关键词 "HTML export" 的搜索结果, 共 15 条, 只显示前 480 条
Stitch 是谷歌实验室(Google Labs)推出的基于生成式AI工具。能将简单的英语描述或图像迅速转化为用户界面(UI)设计以及支持运行的前端代码。Stitch 基于 Gemini 2.5 Pro 模型的多模态能力,用户可以通过自然语言描述或上传视觉素材(如草图、截图、线框图等)生成UI设计。Stitch 能识别输入,快速生成多种设计选项,方便用户调整和优化。可以将生成的设计无缝粘贴到 F
ScrapeGraphAI 是基于大型语言模型(LLM)驱动的智能网络爬虫工具包,专注于从各类网站和HTML内容中高效提取结构化数据。具备三大核心功能:SmartScraper可根据用户提示精准抓取网页中的结构化信息;SearchScraper基于AI驱动的搜索技术从搜索引擎结果中提取关键信息;Markdownify可将网页内容快速转换为整洁的Markdown格式,方便后续处理和存储。 Sc
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
全新的生成模型MeanFlow,最大亮点在于它彻底跳脱了传统训练范式——无须预训练、蒸馏或课程学习,仅通过一次函数评估(1-NFE)即可完成生成。 MeanFlow在ImageNet 256×256上创下3.43 FID分数,实现从零开始训练下的SOTA性能。 图1(上):在ImageNet 256×256上从零开始的一步生成结果 在ImageNet 256×25
II-Agent:一个用于构建和部署智能体的全新开源框架。II-Agent 是一款开源智能助手,旨在简化和增强跨领域的工作流程。它代表了我们与技术互动方式的重大进步——从被动工具转变为能够独立执行复杂任务的智能系统。作为简易的COZE,Dify平替。 ii-agent开源框架,擅长构建跨多个领域工作流的Agent,能独立执行复杂任务已是Agent标配 其技能覆盖研究与核查、内容生成、数据分析可视
PandaWiki 是开源的AI知识库搭建系统,基于 AI 大模型的能力,帮助用户快速构建智能化的产品文档、技术文档、FAQ 和博客系统。核心功能包括 AI 辅助创作、AI 问答和 AI 搜索,显著提升知识管理的效率和智能化水平。PandaWiki 提供强大的富文本编辑能力,支持 Markdown 和 HTML 编辑,可导出为 Word、PDF、Markdown 等多种格式。支持与第三方应用集成,
