关键词 "GitHub syncing" 的搜索结果, 共 24 条, 只显示前 480 条
在 AI 浪潮中,如何高效管理海量信息、实现智能搜索与知识共享,已成为个人与企业共同面临的挑战。Coco AI —— 一款完全开源、免费的智能搜索与知识库工具,成为面对这一挑战的利器。 Coco AI 能够轻松连接本地文件数据源、S3 对象存储、Google Workspace、Dropbox、GitHub、Notion、Yuque、Hugo 等多种数据源,实现本地与云端数据的统一搜索与管理。无
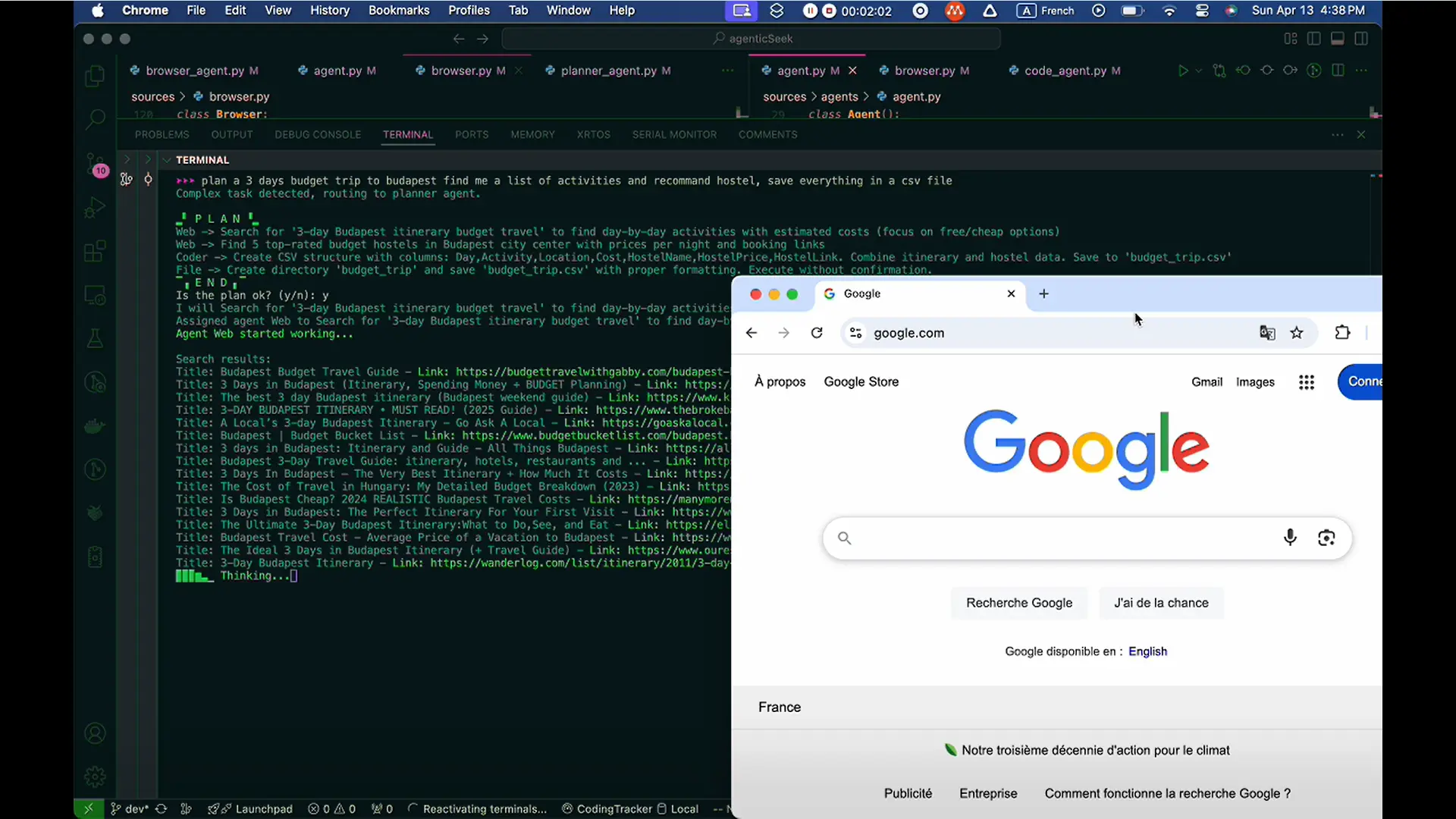
超级麦吉是一个强大的通用型 AI Agent,专门面向复杂任务场景设计。通过多 Agent 设计体系以及丰富的工具能力支持,超级麦吉支持自主任务理解、自主任务规划、自主行动、自主纠错等智能的能力。它能够理解自然语言指令,执行各类业务流程,并交付最终的目标结果。作为麦吉产品矩阵的旗舰产品,超级麦吉通过开源的方式提供了强大的二次开发能力,让企业能够快速构建和部署符合特定业务需求的智能助手,大幅提升决策
卡内基梅隆大学的研究团队开发出一款名为 LegoGPT 的 AI 模型,能够根据文字指令生成可实际搭建的乐高设计。 比如输入文本「基本款沙发」,一眨眼的功夫,乐高沙发就拼好了。 