关键词 "Multimodal Diffusion Transformer" 的搜索结果, 共 24 条, 只显示前 480 条
MCP server providing semantic memory and persistent storage capabilities for Claude using ChromaDB and sentence transformers.
一款开源的实时AI语音聊天助手:RealtimeVoiceChat,语音听起来相对自然,支持打断 双向语音交互,延迟低,可以实时看到语音转录,以及AI的回复内容 用来构建客服、教育或陪伴等等场景的AI语音助手比较实用 为低延迟交互而构建的复杂客户端-服务器系统: 🎙️捕获:您的声音被您的浏览器捕获。 ➡️流:音频块通过 WebSockets 传输到 Python 后端。 ✍️转
RWKV开源发布了 RWKV7-G1 1.5B 推理模型(Reasoning Model)。模型基于 World v3.5 数据集训练,包含更多小说、网页、数学、代码和 reasoning 数据,总数据为 5.16T tokens。其具备其它同尺寸模型不具备的推理能力和任务能力,同时还支持现实世界 100+ 种语言。 在实际测试中,RWKV7-G1 1.5B 模型的推理逻辑性较强,能够完成有难度的
苹果 FastVLM 的模型让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊! 视觉语言模型的 “成长烦恼” 现在的视觉语
昆仑万维正式开源(17B+)Matrix-Game大模型,即Matrix-Zero世界模型中的可交互视频生成大模型。Matrix-Game是Matrix系列在交互式世界生成方向的正式落地,也是工业界首个开源的10B+空间智能大模型,它是一个面向游戏世界建模的交互式世界基础模型,专为开放式环境中的高质量生成与精确控制而设计。 空间智能作为AI时代的重要前沿技术,正在重塑我们与虚拟世界的
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
VACE(Video Creation and Editing)是阿里巴巴通义实验室推出的一站式视频生成与编辑框架。基于整合多种视频任务(如参考视频生成、视频到视频编辑、遮罩编辑等)到一个统一模型中,实现高效的内容创作和编辑功能。VACE的核心在于Video Condition Unit(VCU),将文本、图像、视频和遮罩等多种模态输入整合为统一的条件单元,支持多种任务的灵活组合。开源的 Wan2
