关键词 "Sci Space" 的搜索结果, 共 19 条, 只显示前 480 条
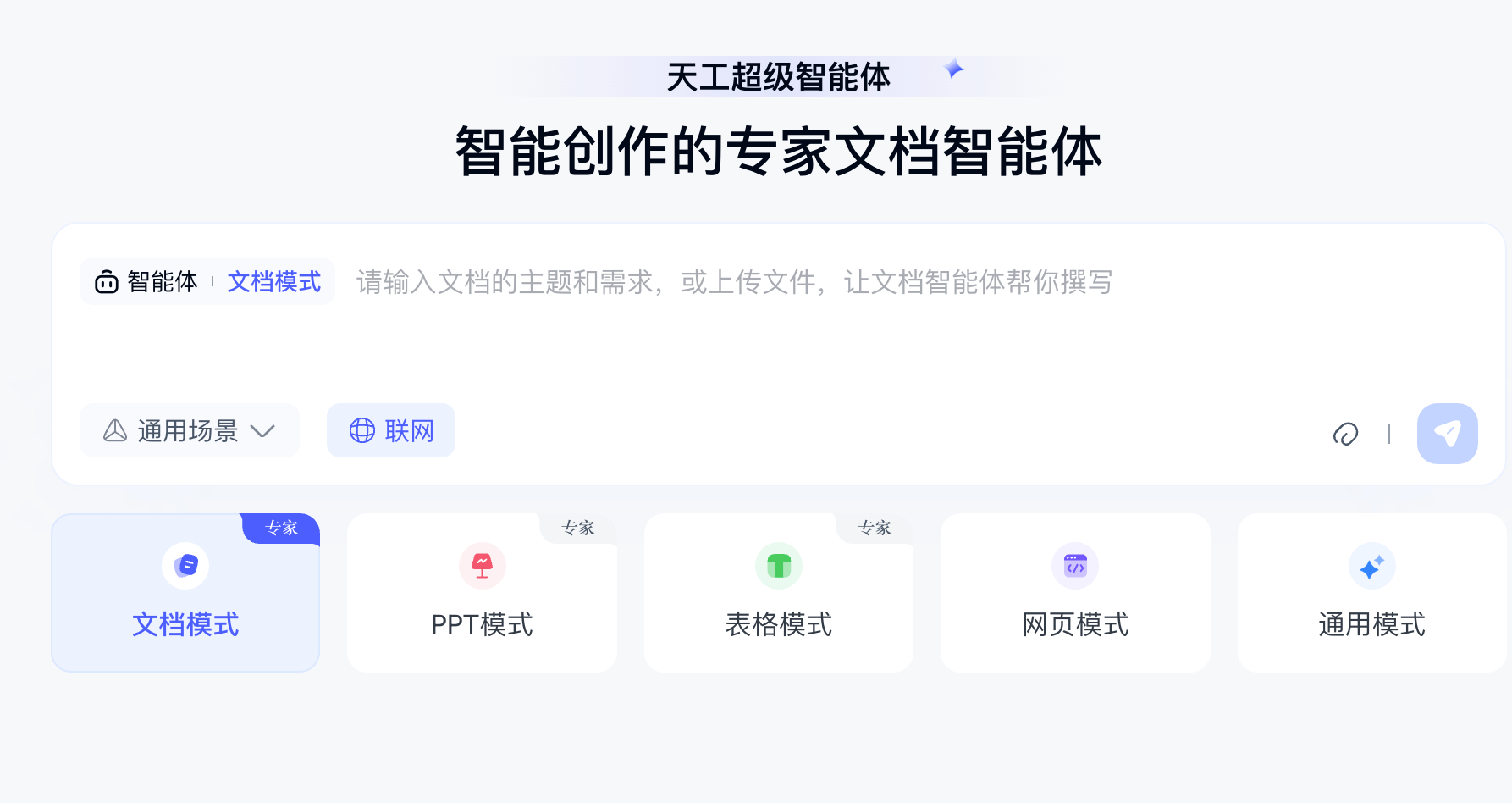
昆仑万维面向全球市场,同步发布天工超级智能体(Skywork Super Agents)。这款产品采用了AI agent架构和deep research技术,能够一站式生成文档、PPT、表格(excel)、网页、播客和音视频多模态内容。它具有强大的deep research能力,在GAIA榜单上排名全球第一,超过了OpenAI Deep Research和Manus。 天工超级智能体(Skywo
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
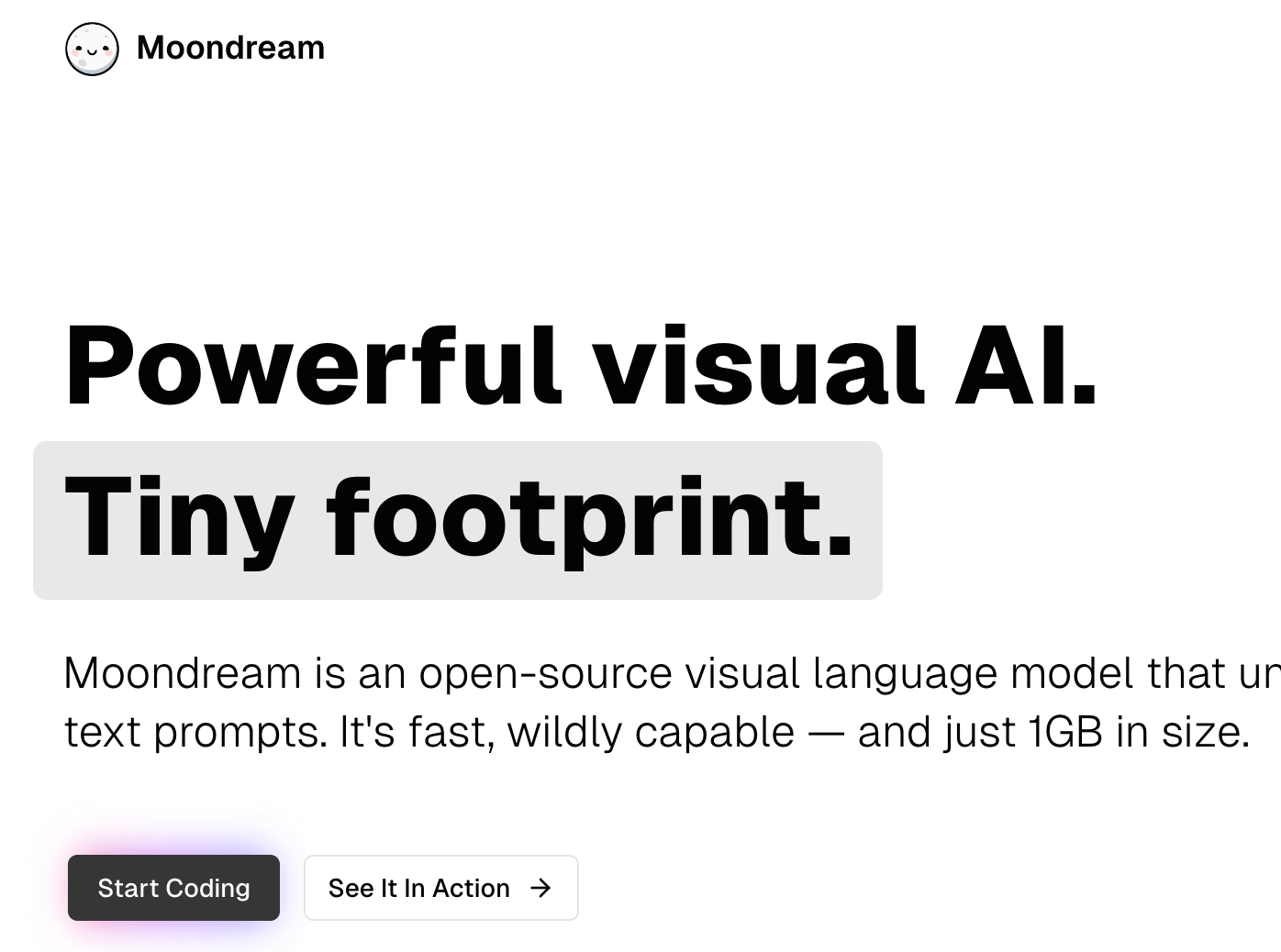
Moondream是一个免费开源的小型的人工智能视觉语言模型,虽然参数量小(Moondream1仅16亿,Moondream2为18.6亿)但可以提供高性能的视觉处理能力,可在本地计算机甚至移动设备或 Raspberry Pi 上运行,能够快速理解和处理输入的图像信息并对用户提出的问题进行解答。该模型由开发人员vikhyatk推出,使用SigLP、Phi-1.5和LLaVa训练数据集和模型权重初始
mPLUG-Owl3是阿里巴巴推出的通用多模态AI模型,专为理解和处理多图及长视频设计。在保持准确性的同时,显著提升了推理效率,能在4秒内分析完2小时电影。模型采用创新的Hyper Attention模块,优化视觉与语言信息的融合,支持多图场景和长视频理解。mPLUG-Owl3在多个基准测试中达到行业领先水平,其论文、代码和资源已开源,供研究和应用。 mPLUG-Owl3的主要功能 多
