关键词 "GPU services" 的搜索结果, 共 24 条, 只显示前 480 条
Model Context Protocol (MCP) Server for National Park Services data
Enables cloud-based AI services to access local Stdio based MCP servers
This is a quick start guide that provides the basic building blocks to set up a remote Model Context Protocol (MCP) server using Azure Container Apps. The MCP server is built using Node.js and TypeScr
MCP server for RDS Services via OPENAPI.
Deployable MCP Servers for common AWS services (Location, S3, Aurora PG Data API) using AWS CDK.
A Python-based MCP server that lets Claude run boto3 code to query and manage AWS resources. Execute powerful AWS operations directly through Claude with proper sandboxing and containerization. No nee
A collection of Model Context Protocol (MCP) servers for managing Palo Alto Networks firewalls and services
Model Context Protocol (MCP) Server for Creem.io – Enhancing Merchant of Record services with transparent billing and improved fees.
A Nuclei security scanning server based on MCP (Model Control Protocol), providing convenient vulnerability scanning services.一个基于 MCP (Model Control Protocol) 的 Nuclei 安全扫描服务器,提供便捷的漏洞扫描服务。
Mcp services by marshal
百度地图核心API现已全面兼容MCP协议,是国内首家兼容MCP协议的地图服务商。
Location services, directions, and place details
A Model Context Protocol (MCP) server that provides location services
An OpenStreetMap MCP server implementation that enhances LLM capabilities with location-based services and geospatial data.