团队训练了一种自回归大型语言模型,通过预测下一个 token 的方式,判断下一块该放置什么积木。团队还为模型增加了有效性校验和带有物理感知的回滚机制,确保生成的设计不会出现积木重叠或悬空等问题,也就是说最终结果始终可行
类似 Manus 但基于 Deepseek R1 Agents 的本地模型。 Manus AI 的本地替代品,它是一个具有语音功能的大语言模型秘书,可以 Coding、访问你的电脑文件、浏览网页,并自动修正错误与反省,最重要的是不会向云端传送任何资料。采用 DeepSeek R1 等推理模型构建,完全在本地硬体上运行,进而保证资料的隐私。 Features: 100% 本机运行:
谷歌推出了名为 Jules 的 AI 编程代理 (Coding Agent),目前处于公开 Beta 测试阶段,需要申请,用户可以免费使用。 Jules 旨在帮助开发者修复错误、更新依赖、迁移代码和添加新功能。它与 GitHub 集成,异步执行任务。用户分配任务后,Jules 会在虚拟机中创建开发环境、安装依赖、编写测试、进行更改、运行测试并提交拉取请求,同时展示工作进展。 简单来说,它能
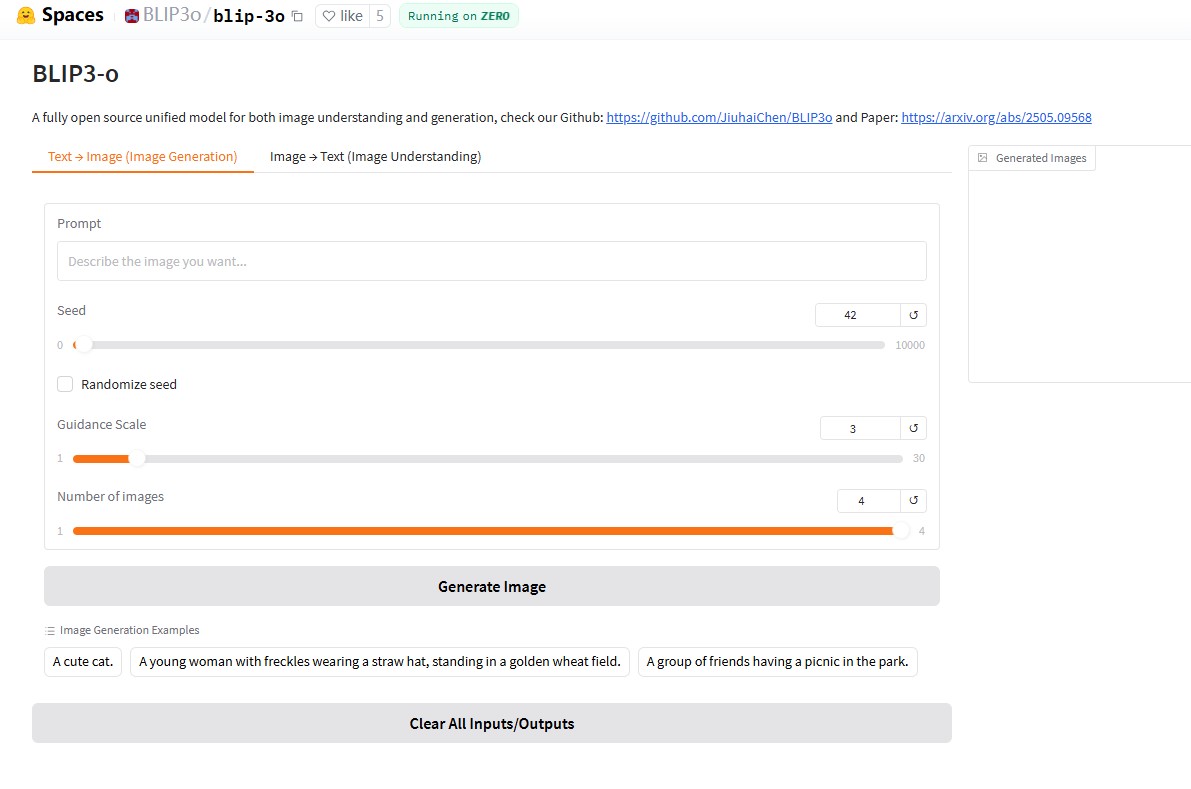
