关键词 "Helium 10 alternative" 的搜索结果, 共 24 条, 只显示前 480 条
II-Agent:一个用于构建和部署智能体的全新开源框架。II-Agent 是一款开源智能助手,旨在简化和增强跨领域的工作流程。它代表了我们与技术互动方式的重大进步——从被动工具转变为能够独立执行复杂任务的智能系统。作为简易的COZE,Dify平替。 ii-agent开源框架,擅长构建跨多个领域工作流的Agent,能独立执行复杂任务已是Agent标配 其技能覆盖研究与核查、内容生成、数据分析可视
Aurora是微软研究院推出的13亿参数的大气基础模型,基于从海量大气数据中提取有价值信息,用在预测全球天气模式、空气污染和海洋波浪等大气过程。模型用预训练和微调的架构,处理不同分辨率和压力水平的数据。Aurora在多个预测任务中表现出色,包括高分辨率天气预测、空气污染预测和热带气旋轨迹预测,计算速度比传统数值天气模型快约5000倍。模型提高了预测精度,降低计算成本,为应对气候变化和极端天气事件提
Pocket Flow 是极简的 LLM(大型语言模型)框架,仅用 100 行代码实现。具有轻量级、无依赖、无厂商锁定的特点。Pocket Flow支持多Agents、工作流、检索增强生成(RAG)等强大功能,帮助开发者快速构建基于 LLM 的应用程序。基于Agentic Coding范式,AI Agents协助开发,大幅提升开发效率。Pocket Flow 适合希望用极简方式开发 LLM 应用的
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