WorldMem 是南洋理工大学、北京大学和上海 AI Lab 推出的创新 AI 世界生成模型。模型基于引入记忆机制,解决传统世界生成模型在长时序下缺乏一致性的关键问题。在WorldMem中,智能体在多样化场景中自由探索,生成的世界在视角和位置变化后能保持几何一致性。WorldMem 支持时间一致性建模,模拟动态变化(如物体对环境的影响)。模型在 Minecraft 数据集上进行大规模训练,在真实
Sketch2Anim 是爱丁堡大学联合Snap Research、东北大学推出的自动化框架,能将2D草图故事板直接转换为高质量的3D动画。基于条件运动合成技术,用3D关键姿势、关节轨迹和动作词精确控制动画的生成。框架包含两个核心模块,多条件运动生成器和2D、3D神经映射器。Sketch2Anim能生成自然流畅的3D动画,支持交互式编辑,极大地提高动画制作的效率和灵活性。 Sketch2Anim
Seedance 1.0 lite是火山引擎推出的豆包视频生成模型的小参数量版本,支持文生视频和图生视频两种生成方式,支持生成5秒或10秒、480p或720p分辨率的视频。具备影视级视频生成质量,能精细控制人物外貌、衣着、表情动作等细节,支持360度环绕、航拍、变焦等多种运镜技术,生成的视频画质细腻、美感十足。模型广泛用在电商广告、娱乐特效、影视创作、动态壁纸等领域,能有效降低制作成本和周期。
BILIVE 是基于 AI 技术的开源工具,专为 B 站直播录制与处理设计。工具支持自动录制直播、渲染弹幕和字幕,支持语音识别、自动切片精彩片段,生成有趣的标题和风格化的视频封面。BILIVE 能自动将处理后的视频投稿至 B 站,综合多种模态模型,兼容超低配置机器,无需 GPU 即可运行,适合个人用户和小型服务器使用。 1. Introduction Have you notice
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引入对比监督信号,进一步优化模型训练。SuperEdit不需要额外的视觉语言模型(VLM)或预训练任务,仅依赖高质量的监督信号,在多个基准测试中实现显著的性能提升。 Super
