关键词 "Intelligent QA" 的搜索结果, 共 21 条, 只显示前 480 条
A Model Context Protocol server for document Q&A powered by Langflow . It demonstrates core MCP concepts by providing a simple interface to query documents through a Langflow backend.
The intelligent data query plugin under DataFocus that supports multi-round conversations provides plug-and-play ChatBI capabilities.
MCP server for intelligent document chunking and progressive summarization, optimized for Claude context windows.
An intelligent MCP server that serves as a guardian of development knowledge, providing Cline assistants with curated access to latest documentation and best practices across the software development
This project is a Java-based UI automation framework that integrates with Appium and utilizes LLMs (like Claude) to drive intelligent test actions on mobile devices and simulators.
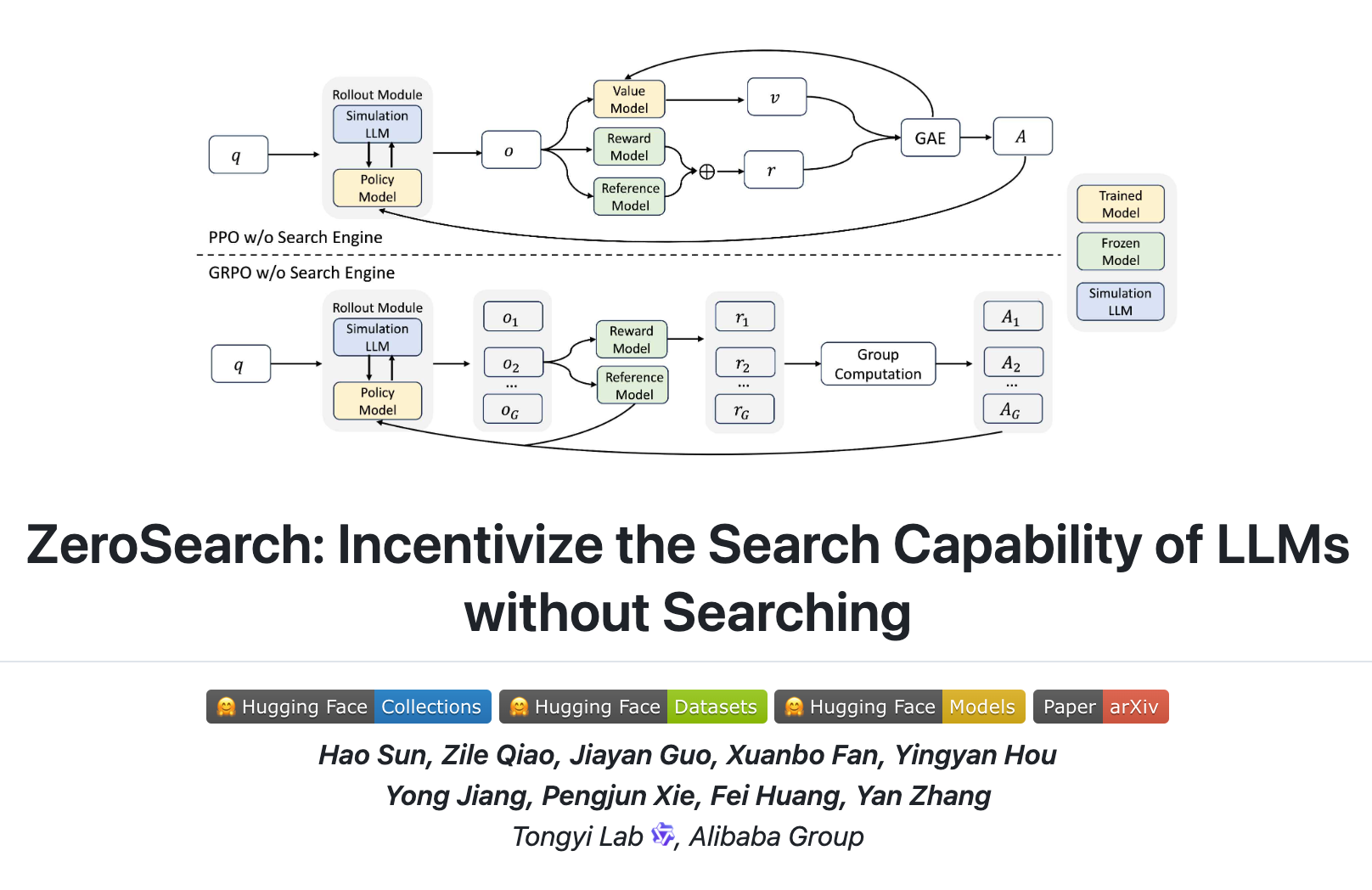
阿里巴巴昨日在 Github 等平台开源了 ZeroSearch 大模型搜索引擎。这是一种无需与真实搜索引擎交互即可激励大模型搜索能力的强化学习框架。 ZeroSearch 主要利用了大模型在大规模预训练过程中积累的丰富知识,将其转化为一个检索模块,能够根据搜索查询生成相关内容。同时,还可以动态控制生成内容的质量,这是传统搜索引擎所不具备的特殊功能。 研究人员在 NQ、TriviaQA、Pop
苹果 FastVLM 的模型让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊! 视觉语言模型的 “成长烦恼” 现在的视觉语
Muyan-TTS,一款低成本、具备良好二次开发支持的模型并完全开源,以方便学术界和小型应用团队的音频技术爱好者。 当前开源的Muyan-TTS版本由于训练数据规模有限,致使其仅对英语语种呈现出良好的支持效果。不过,得益于与之同步开源的详尽训练方法,从事相关行业的开发者能够依据自身实际业务场景,灵活地对Muyan-TTS进行功能升级与定制化改造。 01. H