II-Agent:一个用于构建和部署智能体的全新开源框架。II-Agent 是一款开源智能助手,旨在简化和增强跨领域的工作流程。它代表了我们与技术互动方式的重大进步——从被动工具转变为能够独立执行复杂任务的智能系统。作为简易的COZE,Dify平替。 ii-agent开源框架,擅长构建跨多个领域工作流的Agent,能独立执行复杂任务已是Agent标配 其技能覆盖研究与核查、内容生成、数据分析可视
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
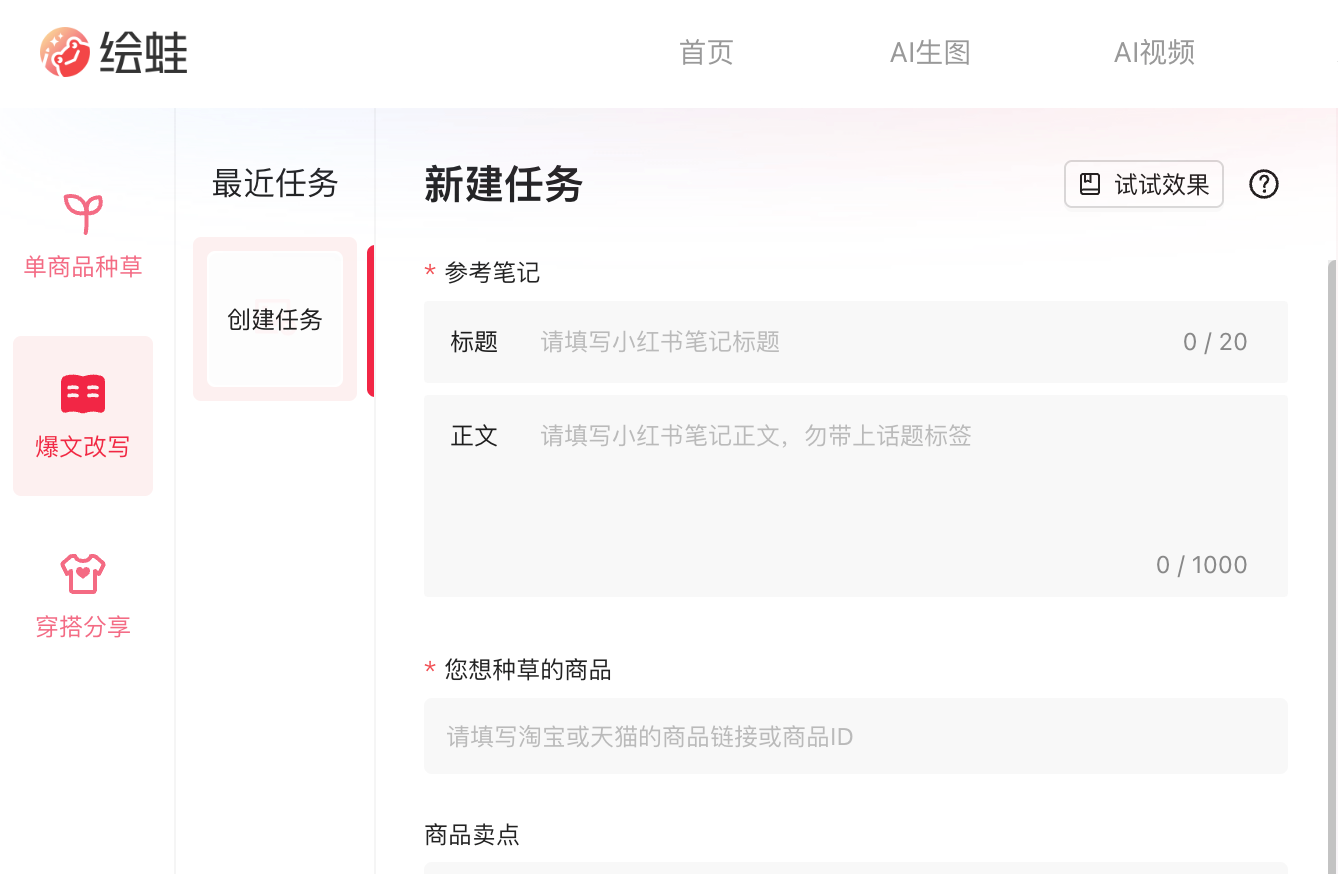
绘蛙AI文案是阿里巴巴推出的种草文案写作工具,支持用户通过输入商品链接或ID,提供商品卖点、人设、笔记话题等信息,绘蛙AI文案将自动生成适合商品的营销文案,如种草文案、爆文改写等,提高商品/种草笔记的吸引力和销量。绘蛙AI文案是电商从业者、达人KOL的文案创作好帮手。 绘蛙AI文案的主要功能 单商品种草:专注于为单个商品创作吸引人的推广文案,帮助提升商品的吸引力和销量。 爆文改写:提供将
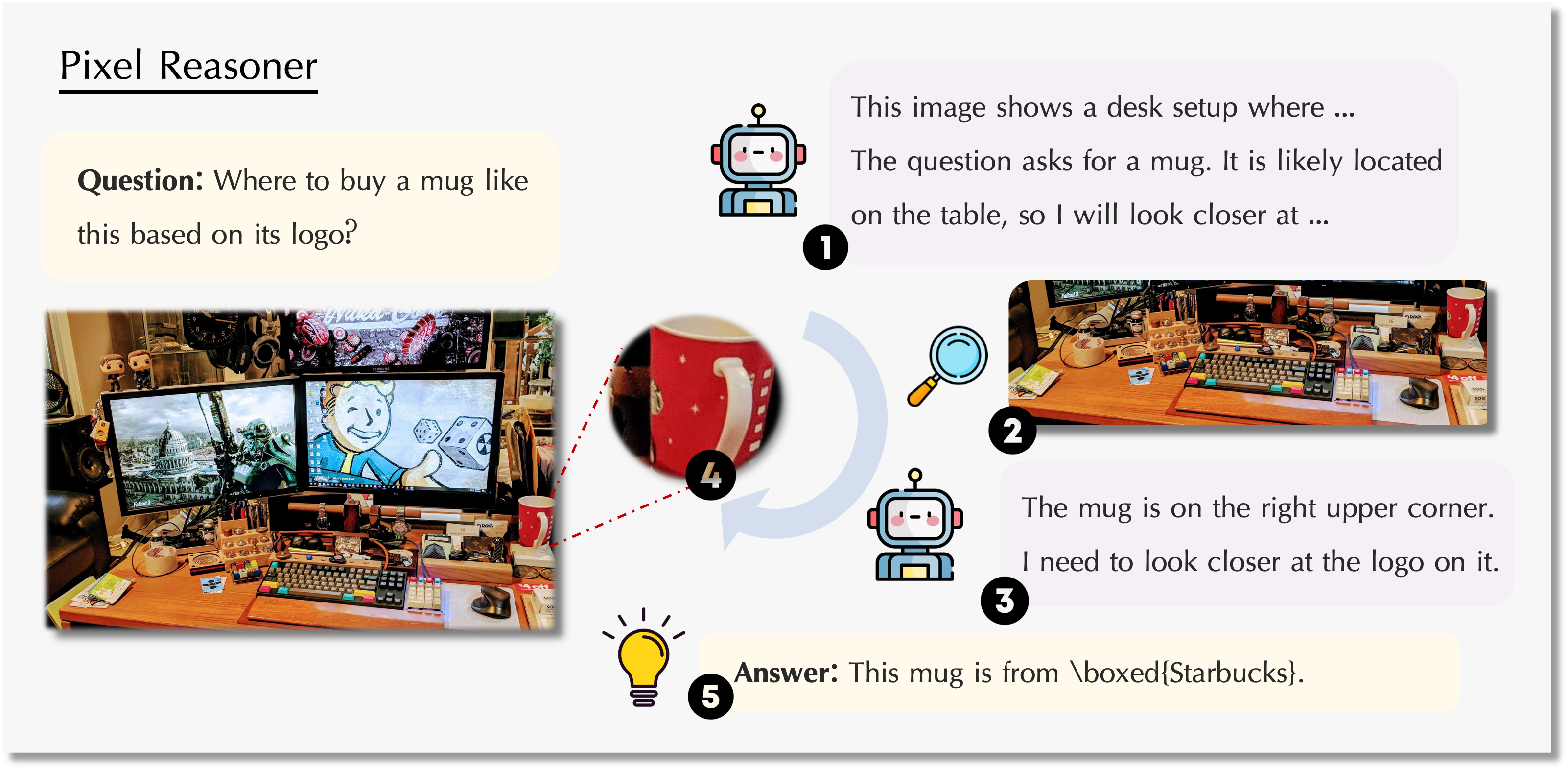
