关键词 "gpt-4 vision" 的搜索结果, 共 24 条, 只显示前 480 条
Mirror of
server that shows trending tokens and integrates Grok, xAI image understanding and vision (interpreted as a vision-capable AI), and Claude's computer use capabilities.
🧠 MCP server implementing RAT (Retrieval Augmented Thinking) - combines DeepSeek's reasoning with GPT-4/Claude/Mistral responses, maintaining conversation context between interactions.
An MCP server that provides image recognition 👀 capabilities using Anthropic and OpenAI vision APIs
v0 / lovable / Bolt 的开源平替方案! Dyad 是一款免费开源的本地化 AI 应用开发工具,兼容 Windows 和 Mac 双平台。支持使用自有 API 密钥灵活调用主流 AI 模型(包括 Gemini、GPT-4.1、Claude 等),内置数据库与身份验证系统可快速构建完整应用。 在 Dyad 中完全启动您的全栈应用程序 Dyad 的Supabase 集成(包括
Napkin主打简洁的AI思维记录工具,通过自动结构化与可视化功能,让想法捕捉更及时,方便用户快速迭代并与团队共享创意灵感。 Napkin诞生于前Google工程师Pramod Sharma与Jerome Scholler对商业沟通效率的革命性思考。创始团队曾成功打造儿童AI教育品牌Osmo,在长达十年的产品开发过程中,他们深刻体会到文字主导的沟通方式对创意的束缚——冗长的文档与PPT不仅降低信