MCP Server for ArcGIS Location Services
ACE-Step,这是一个用于音乐生成的全新开源基础模型,它克服了现有方法的关键局限性,并通过整体架构设计实现了最佳性能。当前的方法在生成速度、音乐连贯性和可控性之间面临着固有的权衡。例如,基于 LLM 的模型(例如 Yue、SongGen)在歌词对齐方面表现出色,但推理速度慢且存在结构性伪影。另一方面,扩散模型(例如 DiffRhythm)虽然能够实现更快的合成速度,但通常缺乏长距离的结构连贯性
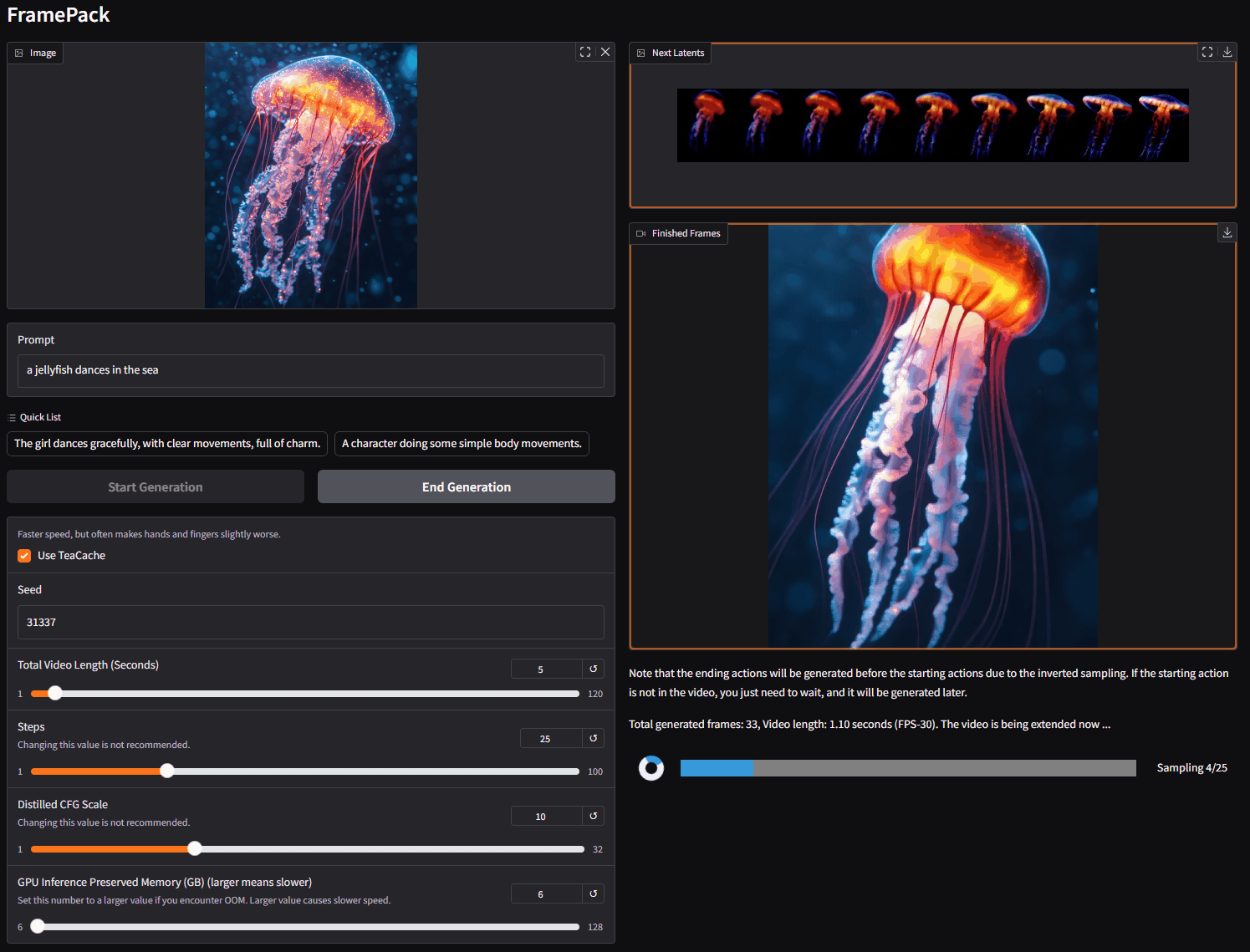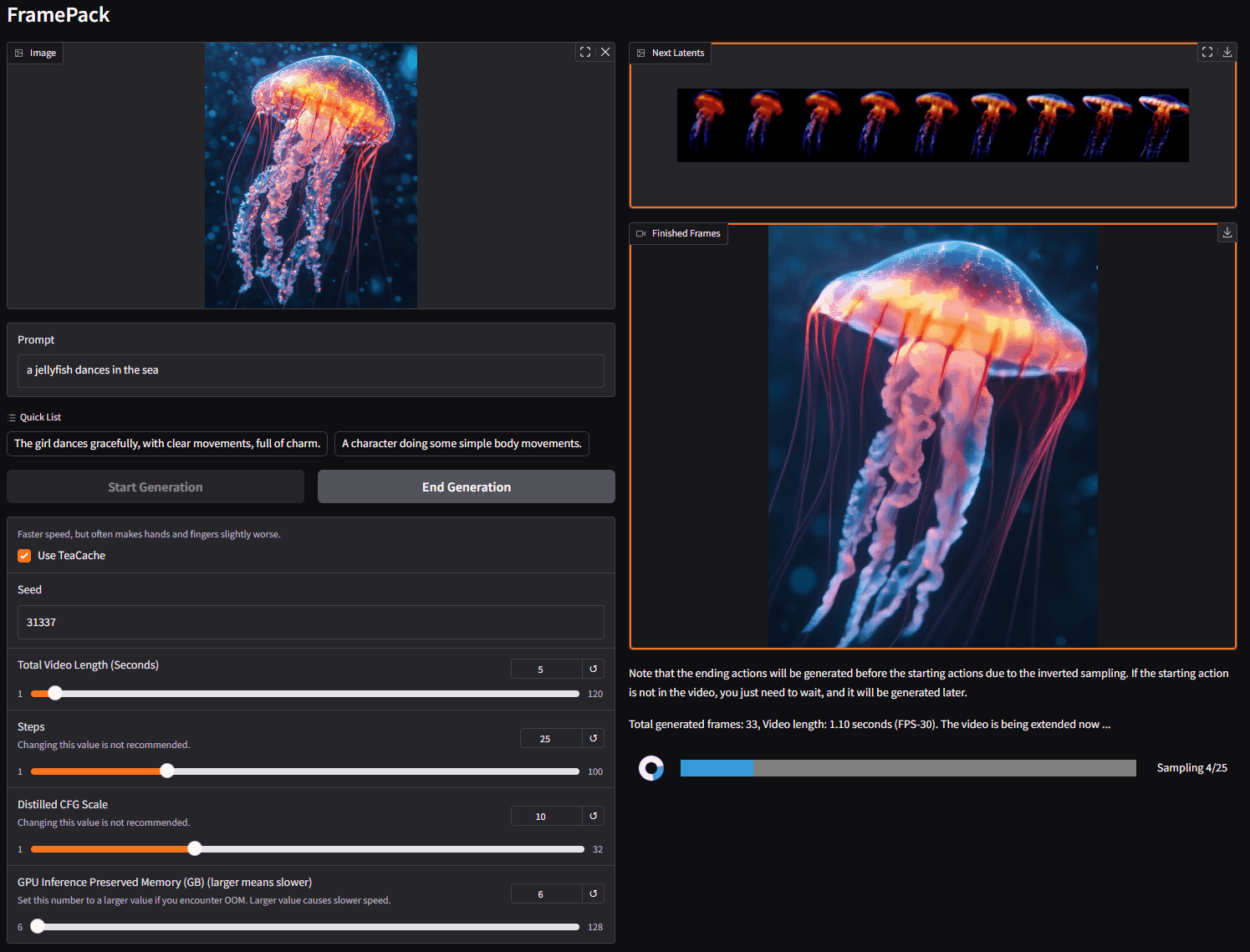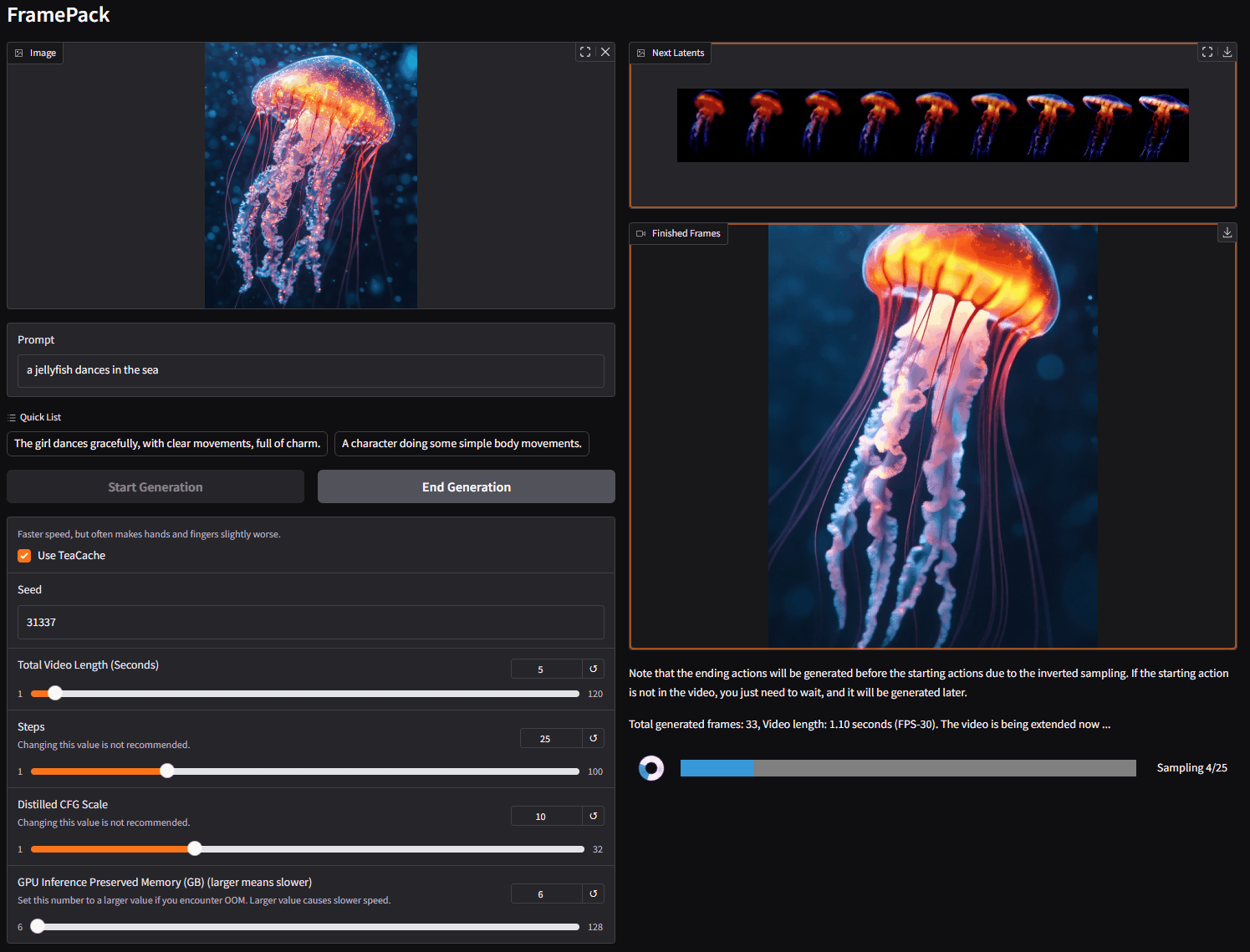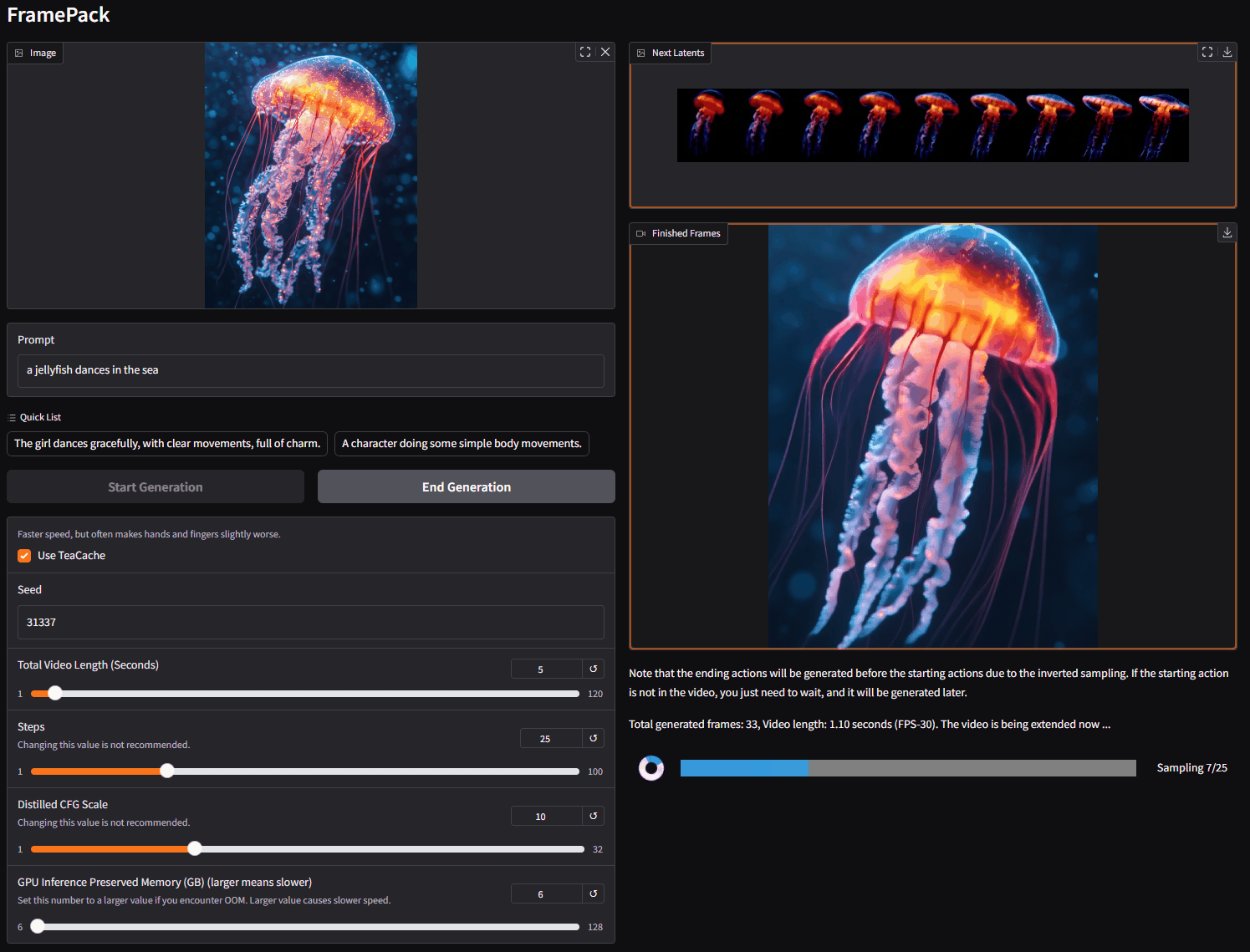
FramePack 是一个渐进式生成视频的下一帧(下一帧部分)预测神经网络结构。 FramePack 将输入上下文压缩为恒定长度,以便生成工作量不受视频长度的影响。 即使在笔记本电脑 GPU 上,FramePack 也可以使用 13B 模型处理大量帧。 FramePack 可以使用更大的批量大小进行训练,类似于图像扩散训练的批量大小。