视觉语言模型(VLM),基于像素空间推理增强模型对视觉信息的理解和推理能力。模型能直接在视觉输入上进行操作,如放大图像区域或选择视频帧,更细致地捕捉视觉细节。Pixel Reasoner用两阶段训练方法,基于指令调优让模型熟悉视觉操作,用好奇心驱动的强化学习激励模型探索像素空间推理。Pixel Reasoner在多个视觉推理基准测试中取得优异的成绩,显著提升视觉密集型任务的性能。 Pixel R
MoonCast 是零样本播客生成系统,从纯文本源合成自然的播客风格语音。通过长上下文语言模型和大规模语音数据训练,能生成几分钟长的播客音频,支持中文和英文。生成语音的自然性和连贯性,在长音频生成中能保持高质量。MoonCast 使用特定的LLM提示来生成播客脚本,通过语音合成模块将其转换为最终的播客音频。用户可以通过简单的命令和预训练权重快速生成播客。 MoonCast的项目地址 项目官
Dive3D是北京大学和小红书公司合作推出的文本到3D生成框架。框架基于分数的匹配(Score Implicit Matching,SIM)损失替代传统的KL散度目标,有效避免模式坍塌问题,显著提升3D生成内容的多样性。Dive3D在文本对齐、人类偏好和视觉保真度方面表现出色,在GPTEval3D基准测试中取得优异的定量结果,证明了在生成高质量、多样化3D资产方面的强大能力。 Dive3D的项目
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