Blip 3o 是一个基于 Hugging Face 平台的应用程序,利用先进的生成模型从文本生成图像,或对现有图像进行分析和回答。该产品为用户提供了强大的图像生成和理解能力,非常适合设计师、艺术家和开发者。此技术的主要优点是其高效的图像生成速度和优质的生成效果,同时还支持多种输入形式,增强了用户体验。该产品是免费的,定位于开放给广大用户使用。 需求人群: "该产品适合设计师、开发者和
英纬达发布了其最新的 Cosmos-Reason1系列模型,旨在提升人工智能在物理常识和具身推理方面的能力。随着人工智能在语言处理、数学及代码生成等领域取得显著进展,如何将这些能力扩展到物理环境中成为了一大挑战。 物理 AI(Physical AI)不同于传统的人工智能,它依赖于视频等感官输入,并结合现实物理法则来生成反应。物理 AI 的应用领域包括机器人和自动驾驶车辆等,需要具备常识推理能
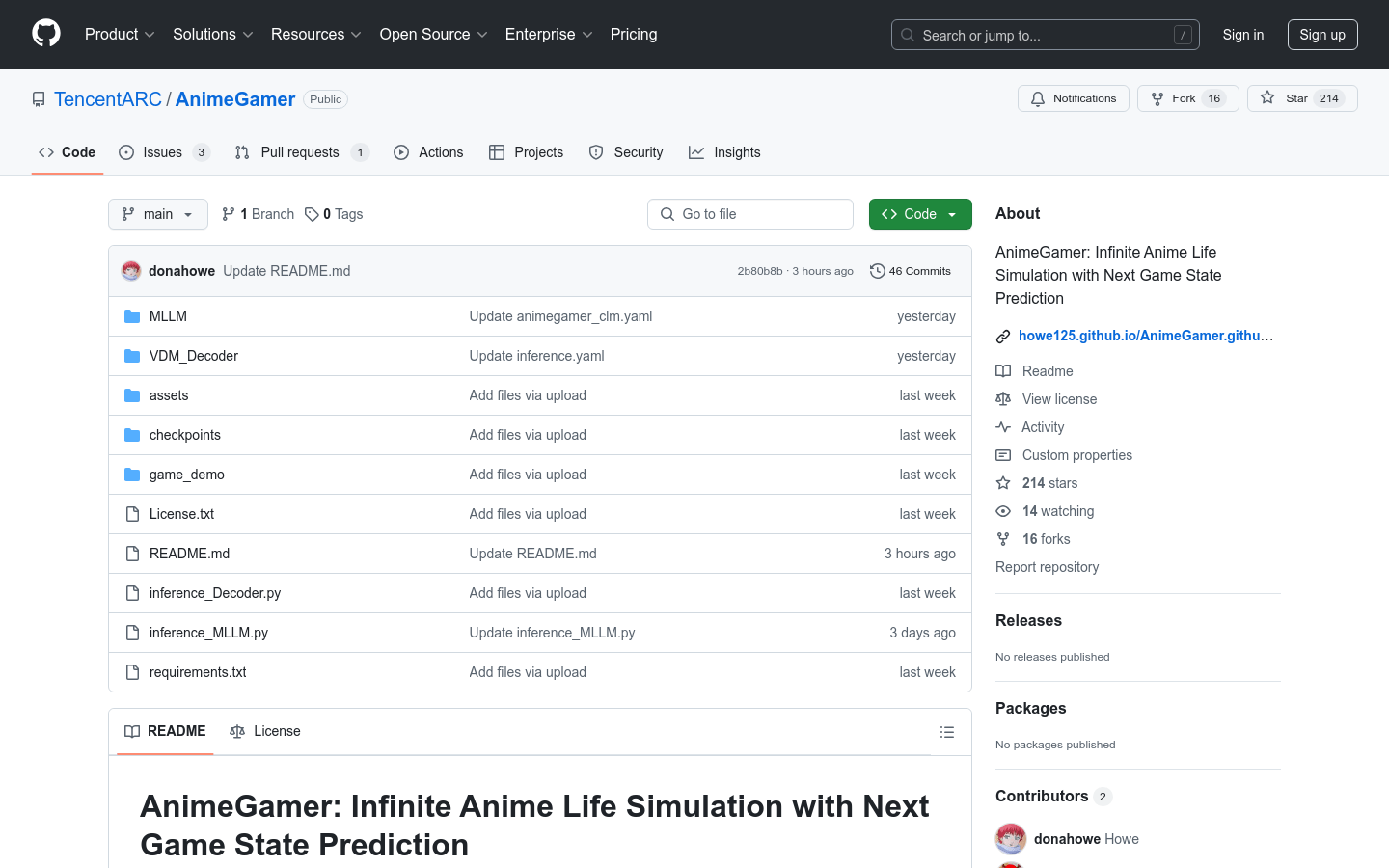
AnimeGamer 是基于多模态大型语言模型(MLLM)构建的,可以生成动态动画镜头和角色状态更新,为用户提供无尽的动漫生活体验。它允许用户通过开放式语言指令与动漫角色互动,创建独特的冒险故事。该产品的主要优点包括:动态生成与角色交互的动画,能够在不同动漫之间创建交互,丰富的游戏状态预测等。 快速入门 🔮 环境设置 要设置推理环境,您