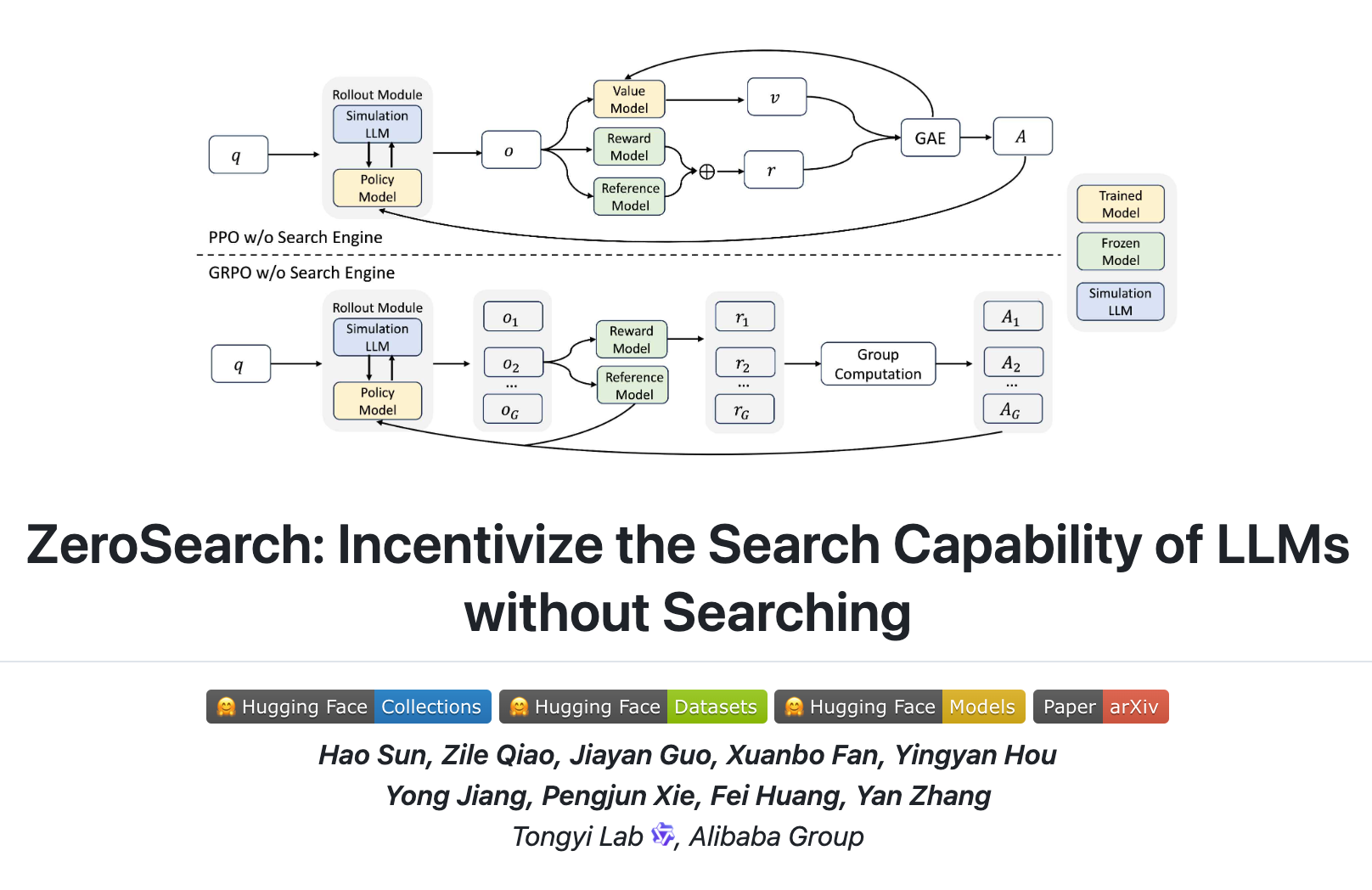
阿里巴巴昨日在 Github 等平台开源了 ZeroSearch 大模型搜索引擎。这是一种无需与真实搜索引擎交互即可激励大模型搜索能力的强化学习框架。 ZeroSearch 主要利用了大模型在大规模预训练过程中积累的丰富知识,将其转化为一个检索模块,能够根据搜索查询生成相关内容。同时,还可以动态控制生成内容的质量,这是传统搜索引擎所不具备的特殊功能。 研究人员在 NQ、TriviaQA、Pop
RWKV开源发布了 RWKV7-G1 1.5B 推理模型(Reasoning Model)。模型基于 World v3.5 数据集训练,包含更多小说、网页、数学、代码和 reasoning 数据,总数据为 5.16T tokens。其具备其它同尺寸模型不具备的推理能力和任务能力,同时还支持现实世界 100+ 种语言。 在实际测试中,RWKV7-G1 1.5B 模型的推理逻辑性较强,能够完成有难度的