JoyPix 是专注于数字人和语音合成的AI创作工具。用户可以通过上传照片创建个性化的虚拟形象,支持与虚拟形象进行语音对话。JoyPix 提供自定义虚拟形象,可以根据自己的需求进一步定制虚拟形象的外观。JoyPix支持声音克隆,用户只需上传10秒音频片段,可克隆自己的声音,生成自然流畅的语音输出。JoyPix 的文本转语音功能可以将文本转换为逼真的语音,满足多种语音合成需求。JoyPix提供了虚拟
有言是由魔珐科技推出的一个一站式AIGC视频创作和3D数字人生成平台,通过提供海量超写实3D虚拟人角色,帮助用户无需真人出镜即可制作视频。该平台基于魔珐自研的AIGC技术,支持用户输入文字快速生成3D内容,并提供自定义编辑、字幕、动效、背景音乐等后期包装功能,简化视频制作流程,让创作变得高效而有趣。 有言的主要功能 一站式服务:有言整合了从内容生成到后期制作的全套流程,为用户提供了从开始到
FinRobot是一个超越 FinGPT 范畴的 AI 代理平台,是专为金融应用精心设计的综合解决方案。它集成了多种 AI 技术,超越了单纯的语言模型。这种广阔的视野凸显了平台的多功能性和适应性,能够满足金融行业的多方面需求。 AI代理的概念:AI代理是一种智能体,它使用大型语言模型作为大脑来感知环境、做出决策并执行动作。与传统的人工智能不同,AI代理具有独立思考和利用工具逐步实现既定目标的能力
Unmute 是 Kyutai 推出的低延迟语音交互系统,专注于低延迟语音转文字(Speech-to-Text)和文字转语音(Text-to-Speech)。Unmute 基于先进的 AI 模型,为用户提供实时、高效的语音交互体验。用户基于语音与 AI 进行交流,支持将文字内容快速转换为自然流畅的语音输出。Unmute 的低延迟处理能力,能实现无缝的语音交互。 Unmute的主要功能
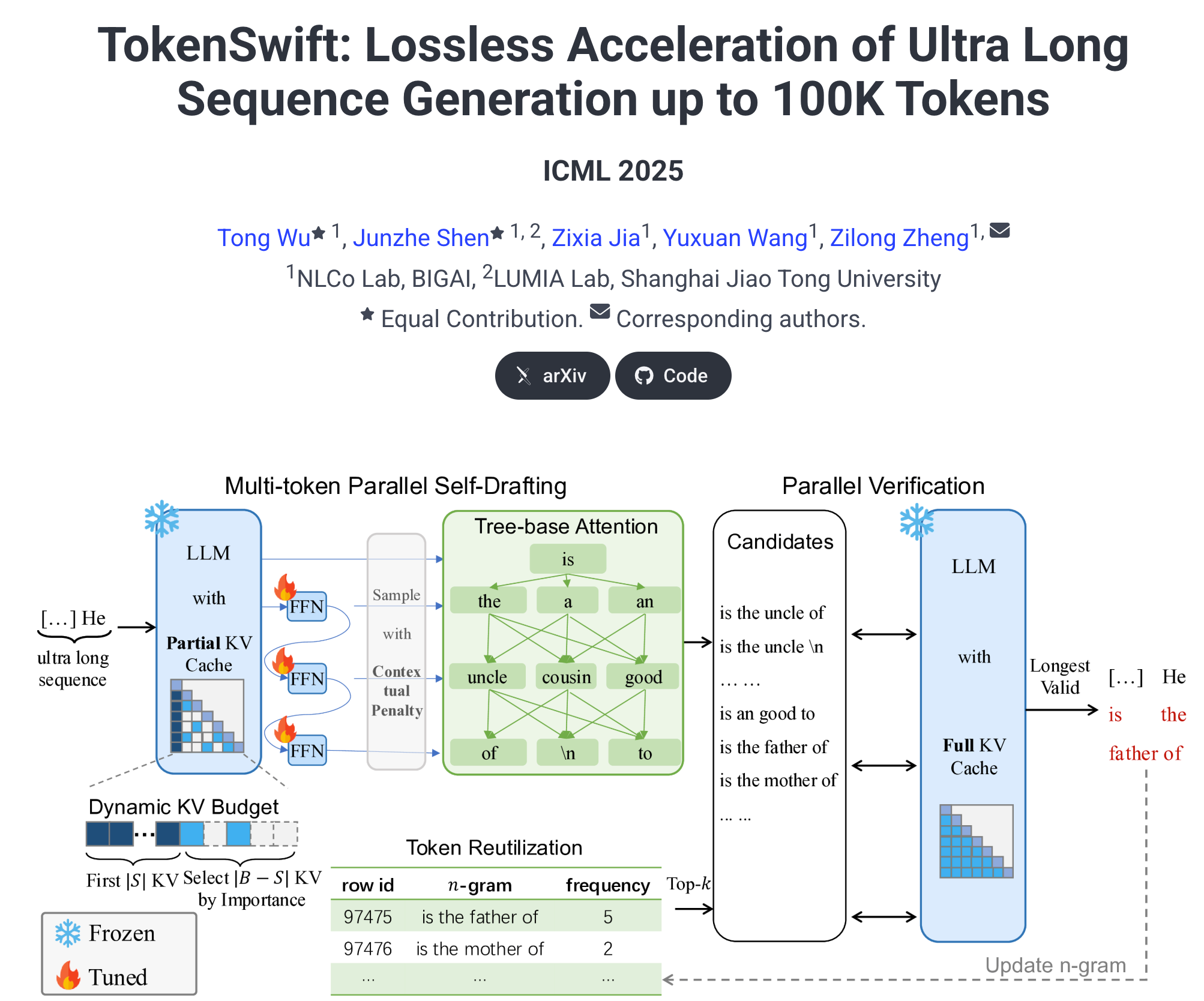