VTable: 不只是高性能的多维数据分析表格,更是行列间创作的方格艺术家!免费,开源,基于Canvas 的 百万数据秒级渲染前端表格组件库 VTable是字节跳动开源可视化解决方案 VisActor 的组件之一。 在现代应用程序中,表格组件是不可或缺的一部分,它们能够快速展示大量数据,并提供良好的可视化效果和交互体验。VTable是一款基于可视化渲染引擎VRender的高性能表格组件库,为用
BiliNote 是一个开源的 AI 视频笔记助手,支持通过哔哩哔哩、YouTube、抖音等视频链接,自动提取内容并生成结构清晰、重点明确的 Markdown 格式笔记。支持插入截图、原片跳转等功能。 Windows 打包版 本项目提供了 Windows 系统的 exe 文件,可在release进行下载。注意一定要在没有中文路径的环境下运行。 🔧 功能特性 支持多平台:
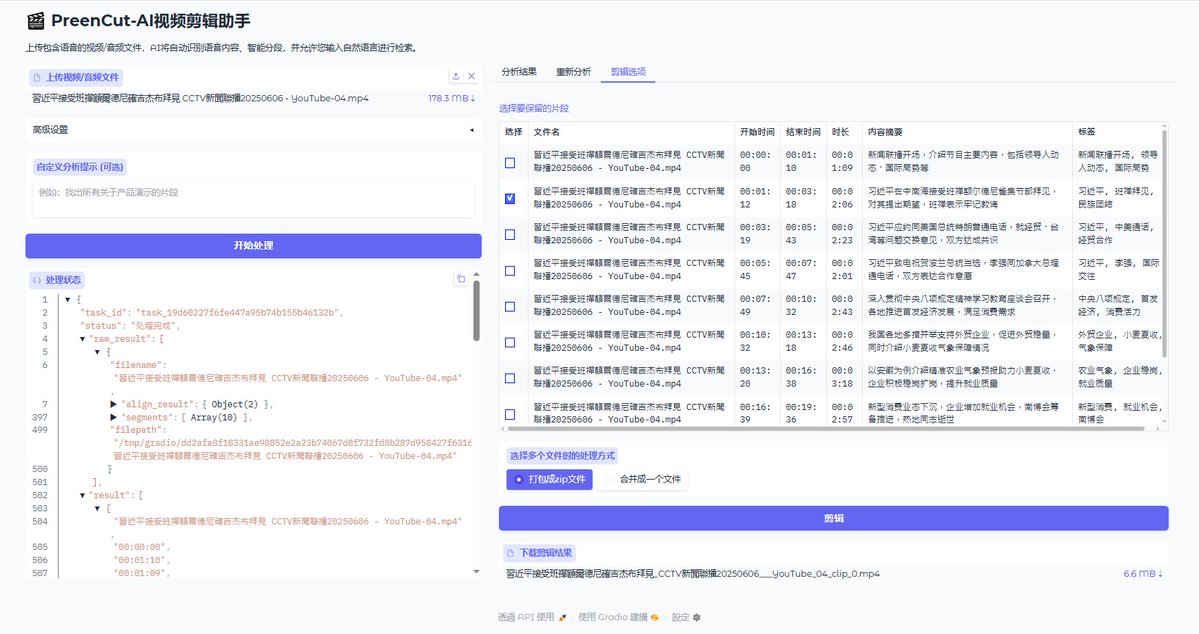
通过 AI 自动分析视频内容并生成文字转录,其中语义化搜索功能颇有用,支持自然语言描述快速找到想要的视频片段。 GitHub:http://github.com/roothch/PreenCut… 主要功能: - 基于 WhisperX 的自动语音识别,生成准确的视频转录 - AI 智能分析,自动分段并总结每段内容要点 - 自然语言查询,用描述性文字快速找到目标片段 - 智能剪辑导出,可选择单个
EmbodiedGen 是用于具身智能(Embodied AI)应用的生成式 3D 世界引擎和工具包。能快速生成高质量、低成本且物理属性合理的 3D 资产和交互环境,帮助研究人员和开发者构建具身智能体的测试环境。EmbodiedGen 包含多个模块,如从图像或文本生成 3D 模型、纹理生成、关节物体生成、场景和布局生成等,支持从简单物体到复杂场景的创建。生成的 3D 资产可以直接用于机器人仿真和