ContextGem:轻松从文档中提取 LLM ContextGem 是一个免费的开源 LLM 框架,它可以让您以最少的代码更轻松地从文档中提取结构化数据和见解。 💎 为什么选择 Contex
Nexus-Gen:图像理解、生成和编辑的统一模型,开源届的GPT-4o平替 待办事项 发布训练和推理代码。 发布模型检查点。 发布技术报告。 发布训练数据集。 什么是Nexus-Gen Nexus-Gen 是一个统一模型,它将 LLM 的语言推理能力与扩散模型的图像合成能力协同起来。为了对齐 LLM 和扩散模型的嵌入
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
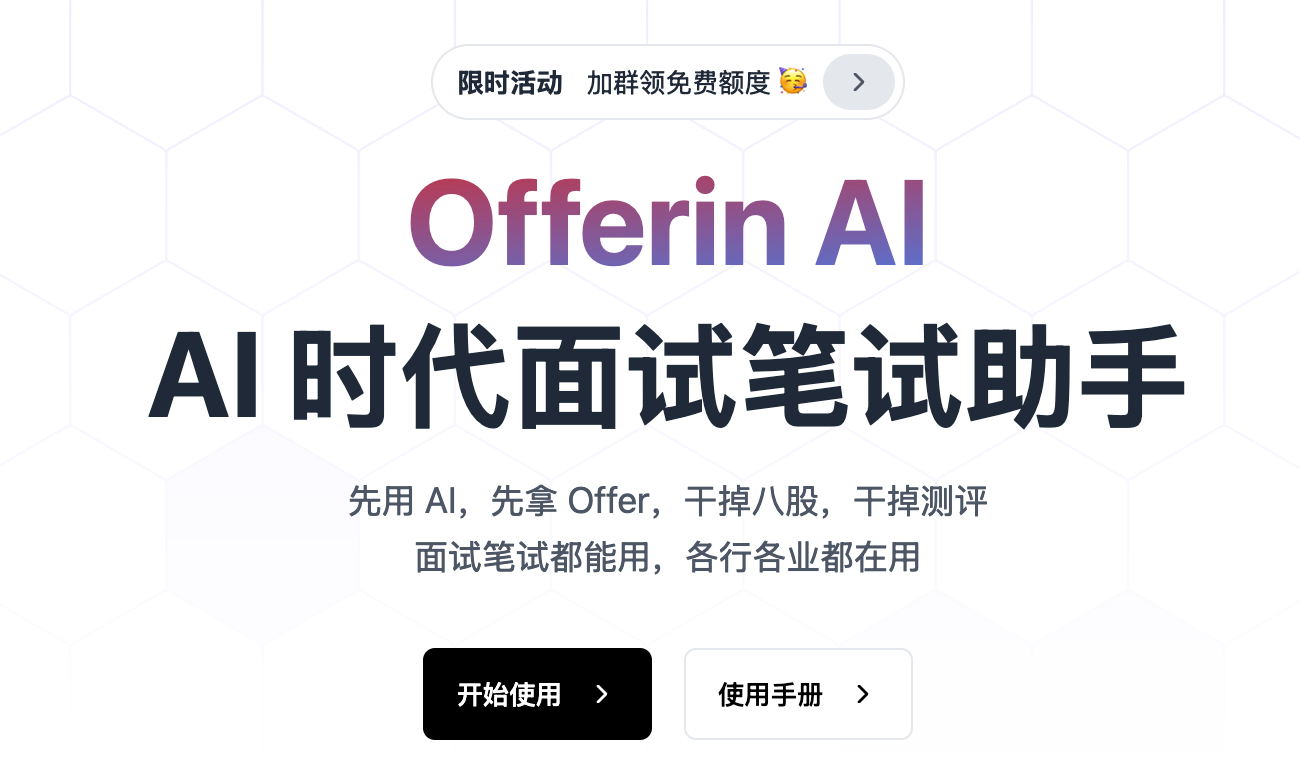
Offerin AI 是专为求职者设计的智能面试辅助工具。基于先进的语音识别技术,实时捕捉面试问题,迅速提供精准答案。基于GPT-4技术,Offerin AI 能秒级响应,同时支持联网搜索确保信息的准确性。