Muyan-TTS,一款低成本、具备良好二次开发支持的模型并完全开源,以方便学术界和小型应用团队的音频技术爱好者。 当前开源的Muyan-TTS版本由于训练数据规模有限,致使其仅对英语语种呈现出良好的支持效果。不过,得益于与之同步开源的详尽训练方法,从事相关行业的开发者能够依据自身实际业务场景,灵活地对Muyan-TTS进行功能升级与定制化改造。 01. H
ContextGem:轻松从文档中提取 LLM ContextGem 是一个免费的开源 LLM 框架,它可以让您以最少的代码更轻松地从文档中提取结构化数据和见解。 💎 为什么选择 Contex
字节开源DreamO,统一图像定制框架,把图像换装、换脸、换造型、换风格以及组合操作装在了一起 支持ID、IP、Try-On等组合,支持16GB/24GB显卡运行,用于虚拟试穿、商品广告、营销广告什么的比较实用 四个能力: IP,处理角色形象,支持人物、物体、动物等输入 ID,人脸身份处理 Try-On,虚拟试穿,可以同时换多件衣服 Style,风格迁移,目前还不能和其他任务组合 DreamO正
Challympics 是专注于人工智能和技术创新的赛事平台,汇聚多种类型的赛事,涵盖创新创意、量子计算、AIGC 大模型方案应用、人工智能应用等多个领域。平台为开发者和创新者提供一个展示创意和技能的舞台,推动人工智能技术在各个领域的应用和发展。 Challympics的主要功能 赛事组织与管理:平台定期发布各类人工智能和技术创新相关的赛事信息,涵盖创新创意、量子计算、AIGC 大模型方案
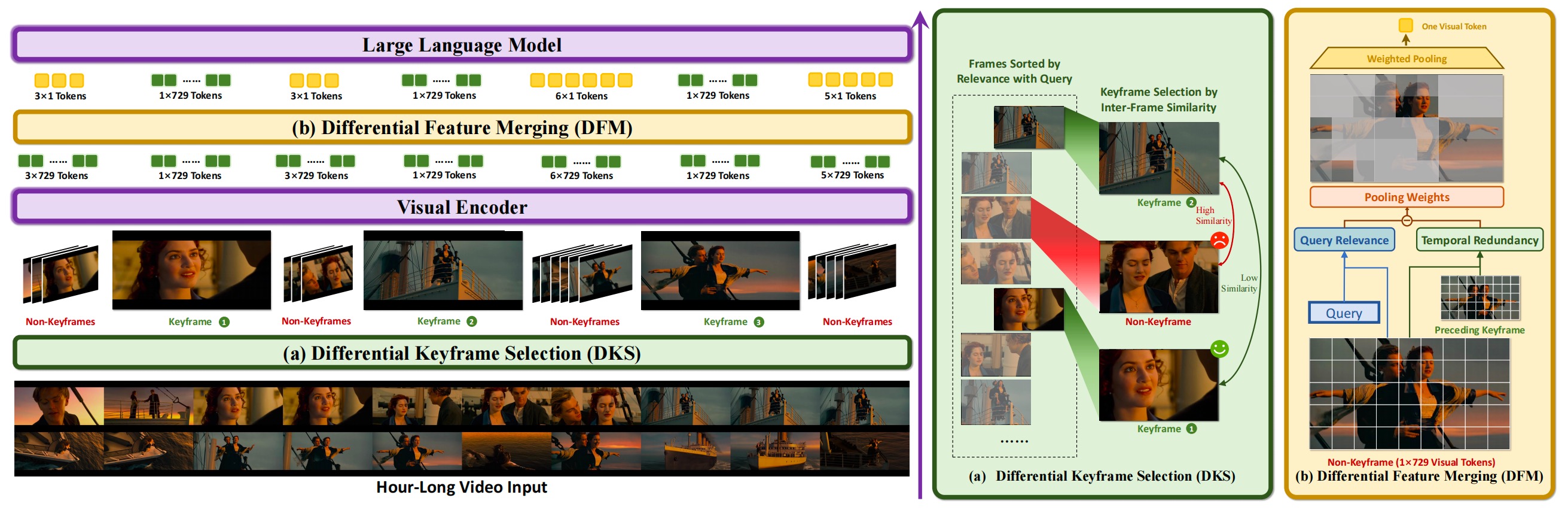
ViLAMP(VIdeo-LAnguage Model with Mixed Precision)是蚂蚁集团和中国人民大学联合推出的视觉语言模型,专门用在高效处理长视频内容。基于混合精度策略,对视频中的关键帧保持高精度分析,显著降低计算成本提高处理效率。ViLAMP在多个视频理解基准测试中表现出色,在长视频理解任务中,展现出显著优势。ViLAMP能在单张A100 GPU上处理长达1万帧(约3小时)
只显示前20页数据,更多请搜索
Showing 409 to 432 of 452 results