FunGPT 是基于 InternLM2.5 系列大模型开发的开源项目,专为情感调节设计。具备两大核心功能:甜言蜜语模式和犀利怼语模式。甜言蜜语模式能用温暖的话语和独特的夸奖提升用户心情,犀利怼语模式以幽默风趣的方式帮助用户释放压力。FunGPT 采用 1.8B 系列轻量化模型,结合 AWQ 量化技术,既节省 GPU 内存又提升推理速度。 FunGPT的主要功能 甜言蜜语模式:当用户情绪低
角井(北京)生物技术有限公司是一家专注于应用人工智能和组学大数据等创新技术加速新药发现和验证的新兴企业。公司自成立以来,将人工智能算法团队、资深大分子药物研发团队及高通量湿实验平台有机结合在一起,全力打造了AI赋能的新一代大分子药物设计平台,用于开发全新的药物及治疗方案。公司聚焦在前端的药物发现到POC验证区间,和合作伙伴共同变革大分子创新药物研发的既有范式。 角井生物拥有独到的超大数据集驱动的
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
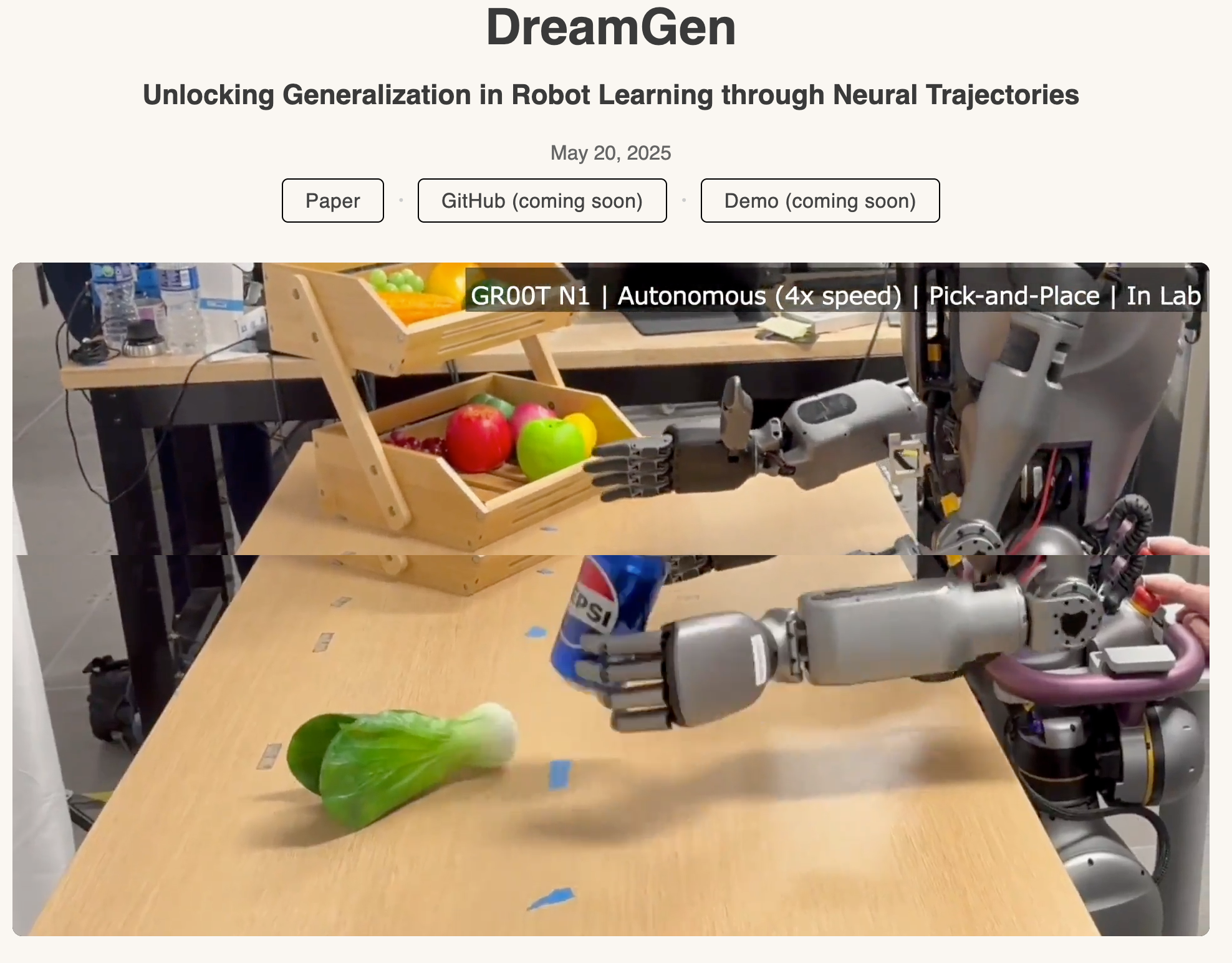
DreamGen是英伟达推出的创新的机器人学习技术,基于AI视频世界模型生成合成数据,让机器人能在梦境中学习新技能。DreamGen仅需少量现实视频数据,能生成大规模逼真的训练数据,实现机器人在新环境中的行为泛化和环境泛化。DreamGen的四步流程包括微调视频世界模型、生成虚拟数据、提取虚拟动作以及训练下游策略。DreamGen让机器人在没有真实世界数据支持的情况下,凭文本指令完成复杂任务,显著
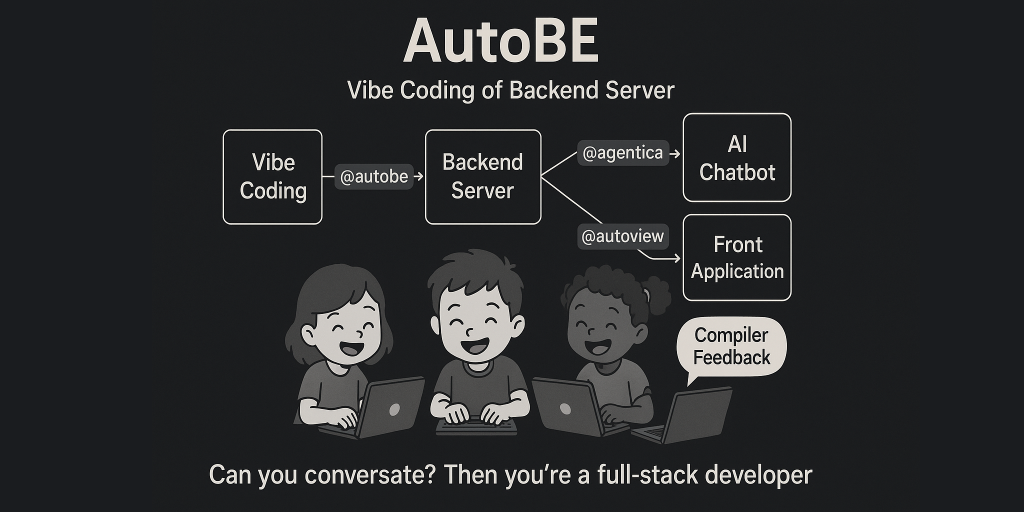
AutoBE 是 AI 驱动的后端服务器代码生成工具,通过用户描述需求自动生成高质量的后端代码。基于 TypeScript、NestJS、Prisma 和 Postgres 等技术栈构建,强调“氛围编码”(Vibe Coding),通过持续的用户反馈和编译器反馈来迭代优化代码。AutoBE 结合瀑布模型和螺旋模型的优点,确保代码的可靠性和安全性。 AutoBE的主要功能 需求分析(An
DMind是DMind研究机构发布的专为Web3领域优化的大型语言模型。针对区块链、去中心化金融和智能合约等场景深度优化,使用Web3数据微调采用RLHF技术对齐。DMind在Web3专项基准测试中表现优异,性能远超一线通用模型,推理成本仅为主流大模型的十分之一。包含DMind-1和DMind-1-mini两个版本,前者适合复杂指令和多轮对话,后者轻量级,响应快、延迟低,适合代理部署和链上工具。