TokenSwift 是北京通用人工智能研究院团队推出的超长文本生成加速框架,能在90分钟内生成10万Token的文本,相比传统自回归模型的近5小时,速度提升了3倍,生成质量无损。TokenSwift 通过多Token生成与Token重用、动态KV缓存更新以及上下文惩罚机制等技术,减少模型加载延迟、优化缓存更新时间并确保生成多样性。支持多种不同规模和架构的模型,如1.5B、7B、8B、14B的MH
# 核心亮点 支持最强开源模型千问3,其代码能力达到业界领先水平,同时支持MCP协议,具备强大的工具调用能力,可以帮助开发者快速开发智能体应用。 全面集成通义灵码智能编码助手(即通义灵码插件)的能力,无需安装插件开箱即用,直接体验高效、智能的编程体验。 自带编程智能体模式,开发者只需描述编码任务,通义灵码便可以自主地进行工程感知、代码检索、执行终端、调用MCP工具等,
Jaaz 是开源的AI设计Agent,本地免费 Lovart 平替项目。具备强大的 AI 设计能力,能智能生成设计提示,批量生成图像、海报、故事板等。Jaaz 支持 Ollama、Stable Diffusion、Flux Dev 等本地图像和语言模型,实现免费的图像生成。用户可以通过 GPT-4o、Flux Kontext 等技术,在对话中编辑图像,进行对象移除、风格转换等操作。Jaaz 提供无
OmniAudio 是阿里巴巴通义实验室语音团队推出的从360°视频生成空间音频(FOA)的技术。为虚拟现实和沉浸式娱乐提供更真实的音频体验。通过构建大规模数据集Sphere360,包含超过10.3万个视频片段,涵盖288种音频事件,总时长288小时,为模型训练提供了丰富资源。OmniAudio 的训练分为两个阶段:自监督的coarse-to-fine流匹配预训练,基于大规模非空间音频资源进行自监