具备编程模式,帮助解决算法和编程问题,双设备互连功能,无需担心平台监控。Offerin AI 支持多种操作系统和会议软件,适用于程序员、产品经理等多种职位的面试和笔试。 🚀产品亮点
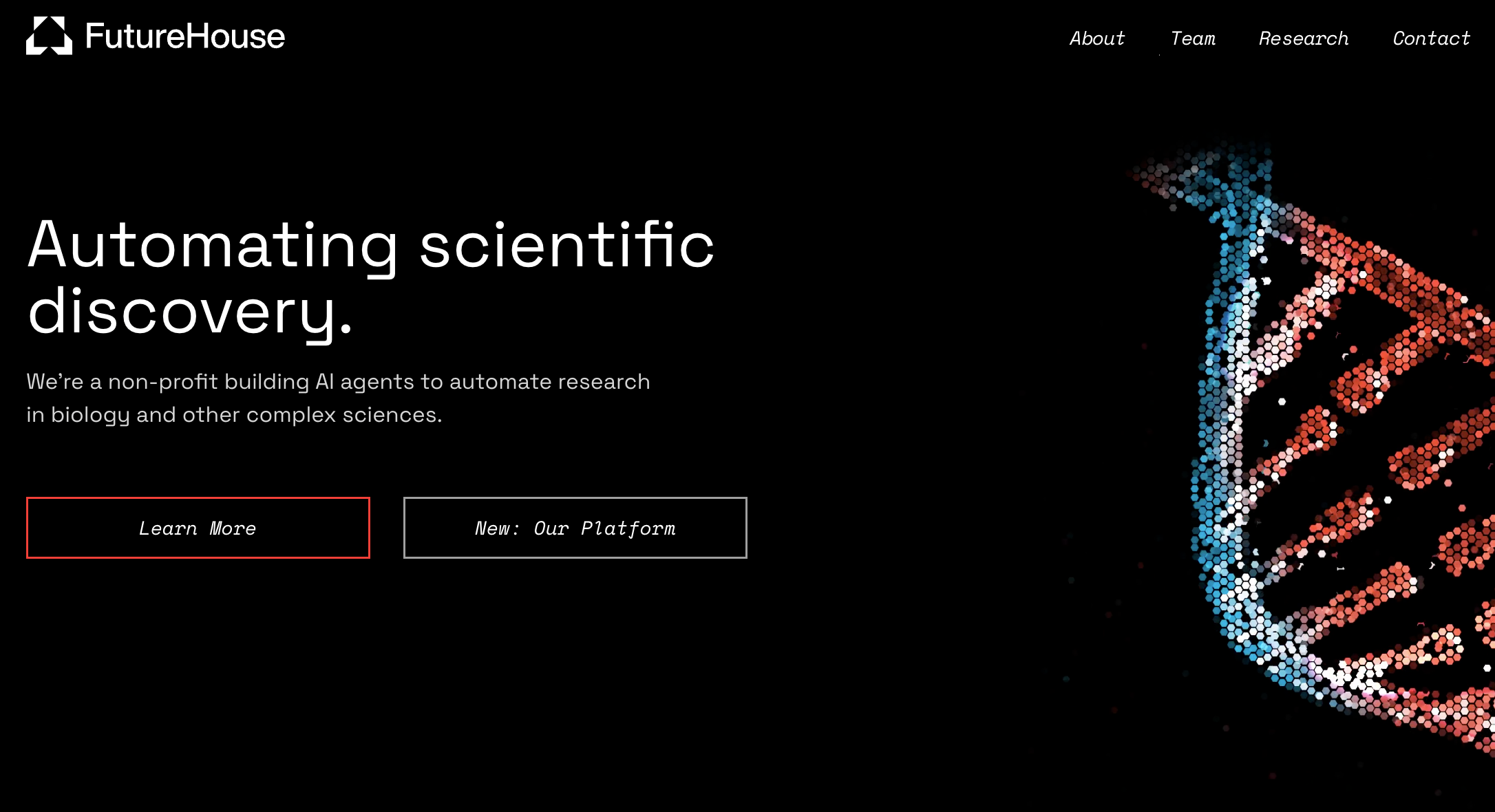
FutureHouse是指一个非营利组织,它刚刚发布了四个超人类的AI科学家智能体,包括Crow(乌鸦)、Falcon(猎鹰)、Owl(猫头鹰)和Phoenix(凤凰)。这些智能体专门用于科学研究,已经通过了严格的基准测试,在搜索精度和准确性上超越了目前顶级的搜索模型,如o3-mini、GPT-4.5、Claude-3.7。此外,它们在直接文献搜索任务中,检索和综合能力比博士水平的研究人员更高。这
类似 Manus 但基于 Deepseek R1 Agents 的本地模型。 Manus AI 的本地替代品,它是一个具有语音功能的大语言模型秘书,可以 Coding、访问你的电脑文件、浏览网页,并自动修正错误与反省,最重要的是不会向云端传送任何资料。