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
Aurora是微软研究院推出的13亿参数的大气基础模型,基于从海量大气数据中提取有价值信息,用在预测全球天气模式、空气污染和海洋波浪等大气过程。模型用预训练和微调的架构,处理不同分辨率和压力水平的数据。Aurora在多个预测任务中表现出色,包括高分辨率天气预测、空气污染预测和热带气旋轨迹预测,计算速度比传统数值天气模型快约5000倍。模型提高了预测精度,降低计算成本,为应对气候变化和极端天气事件提
Gemini Diffusion是谷歌推出的实验性文本扩散模型。与传统自回归模型逐词生成文本不同,基于逐步细化噪声生成输出,能快速迭代纠正错误,让Gemini Diffusion在文本生成任务中表现出色,具备快速响应、生成更连贯文本和迭代细化等能力。Gemini Diffusion性能在外部基准测试中与更大规模模型相当,速度更快。Gemini Diffusion作为实验性演示提供,用户加入等待名单
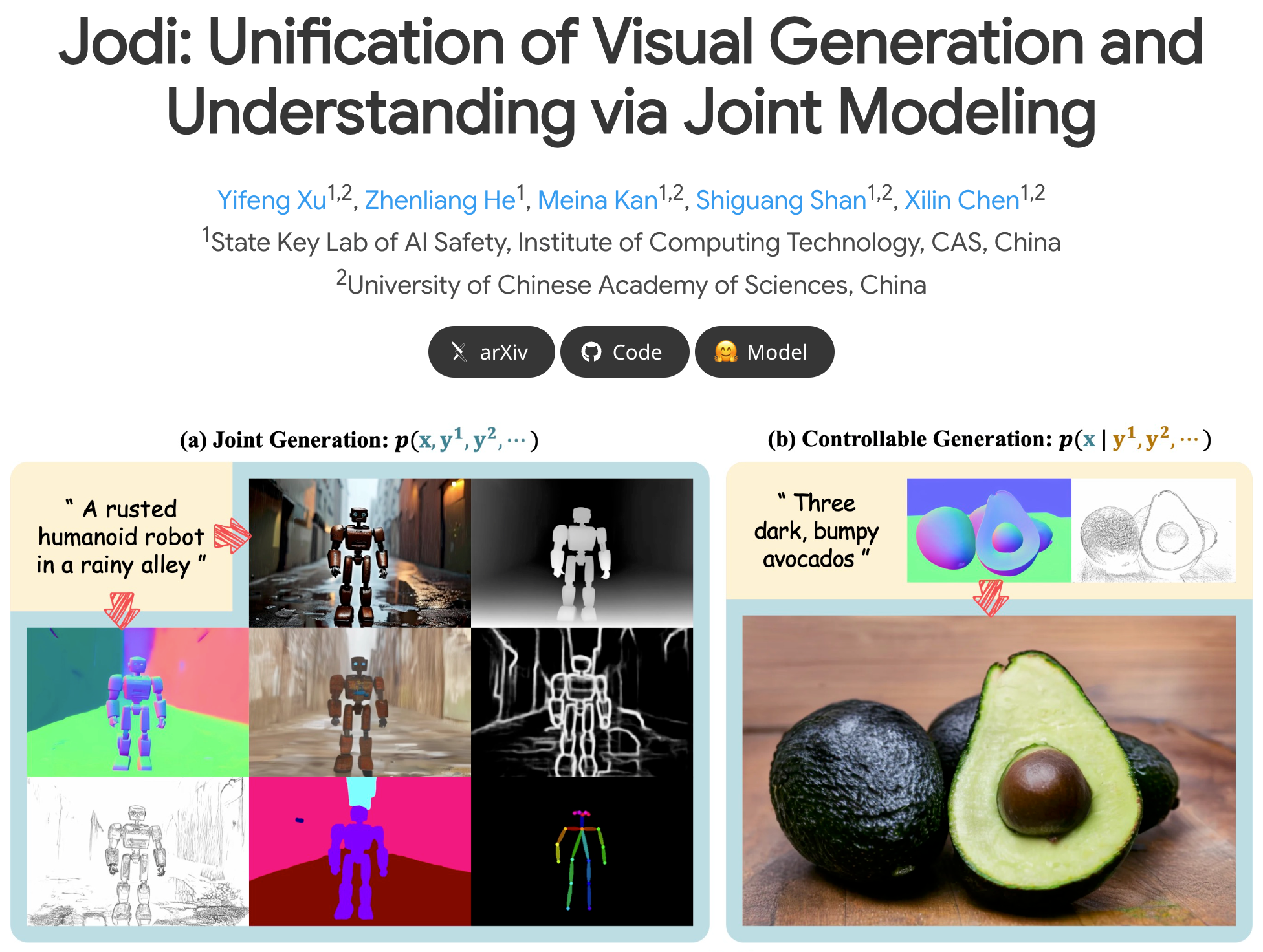
Jodi是中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,将视觉生成与理解统一起来。Jodi基于线性扩散Transformer和角色切换机制,执行联合生成(同时生成图像和多个标签)、可控生成(基于标签组合生成图像)及图像感知(从图像预测多个标签)三种任务。Jodi用包含20万张高质量图像和7个视觉域标签的Joint-1.6M数据集进行训练。Jodi在生成
Jaaz 是开源的AI设计Agent,本地免费 Lovart 平替项目。具备强大的 AI 设计能力,能智能生成设计提示,批量生成图像、海报、故事板等。Jaaz 支持 Ollama、Stable Diffusion、Flux Dev 等本地图像和语言模型,实现免费的图像生成。用户可以通过 GPT-4o、Flux Kontext 等技术,在对话中编辑图像,进行对象移除、风格转换等操作。Jaaz 提供无
SmolVLA 是 Hugging Face 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。 SmolVLA的主要功能 多模态输入处理:SmolVLA 能处理多种输入,包括多幅图像、语言指令以及
只显示前20页数据,更多请搜索
Showing 217 to 240 of 253 results