MSQA(Multi-modal Situated Question Answering)是大规模多模态情境推理数据集,提升具身AI代理在3D场景中的理解与推理能力。数据集包含251K个问答对,覆盖9个问题类别,基于3D场景图和视觉-语言模型在真实世界3D场景中收集。MSQA用文本、图像和点云的交错多模态输入,减少单模态输入的歧义。引入MSNN(Multi-modal Next-step Navi
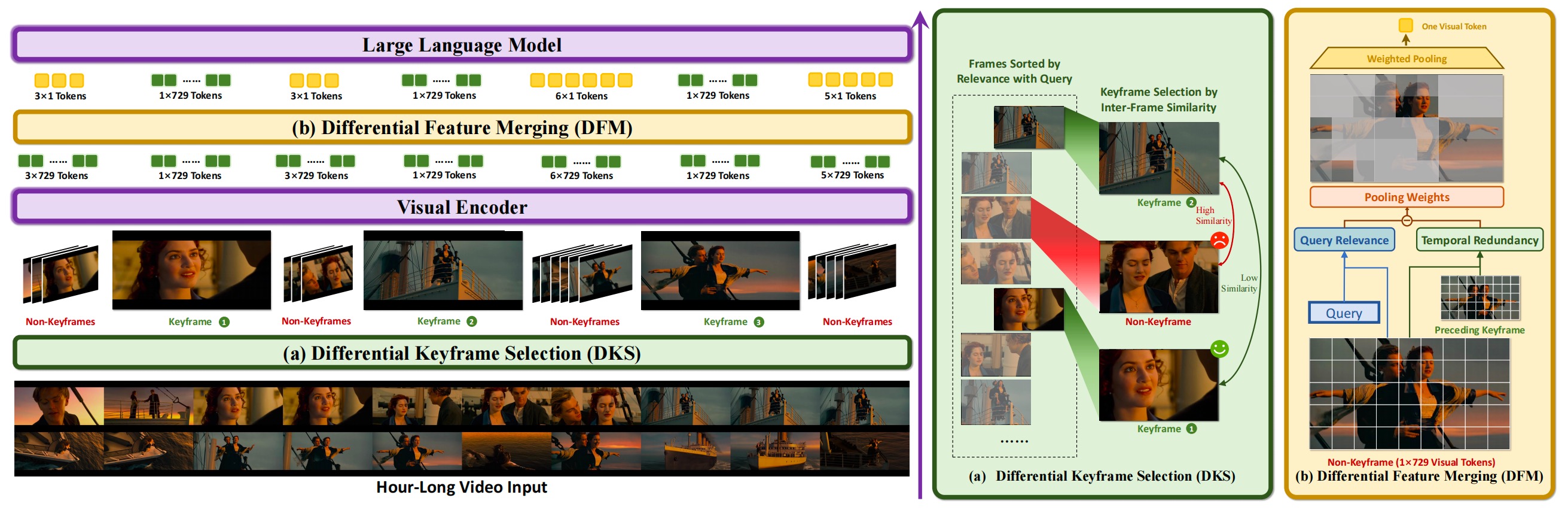
ViLAMP(VIdeo-LAnguage Model with Mixed Precision)是蚂蚁集团和中国人民大学联合推出的视觉语言模型,专门用在高效处理长视频内容。基于混合精度策略,对视频中的关键帧保持高精度分析,显著降低计算成本提高处理效率。ViLAMP在多个视频理解基准测试中表现出色,在长视频理解任务中,展现出显著优势。ViLAMP能在单张A100 GPU上处理长达1万帧(约3小时)
技术:PI3Kα抑制剂 重大并购活动:收购 ZebiAI 及其机器学习-DEL 技术 最新消息:在PIPE融资轮中获得3000万美元 Relay Therapeutics 的 Dynamo 平台集成了一系列计算和实验方法,旨在针对此前难以解决或未得到充分解决的蛋白质靶点进行药物治疗。为了配合自身的技术,Relay 还于 2021 年收购了ZebiAI 及其机器学习-DEL(ML-DE
