包括实时会议记录、自动摘要生成、上下文理解及实时问答。Glass 的设计真正隐形,不会出现在屏幕录制、截图或 Dock 中,完全不干扰用户操作。Glass支持 macOS 和 Windows 系统,用户能免费使用,且无需注册。Glass开源特性成为 AI
VidText AI is a free AI-driven tool that transcribe video & audio to text quickly and accurately.Support 100+Languages, Generate Mind map, 15 Hour Uploads, over 99% Accuracy.Perfect for meetings, lect
Drawnix 是一款免费开源、All in one 在线白板工具,集思维导图、流程图、自由画笔及多种导出和编辑功能于一体,支持跨平台使用和插件扩展,为个人和团队提供简洁高效的创作体验.开源白板工具(SaaS),一体化白板,包含思维导图、流程图、自由画等开源白板工具(SaaS),一体化白板,包含思维导图、流程图、自由画等All in one 白板,思维导图、流程图、自由画等English READ
只显示前20页数据,更多请搜索
Showing 361 to 378 of 378 results