DecipherIt是AI驱动的研究助手工具,基于智能化手段简化和优化研究过程。工具支持将各种主题、链接和文件转化为AI生成的研究笔记本,提供全面的总结、互动问答、音频概述、可视化思维导图及自动化的FAQ生成等功能。基于Bright Data的MCP服务器,DecipherIt突破地理限制和反爬虫检测,获取全球范围内的信息。DecipherIt是多智能体AI框架CrewAI支持高效地分析和整合来自
OpenAudio S1是Fish Audio推出的文本转语音(TTS)模型,基于超过200万小时的音频数据训练,支持13种语言。采用双自回归(Dual-AR)架构和强化学习与人类反馈(RLHF)技术,生成的声音高度自然、流畅,几乎与人类配音无异。模型支持超过50种情感和语调标记,用户可通过自然语言指令灵活调整语音表达。OpenAudio S1支持零样本和少样本语音克隆,仅需10到30秒的音频样本
Qwen3 Reranker是阿里巴巴通义千问团队发布的文本重排序模型,属于Qwen3模型家族。采用单塔交叉编码器架构,输入文本对后输出相关性得分。模型通过多阶段训练范式,基于高质量标注数据和大量合成训练对进行训练,支持超过100种语言,涵盖主流自然语言及多种编程语言。性能表现上,Qwen3 Reranker-8B在MTEB排行榜上取得了72.94的高分,Qwen3 Reranker-0.6B也已
VTable: 不只是高性能的多维数据分析表格,更是行列间创作的方格艺术家!免费,开源,基于Canvas 的 百万数据秒级渲染前端表格组件库 VTable是字节跳动开源可视化解决方案 VisActor 的组件之一。 在现代应用程序中,表格组件是不可或缺的一部分,它们能够快速展示大量数据,并提供良好的可视化效果和交互体验。VTable是一款基于可视化渲染引擎VRender的高性能表格组件库,为用
Seedance 1.0 支持文字与图片输入,可生成多镜头无缝切换的 1080p 高品质视频,且主体运动稳定性与画面自然度较高。 相较 Seed 此前发布的视频生成模型,Seedance 1.0 核心亮点如下: • 原生多镜头叙事能力:支持 2-3 个镜头切换的 10 秒视频生成,可进行远中近景画面切换,叙事能力大幅提升; 在第三方评测榜单 Artificial Analysis 上,See