Devstral是Mistral AI和All Hands AI推出的专为软件工程任务设计的编程专用模型。Devstral在解决真实世界软件问题上表现出色,在SWE-Bench Verified基准测试中,得分46.8%大幅领先其他开源模型。Devstral支持处理复杂代码库中的上下文关系、识别组件间联系及发现细微的代码错误。Devstral轻量级,能在单个RTX 4090或32GB内存的Mac上
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
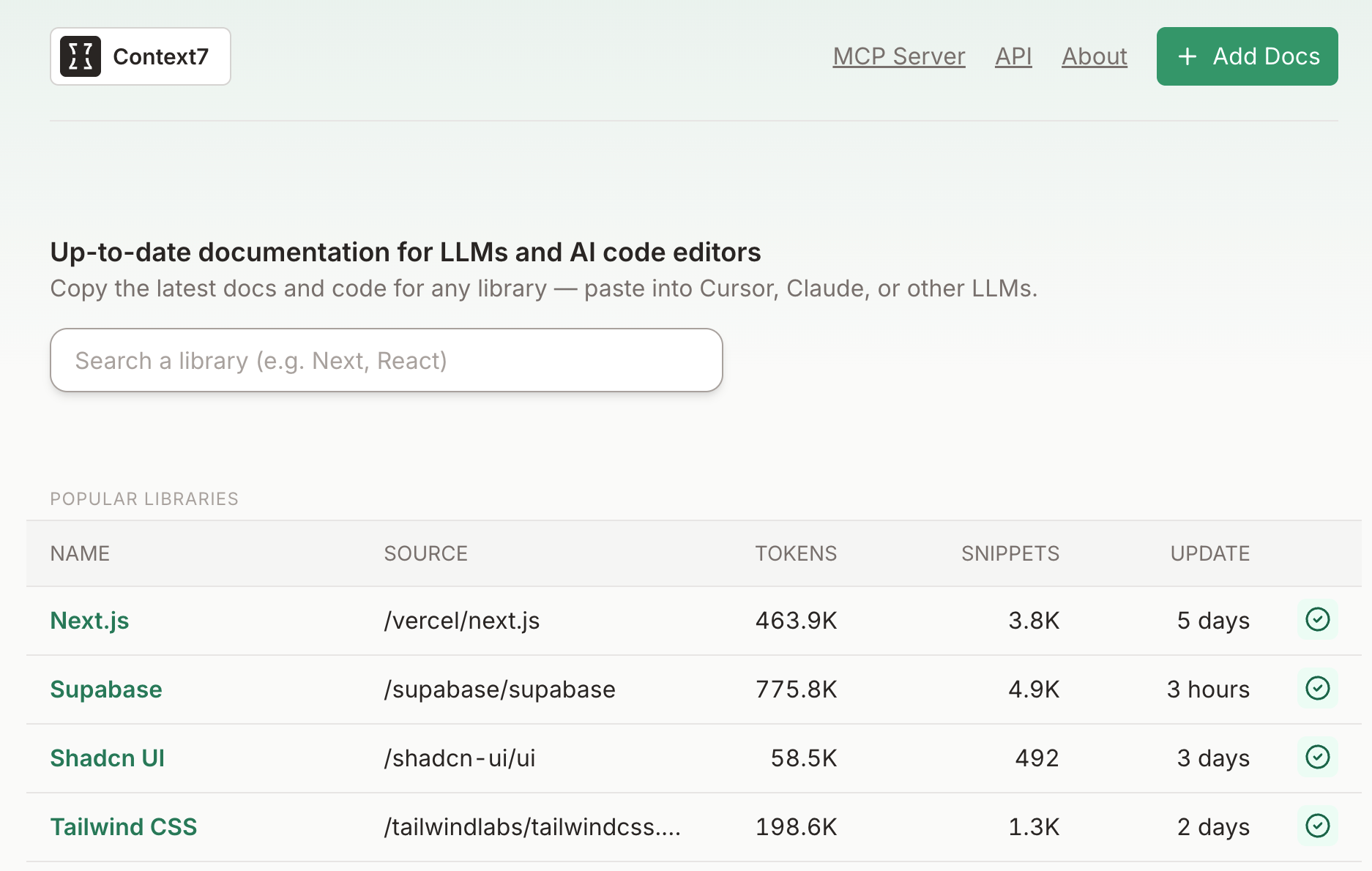
Context7 是 Upstash 推出的AI编程辅助工具,为大型语言模型(LLMs)和 AI 代码编辑器提供最新、版本特定的文档和代码示例。通过解析文档、丰富内容、向量化和重新排名等步骤,确保开发者能获取到准确且最新的代码示例和文档。Context7 支持多种工具,如 Cursor、Windsurf、Claude Desktop 等,通过模型上下文协议(MCP)实现集成。 使用 Contex
Graphiti 是一个用于构建和查询时序感知知识图谱的框架,专为在动态环境中运行的 AI 代理量身定制。与传统的检索增强生成 (RAG) 方法不同,Graphiti 持续将用户交互、结构化和非结构化企业数据以及外部信息集成到一个连贯且可查询的图中。