关键词 "computer vision datasets" 的搜索结果, 共 24 条, 只显示前 480 条
MCP Server using OpenRouter models to get descriptions for images
Mirror of
The Opera Omnia MCP server provides programmatic access to the rich collection of JSON datasets from the Opera Omnia project. It enables developers, storytellers, and AI applications to easily access,
A Model Context Protocol (MCP) server that provides secure access to Azure Cosmos DB datasets. Enables Large Language Models (LLMs) to safely query and analyze data through a standardized interface.
server that shows trending tokens and integrates Grok, xAI image understanding and vision (interpreted as a vision-capable AI), and Claude's computer use capabilities.
An MCP server for interacting with the Financial Datasets stock market API.
An MCP server for accessing data from Data.gov, providing tools and resources for interacting with government datasets.
A Model Context Protocol (MCP) server that provides access to the DBLP computer science bibliography database for Large Language Models.
An MCP server that provides image recognition 👀 capabilities using Anthropic and OpenAI vision APIs
A Model Context Protocol (MCP) server that provides secure, read-only access to BigQuery datasets. Enables Large Language Models (LLMs) to safely query and analyze data through a standardized interfac
AI agent that controls computer with OS-level tools, MCP compatible, works with any model
MoLing is a computer-use and browser-use based MCP server. It is a locally deployed, dependency-free office AI assistant.