昆仑万维面向全球市场,同步发布天工超级智能体(Skywork Super Agents)。这款产品采用了AI agent架构和deep research技术,能够一站式生成文档、PPT、表格(excel)、网页、播客和音视频多模态内容。它具有强大的deep research能力,在GAIA榜单上排名全球第一,超过了OpenAI Deep Research和Manus。 天工超级智能体(Skywo
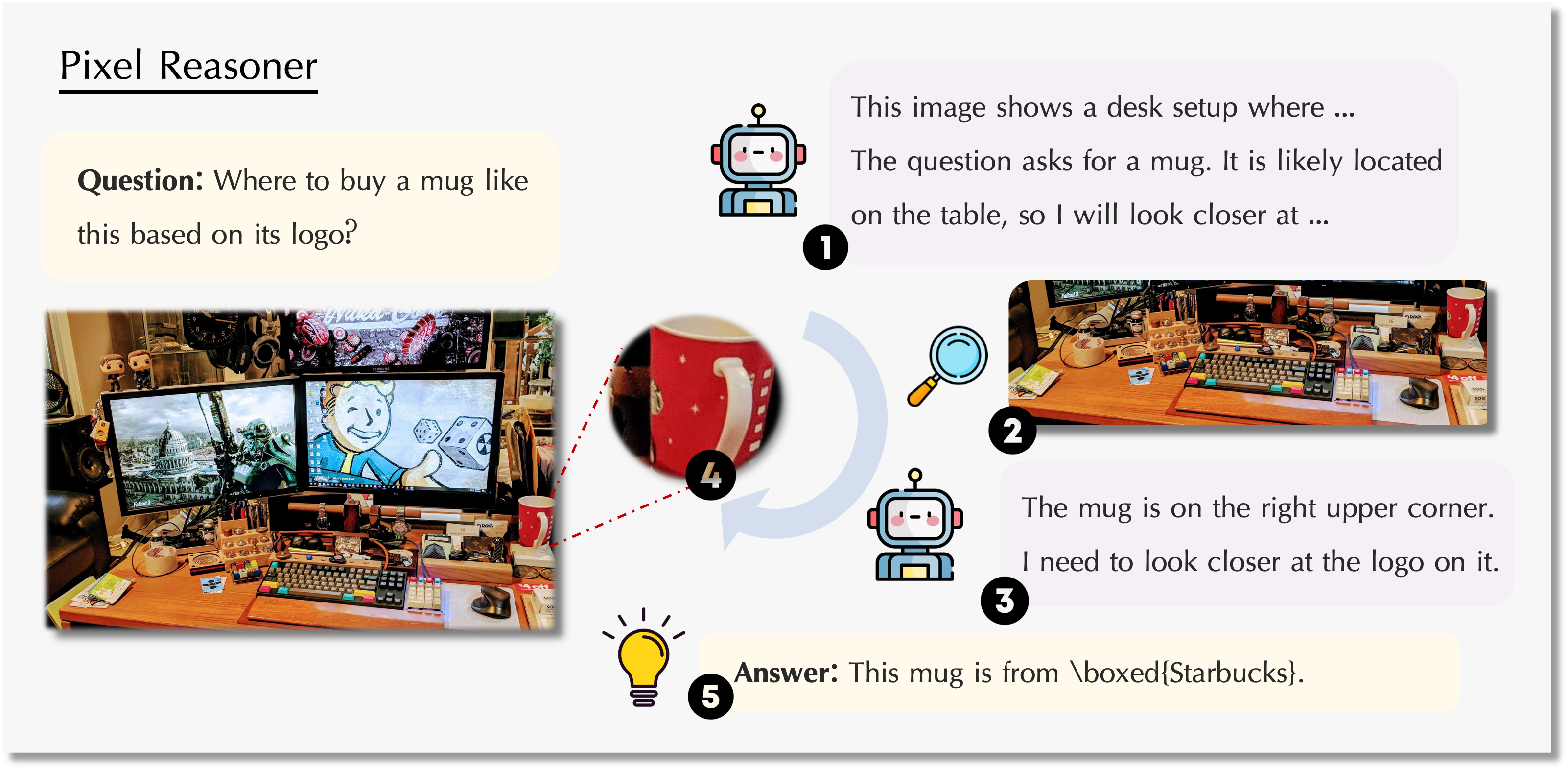
视觉语言模型(VLM),基于像素空间推理增强模型对视觉信息的理解和推理能力。模型能直接在视觉输入上进行操作,如放大图像区域或选择视频帧,更细致地捕捉视觉细节。Pixel Reasoner用两阶段训练方法,基于指令调优让模型熟悉视觉操作,用好奇心驱动的强化学习激励模型探索像素空间推理。Pixel Reasoner在多个视觉推理基准测试中取得优异的成绩,显著提升视觉密集型任务的性能。 Pixel R
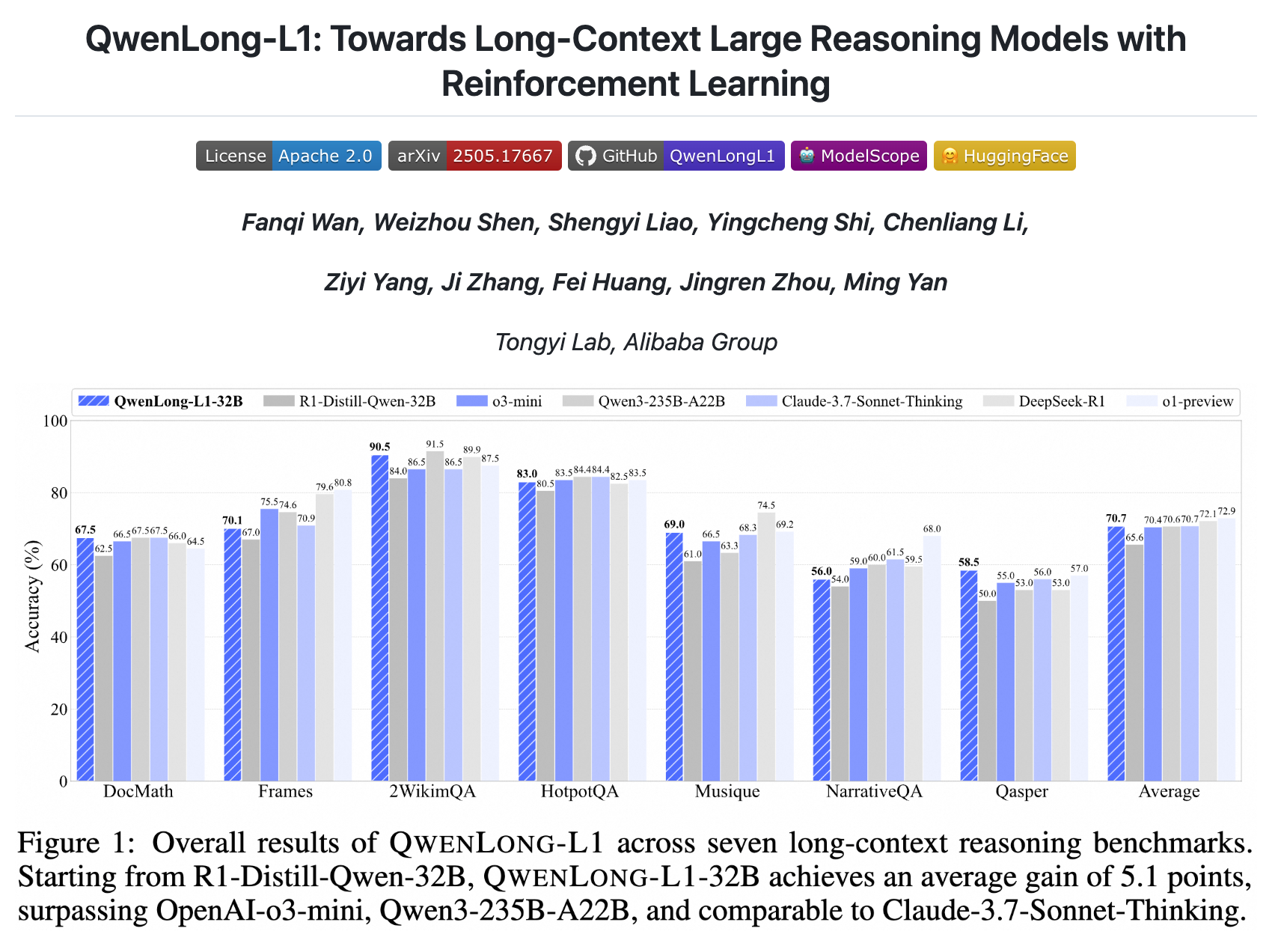
QwenLong-L1-32B 是阿里巴巴集团 Qwen-Doc 团队推出的,基于强化学习训练的首个长文本推理大模型。模型基于渐进式上下文扩展、课程引导的强化学习和难度感知的回顾性采样策略,显著提升在长文本场景下的推理能力。模型在多个长文本文档问答(DocQA)基准测试中表现优异,平均准确率达到了70.7%,超越OpenAI-o3-mini和Qwen3-235B-A22B等现有旗舰模型,且与Cla