该框架支持增量数据更新、高效检索和精确的历史查询,无需完全重新计算图谱,因此非常适合开发交互式、情境感知的 AI 应用程序。 使用 Graphiti
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数,其中70亿为活跃参数。采用混合变换器专家架构(MoT),通过两个独立编码器分别捕捉图像的像素级和语义级特征。BAGEL遵循“下一个标记组预测”范式进行训练,使用海量多模态标记数据进行预训练,包括语言、图像、视频和网络数据。在性能方面,BAGEL在多模态理解基准测试中超越了Qwen2.5-VL和InternVL-2.5等顶级开源视觉语言模型
AutoBE 是 AI 驱动的后端服务器代码生成工具,通过用户描述需求自动生成高质量的后端代码。基于 TypeScript、NestJS、Prisma 和 Postgres 等技术栈构建,强调“氛围编码”(Vibe Coding),通过持续的用户反馈和编译器反馈来迭代优化代码。AutoBE 结合瀑布模型和螺旋模型的优点,确保代码的可靠性和安全性。 AutoBE的主要功能 需求分析(An
Moondream是一个免费开源的小型的人工智能视觉语言模型,虽然参数量小(Moondream1仅16亿,Moondream2为18.6亿)但可以提供高性能的视觉处理能力,可在本地计算机甚至移动设备或 Raspberry Pi 上运行,能够快速理解和处理输入的图像信息并对用户提出的问题进行解答。该模型由开发人员vikhyatk推出,使用SigLP、Phi-1.5和LLaVa训练数据集和模型权重初始
mPLUG-Owl3是阿里巴巴推出的通用多模态AI模型,专为理解和处理多图及长视频设计。在保持准确性的同时,显著提升了推理效率,能在4秒内分析完2小时电影。模型采用创新的Hyper Attention模块,优化视觉与语言信息的融合,支持多图场景和长视频理解。mPLUG-Owl3在多个基准测试中达到行业领先水平,其论文、代码和资源已开源,供研究和应用。 mPLUG-Owl3的主要功能 多
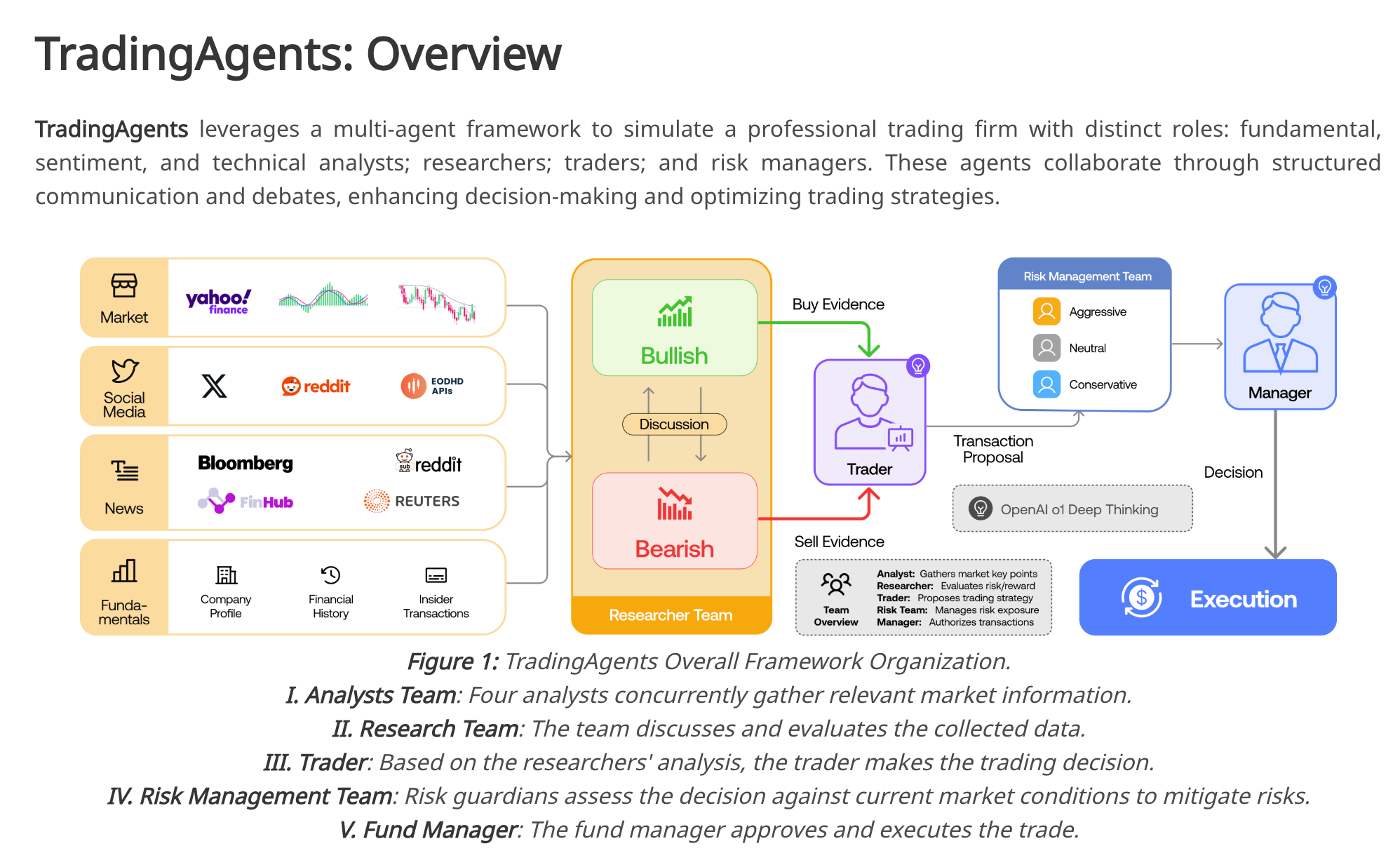
TradingAgents是加利福尼亚大学洛杉矶分校和麻省理工学院推出的多代理LLM金融交易框架,能模拟现实世界的交易公司环境。TradingAgents整合多个具有不同角色和风险偏好的LLM代理,如基本面分析师、情绪分析师、技术分析师、交易员和风险经理等,实现对复杂金融数据的全面分析与处理。代理基于代理辩论和对话进行交易决策,结合结构化输出与自然语言对话,提高决策的精确性和灵活性。实验结果表明,