Qwen VLo 是通义千问团队推出的多模态统一理解与生成模型。在多模态大模型的基础上进行了全面升级,能“看懂”世界,能基于理解进行高质量的再创造,实现了从感知到生成的跨越。能精准理解图像内容,在此基础上进行一致性和高质量的生成。用户可以通过自然语言指令要求模型对图像进行风格转换、场景重构或细节修饰,模型能灵活响应并生成符合预期的结果。Qwen VLo 支持多语言指令,打破语言壁垒,为全球用户提供
业界首个开源高完成度轻量化通用多智能体产品(JoyAgent-JDGenie) 解决快速构建多智能体产品的最后一公里问题 简介 当前相关开源agent主要是SDK或者框架,用户还需基于此做进一步的开发,无法直接做到开箱即用。我们开源的JoyAgent-JDGenie是端到端的多Agent产品,对于输入的query或者任务,可以直接回答或者解决。例如用户query"给我做一个最
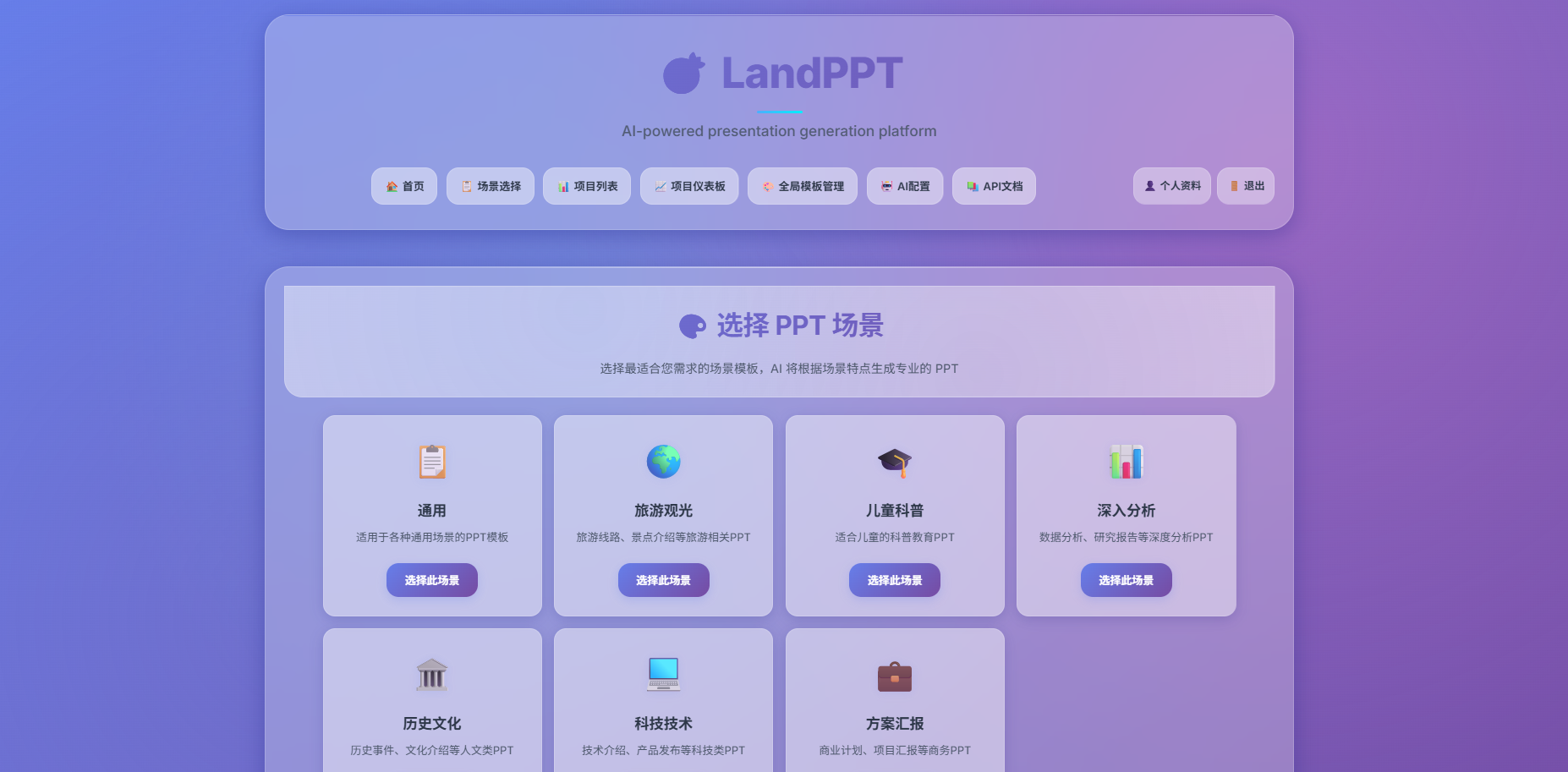
LandPPT 是AI演示文稿生成平台,能将文档内容快速转换为专业的 PPT 演示文稿。LandPPT支持 OpenAI、Claude、Gemini 等多种 AI 模型,兼容 PDF、Word、Markdown 等文件格式,支持智能解析内容,生成结构清晰的大纲和精美的 PPT 页面。平台提供丰富的模板系统和自定义功能,用户基于现代化的 Web 界面进行可视化编辑、实时预览和多格式导出。LandPP
微软开源的一个项目 MarkItDown,这么小的一个工具获得了 7w+ star。 但它干的事儿特别朴素,把各种格式的文件(Word、PDF、Excel、PPT、图片、音频、HTML、JSON、甚至 zip 包)一键变成结构化 Markdown。 是的,保留标题、列表、表格、链接结构的那种 Markdown。 为什么我会觉得这个工具值得讲讲?因为这其实解决了一个我们常常下意识忽略的问题: 在做
上海交通大学等开源了一款半结构化表格问答工具:ST-Raptor,无需微调,准确率超GPT-4o 做文档智能、财务审核、报表自动化、医疗质控、法律合规的可以看看 它通过视觉理解、结构化解析以及语言推理,来解决复杂、不规则表格的问答问题 也就是说可以用它对Excel报表、网站上的表格以及Markdown、csv文件进行问答,比如学术表、财务报表 ST-Raptor先用VLM识别表格整体和单元格内容,
只显示前20页数据,更多请搜索
Showing 169 to 183 of 183 results