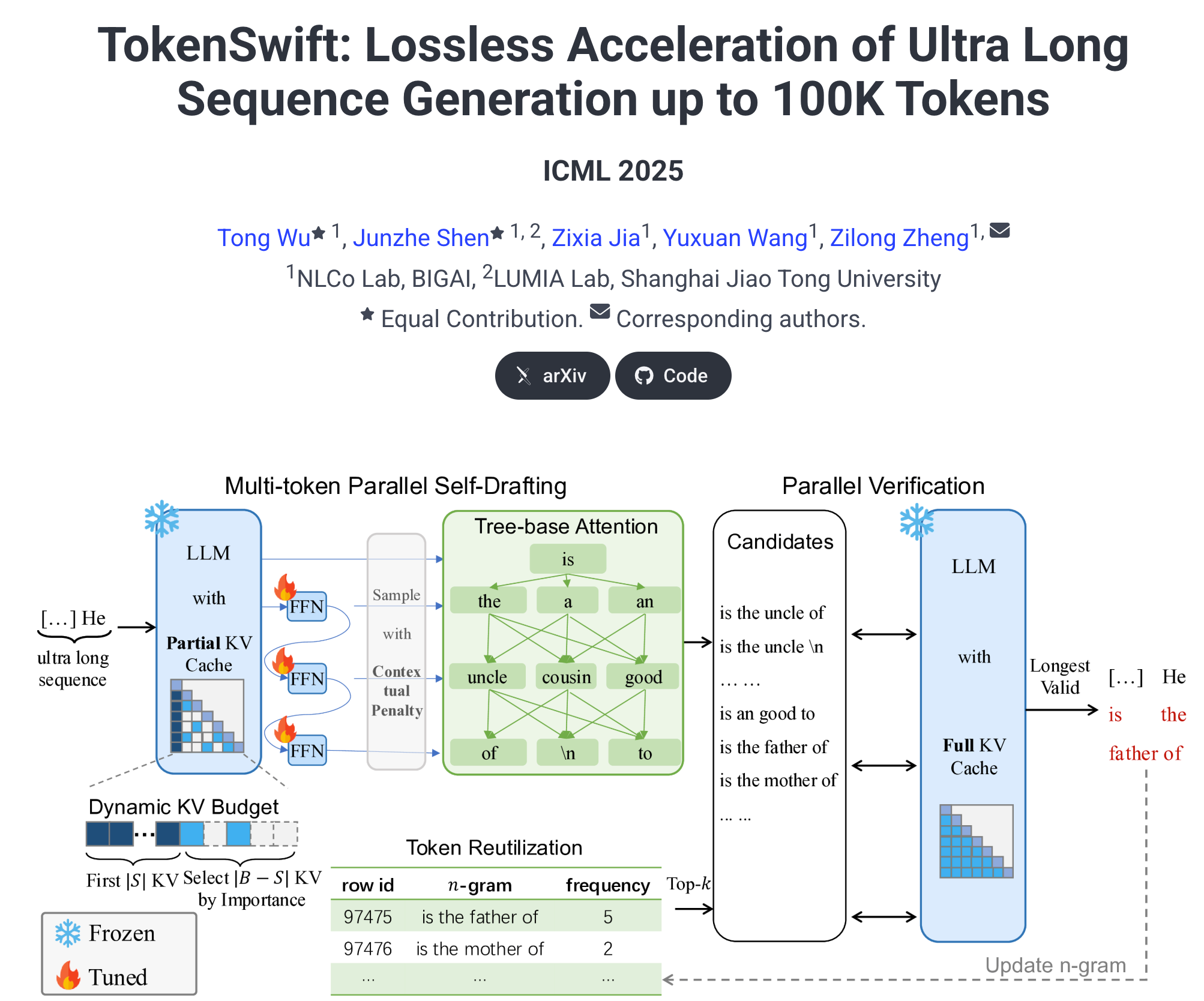
TokenSwift 是北京通用人工智能研究院团队推出的超长文本生成加速框架,能在90分钟内生成10万Token的文本,相比传统自回归模型的近5小时,速度提升了3倍,生成质量无损。TokenSwift 通过多Token生成与Token重用、动态KV缓存更新以及上下文惩罚机制等技术,减少模型加载延迟、优化缓存更新时间并确保生成多样性。支持多种不同规模和架构的模型,如1.5B、7B、8B、14B的MH
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
WebSailor 是阿里通义实验室开源的网络智能体,专注于复杂信息检索与推理任务。通过创新的数据合成方法(如 SailorFog-QA)和训练技术(如拒绝采样微调和 DUPO 算法),在高难度任务中表现出色,在 BrowseComp 等评测中超越多个知名模型,登顶开源网络智能体榜单。WebSailor 的推理重构技术能高效处理复杂任务,生成简洁且精准的推理链。在复杂场景中表现出色,在简单任务中展
Soulmaite is the world's first platform for ultra-realistic relationships with virtual AI companions via Telegram. Our intelligent app delivers personalized conversations, offering emotional companion
Supermaker.ai is designed for creative professionals, designers, and content creators, offering a one-stop AI image generation service. Whether it's generating stunning images from simple text or tran
AIKiss.ai is an AI-powered platform designed to enhance online communication and productivity. It offers intelligent chatbots, virtual assistants, and automation tools to streamline workflows, improve
Youtu-agent 是腾讯优图实验室推出的开源智能体框架,用在构建、运行和评估自主智能体。框架基于开源模型DeepSeek-V3实现领先性能,支持多种模型 API 和工具集成,具备强大的智能体能力,如数据分析、文件处理和深度研究。框架用灵活的架构设计,支持 YAML 配置和自动智能体生成,简化开发流程。Youtu-agent 在 WebWalkerQA 和 GAIA 基准测试中表现出色,适用智
只显示前20页数据,更多请搜索
Showing 265 to 285 of 285 results