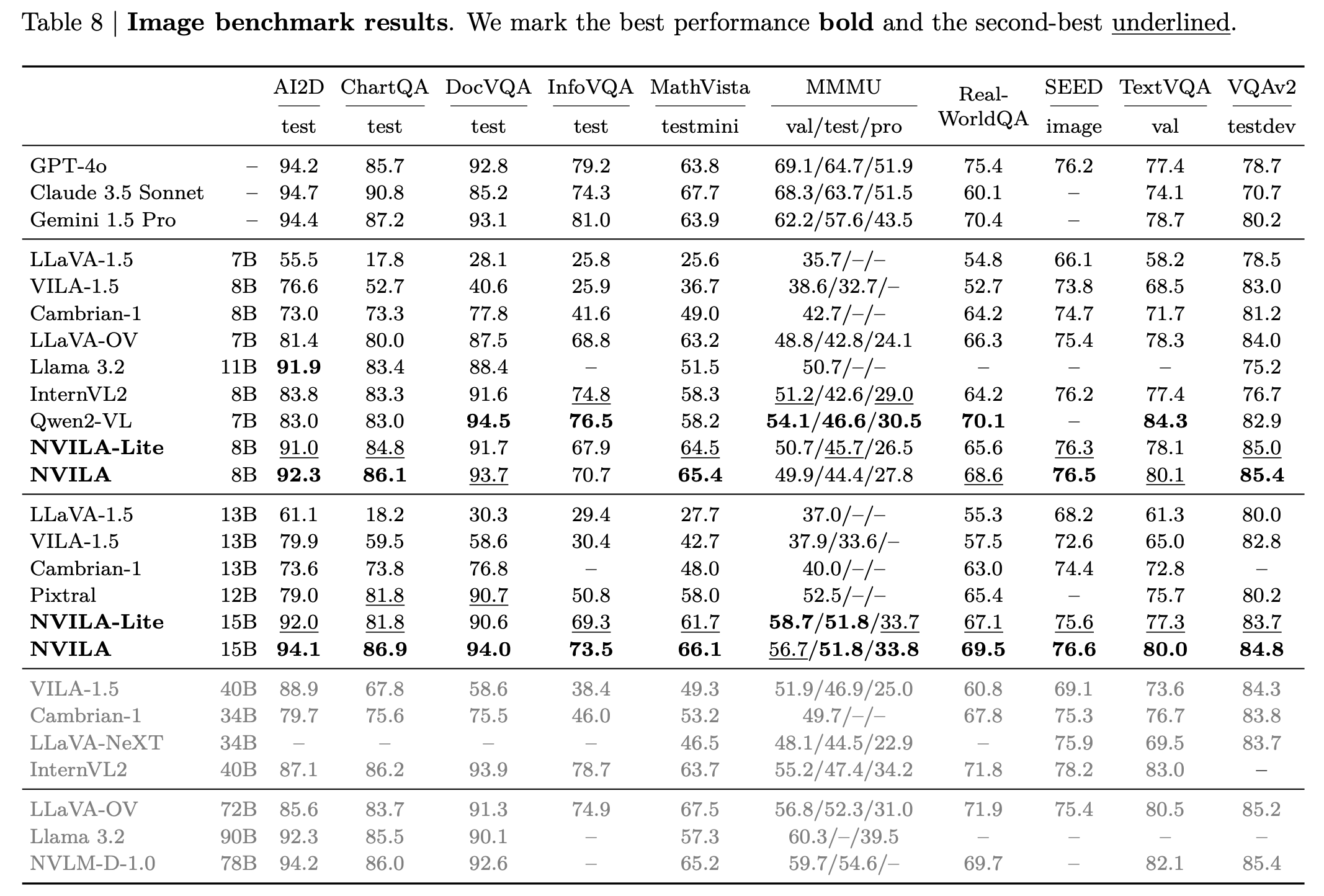
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等
DMind是DMind研究机构发布的专为Web3领域优化的大型语言模型。针对区块链、去中心化金融和智能合约等场景深度优化,使用Web3数据微调采用RLHF技术对齐。DMind在Web3专项基准测试中表现优异,性能远超一线通用模型,推理成本仅为主流大模型的十分之一。包含DMind-1和DMind-1-mini两个版本,前者适合复杂指令和多轮对话,后者轻量级,响应快、延迟低,适合代理部署和链上工具。
ScrapeGraphAI 是基于大型语言模型(LLM)驱动的智能网络爬虫工具包,专注于从各类网站和HTML内容中高效提取结构化数据。具备三大核心功能:SmartScraper可根据用户提示精准抓取网页中的结构化信息;SearchScraper基于AI驱动的搜索技术从搜索引擎结果中提取关键信息;Markdownify可将网页内容快速转换为整洁的Markdown格式,方便后续处理和存储。 Sc
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