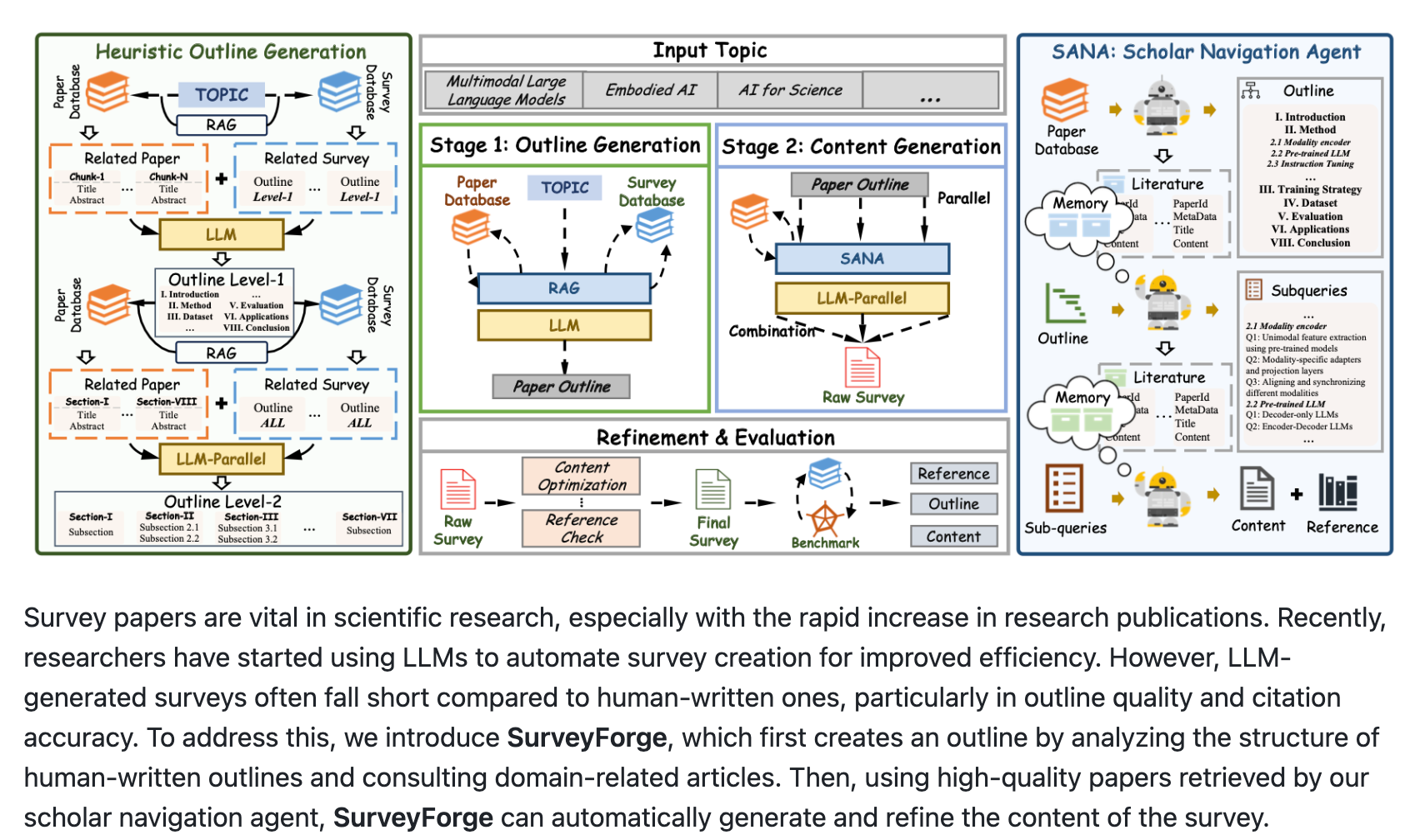
上海人工智能实验室、复旦、上交大等开源的一款自动撰写综述论文的AI工具:SurveyForge 实验结果,SurveyForge的大纲质量接近人工撰写水平,在参考文献质量、大纲质量和内容质量方面优于AutoSurvey等现有方法 生成约64k token的综述成本不到0.5美元,耗时约10分钟 SurveyForge分为两个阶段: 1、生成大纲,通过分析人工撰写的综述文章的大纲结构和参考领域相
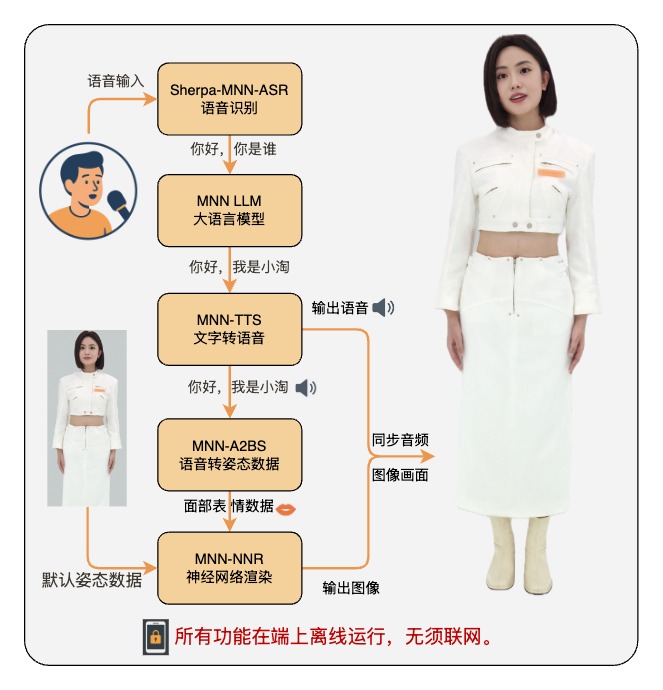
MNN轻量级高性能推理引擎 通用性 - 支持TensorFlow、Caffe、ONNX等主流模型格式,支持CNN、RNN、GAN等常用网络。 高性能 - 极致优化算子性能,全面支持CPU、GPU、NPU,充分发挥设备算力。 易用性 - 转换、可视化、调试工具齐全,能方便地部署到移动设备和各种嵌入式设备中。 什么是 TaoAvatar?它是阿里最新研究
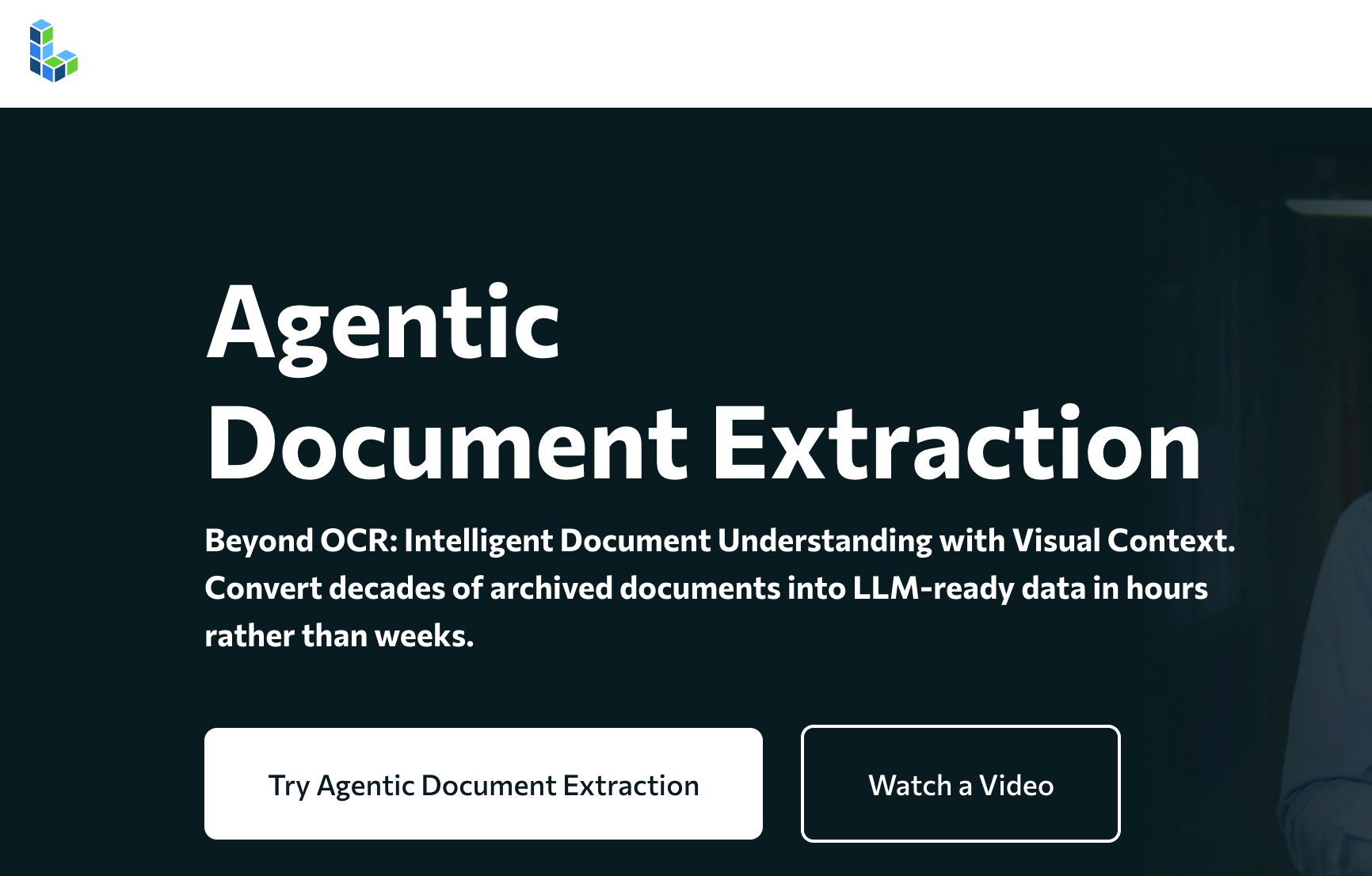
概述 LandingAI Agentic 文档提取API 从视觉复杂的文档(如表格、图片和图表)中提取结构化数据,并返回具有精确元素位置的分层 JSON。 这个 Python 库包装了该 API 以提供: 长文档支持——一次调用即可处理 100 多页 PDF 自动重试/分页——处理并发、超时和速率限制 辅助实用程序——边界框代码片段、可视化调试器等 特征