Knowledge management system that allows you to build a persistent semantic graph from conversations with AI assistants. All knowledge is stored in standard Markdown files on your computer, giving you
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引入对比监督信号,进一步优化模型训练。SuperEdit不需要额外的视觉语言模型(VLM)或预训练任务,仅依赖高质量的监督信号,在多个基准测试中实现显著的性能提升。 Super
Moondream是一个免费开源的小型的人工智能视觉语言模型,虽然参数量小(Moondream1仅16亿,Moondream2为18.6亿)但可以提供高性能的视觉处理能力,可在本地计算机甚至移动设备或 Raspberry Pi 上运行,能够快速理解和处理输入的图像信息并对用户提出的问题进行解答。该模型由开发人员vikhyatk推出,使用SigLP、Phi-1.5和LLaVa训练数据集和模型权重初始
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
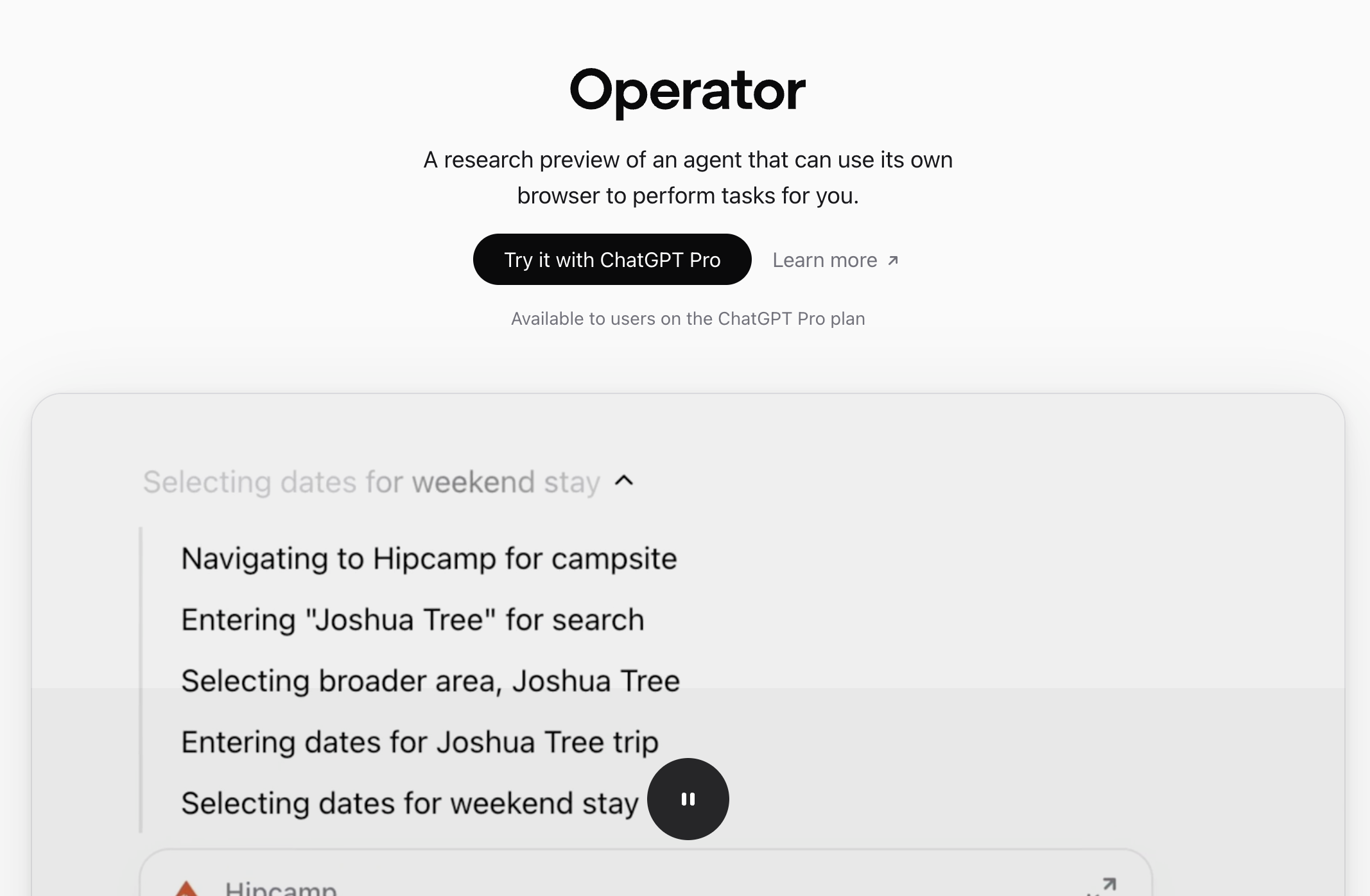
Operator是OpenAI推出的首款AI智能体。能像人类一样操作网页浏览器的AI工具,可以自动完成各种在线任务,如预订餐厅、购买机票、填写表单等。Operator基于Computer-Using Agent(CUA)的新模型驱动,模型结合了GPT-4o的视觉能力和强化学习的高级推理能力。通过屏幕截图“观察”网页,使用虚拟鼠标和键盘进行操作。Operator目前处于研究预览阶段,仅对美国的Cha
银河通用发布全球首个产品级端到端具身 FSD 大模型 ——TrackVLA,一款具备纯视觉环境感知、语言指令驱动、可自主推理、具备零样本(Zero-Shot)泛化能力的具身大模型。 TrackVLA 是银河通用推出的产品级导航大模型,纯视觉环境感知、自然语言指令驱动、端到端输出语言和机器人动作,是一个由仿真合成动作数据训练的“视觉-语言-动作”(Vision-Language-Action, V
CreateVision AI 是AI图像生成平台,平台融合 Flux.1 Dev 和 GPT-Image-1 两大顶级模型,为用户提供开源与闭源技术路线的极致体验。平台支持用户将创意想法瞬间转化为高质量图像,轻松生成逼真照片、卡通、插画和抽象艺术。支持样式、颜色、光照、构图的 4D 精准控制,满足专业创作需求。CreateVision AI 生成的图像能用在商业用途,无数量限制。 官方网站:h
ComputerX是基于人工智能的AI Agent工具,通过自然语言指令帮助用户自动化处理各种计算机任务,提升工作效率。能处理多种任务,如旅行规划、数据分析、报告生成、网页应用创建等,支持文本、表格、图像和代码等多种输出格式。ComputerX基于 AI 技术整合来自多个在线来源的信息,提供全面且准确的结果,保持任务执行过程的透明性。 ComputerX的官网地址 官网地址: https:
智元机器人推出行业首个机器人世界模型开源平台Genie Envisioner(GE)。GE基于约3000小时真实机器人操控视频数据,整合未来帧预测、策略学习与仿真评估,形成闭环架构,使机器人实现从“看”到“想”再到“动”的端到端推理与执行。 链接: Project page:https://genie-envisioner.github.io/ Arxiv:https://a
只显示前20页数据,更多请搜索
Showing 241 to 264 of 265 results