全新的生成模型MeanFlow,最大亮点在于它彻底跳脱了传统训练范式——无须预训练、蒸馏或课程学习,仅通过一次函数评估(1-NFE)即可完成生成。 MeanFlow在ImageNet 256×256上创下3.43 FID分数,实现从零开始训练下的SOTA性能。 图1(上):在ImageNet 256×256上从零开始的一步生成结果 在ImageNet 256×25
FaceAge是一款AI人脸识别扫描模型,它通过数万张患者照片和公共图像数据库进行训练,能够精准判断个人衰老迹象。 模型描述 FaceAge 深度学习流程包括两个阶段:面部定位和提取阶段,以及带有输出线性回归器的特征嵌入阶段,可提供生物年龄的连续估计。 第一阶段通过在照片中定位人脸并在其周围定义一个边界框来预处理输入数据。然后对图像进行裁剪、调整大小,并在所有 RGB 通道上对像
fellou开源智能体工作流框架,Eko 2.0 在不同复杂程度上始终表现优异: 简单任务:成功率为 95%(其他产品的成功率为 80-90%) 平均成功率:78%(其他产品成功率为 56-61%) 中等复杂度:成功率为 76%(其他产品的成功率为 49-58%) 困难任务:成功率为 70%(其他产品的成功率为 32-43%) 这些数字背后隐藏着不可靠的自动化工具和企业真正可以依
只显示前20页数据,更多请搜索
Showing 409 to 432 of 553 results