HiAgent 是字节跳动推出的面向企业级客户的人工智能应用开发平台。帮助企业快速开发大模型应用和智能体(Agent),满足企业对数据安全和隐私的要求。通过低代码开发工具,HiAgent 降低了开发门槛,非技术背景的业务人员也能轻松上手,快速构建和部署 AI 应用。HiAgent 提供了丰富的行业模板和私有化部署选项,能满足不同企业的个性化需求。支持与企业现有系统的深度集成,帮助企业实现复杂流程的
专注于字幕相关功能的视频播放器,例如双字幕、AI 生成字幕、实时翻译、单词查找等! LLPlayer 具有许多普通视频播放器所不具备的语言学习功能。 双字幕:可同时显示两个字幕。支持文本字幕和位图字幕。 AI 生成的字幕(ASR):由OpenAI Whisper提供支持,从任何视频和音频实时自动生成字幕。支持whisper.cpp和fastest-whisper两个引擎。 实时翻译:支
VBench 双榜第一:在 VBench 1.0 和 2.0 都排第一,画面稳定性连 Sora 都要让一分。 1080 p 直接渲染:默认最高 8 秒 1080 p,不用再去 Upscale。 动漫 / LoRA 一键套用:内置 LoRA 效果库,爆款短视频快速起量。 首尾帧接力:把尾帧再丢进去,一镜到底不是事。 内建 48 kHz AI 音效:画面 + 声音一站式搞定,省去到处找 BGM 的麻烦
Code Researcher是微软研究院推出的深度研究Agent工具,专门用于处理大型系统代码库及其提交历史,自动化修复系统代码崩溃问题。通过三个阶段工作:分析(Analysis)、合成(Synthesis)和验证(Validation)。在分析阶段,Code Researcher基于多步推理策略,结合代码语义、模式和提交历史信息,收集上下文并存储在结构化内存中。合成阶段基于收集到的上下文生成修
只显示前20页数据,更多请搜索
Showing 289 to 312 of 368 results