OmniGen2 是北京智源人工智能研究院推出的开源多模态生成模型。能根据文本提示生成高质量图像,支持指令引导的图像编辑,比如修改背景或人物特征等。OmniGen2 采用双组件架构,结合视觉语言模型(VLM)和扩散模型,实现对多种生成任务的统一处理。优势在于开源免费、高性能以及强大的上下文生成能力,适用于商业、创意设计和研究开发等场景。 OmniGen2的项目地址 项目官网:https:/
1.VALID-Mol 是一个系统性框架,通过集成快速分子工程、领域特定微调和自动化化学验证,显著提高了 LLM 生成分子的可靠性,有效性从 3% 提高到 83%。 2. 与典型的 LLM 应用程序(这些应用程序会产生看似合理但化学上无效的输出)不同,VALID-Mol 使用化学信息学工具验证每个生成分子的语法和语义,从而确保其科学严谨性。 3. 该框架最引人注目的创新在于其系统化的快速分子工
Gradio 是一个开源的 Python 库,简化机器学习模型的演示和共享过程。支持开发者基于简单的代码快速创建出友好的网页界面,任何人、任何地点能轻松使用机器学习模型。Gradio 支持多种输入和输出组件,如文本、图像、音频等,适用于演示、教学和原型开发。Gradio 支持服务器端渲染(SSR),使应用更快地在浏览器中加载。Gradio提供与 Hugging Face Spaces 更紧密的集成
ToonComposer 是香港中文大学、腾讯 PCG ARC 实验室和北京大学研究人员共同推出的生成式 AI 工具,几秒能将草图转化成专业级动画。ToonComposer基于生成式后关键帧技术,将传统动画制作中的中间帧生成和上色环节整合为自动化过程,仅需一个草图和一个上色参考帧,能生成高质量的动画视频。工具支持稀疏草图注入和区域控制,让艺术家能准控制动画效果,大幅减少人工工作量,提高创作效率,为
AI招聘
BodyVisualizer.org is a fitness - focused platform centered on body visualization, boasting advanced 3D technology. Function - wise, it offers real - time 3D body modeling for instant accurate body mo
PaddleOCR-VL是百度飞桨团队开源的多模态文档解析模型,参数量仅0.9B,专为低算力设备优化。在国际权威评测OmnidocBench V1.5中以92.6分登顶全球第一,超越GPT-4o等主流模型。模型采用双阶段架构:PP-DocLayoutV2负责版面分析,PaddleOCR-VL-0.9B完成内容识别,支持109种语言,能精准处理表格、公式、图表等复杂元素,输出结构化Markdown/
TrainCalc is a free online platform offering accurate, science-based fitness calculators for BMI, TDEE, body fat, macros, and more. Built for clarity and speed, it helps you understand your body metri
只显示前20页数据,更多请搜索
Showing 457 to 475 of 475 results