采用 DeepSeek R1 等推理模型构建,完全在本地硬体上运行,进而保证资料的隐私。 Features: 100% 本机运行:
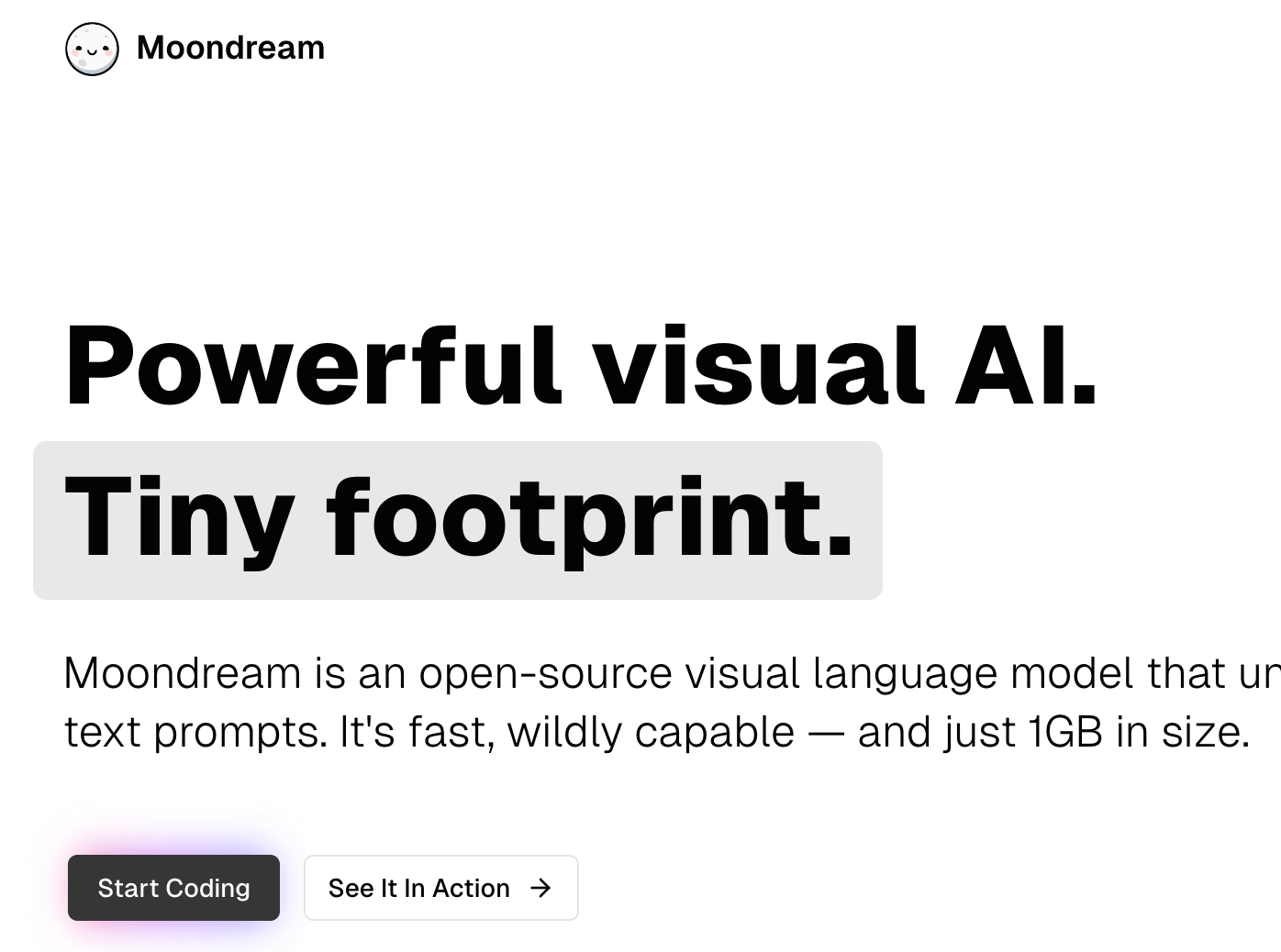
Moondream是一个免费开源的小型的人工智能视觉语言模型,虽然参数量小(Moondream1仅16亿,Moondream2为18.6亿)但可以提供高性能的视觉处理能力,可在本地计算机甚至移动设备或 Raspberry Pi 上运行,能够快速理解和处理输入的图像信息并对用户提出的问题进行解答。该模型由开发人员vikhyatk推出,使用SigLP、Phi-1.5和LLaVa训练数据集和模型权重初始
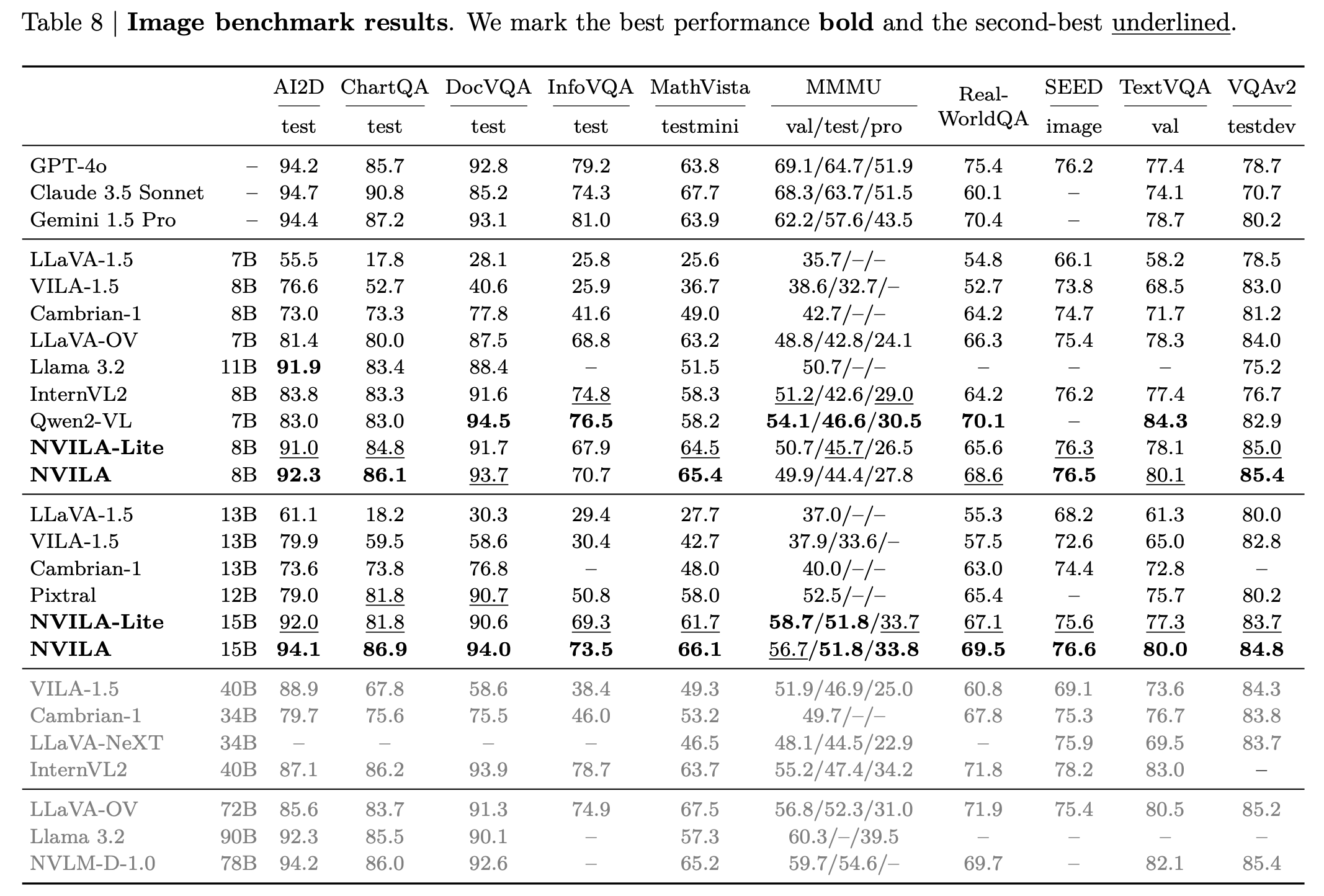
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等
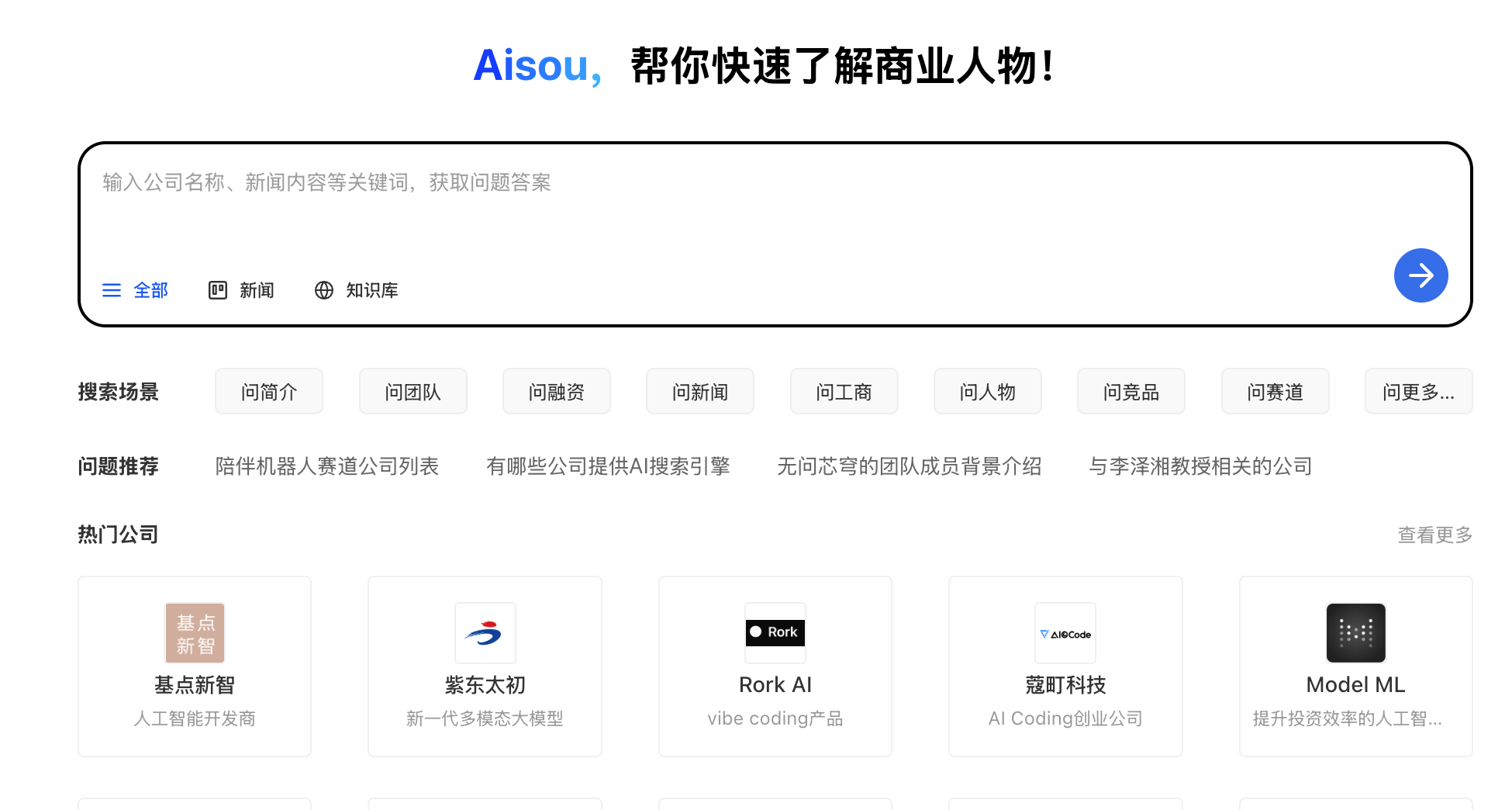
Aisou.ai 是专注于商业信息的智能搜索问答平台,基于大语言模型(LLM)和检索增强生成(RAG)技术,结合商业信息数据库,为用户提供精准、实时的商业数据查询与分析服务。通过智能算法和自然语言处理技术,能快速解析用户需求,精准回答涉及商业信息的数据查询,大大节省了企业和个人在信息搜索上的时间和精力。Aisou.ai 支持用户以自然语言形式提出商业相关问题,系统即时生成准确回答,提供深入的商业数
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
Sapling AI 是检测文本是否由AI生成的免费在线工具,用户可以通过上传文本或直接粘贴内容进行检测,工具基于机器学习算法分析文本特征,识别出由 AI 模型(如 ChatGPT 和 GPT-4)生成的内容。Sapling 能在短至 50 个字的文本中进行检测,将 AI 生成的部分高亮显示,同时提供整体的 AI 生成内容比例。 Sapling AI Content Detector的主要功能
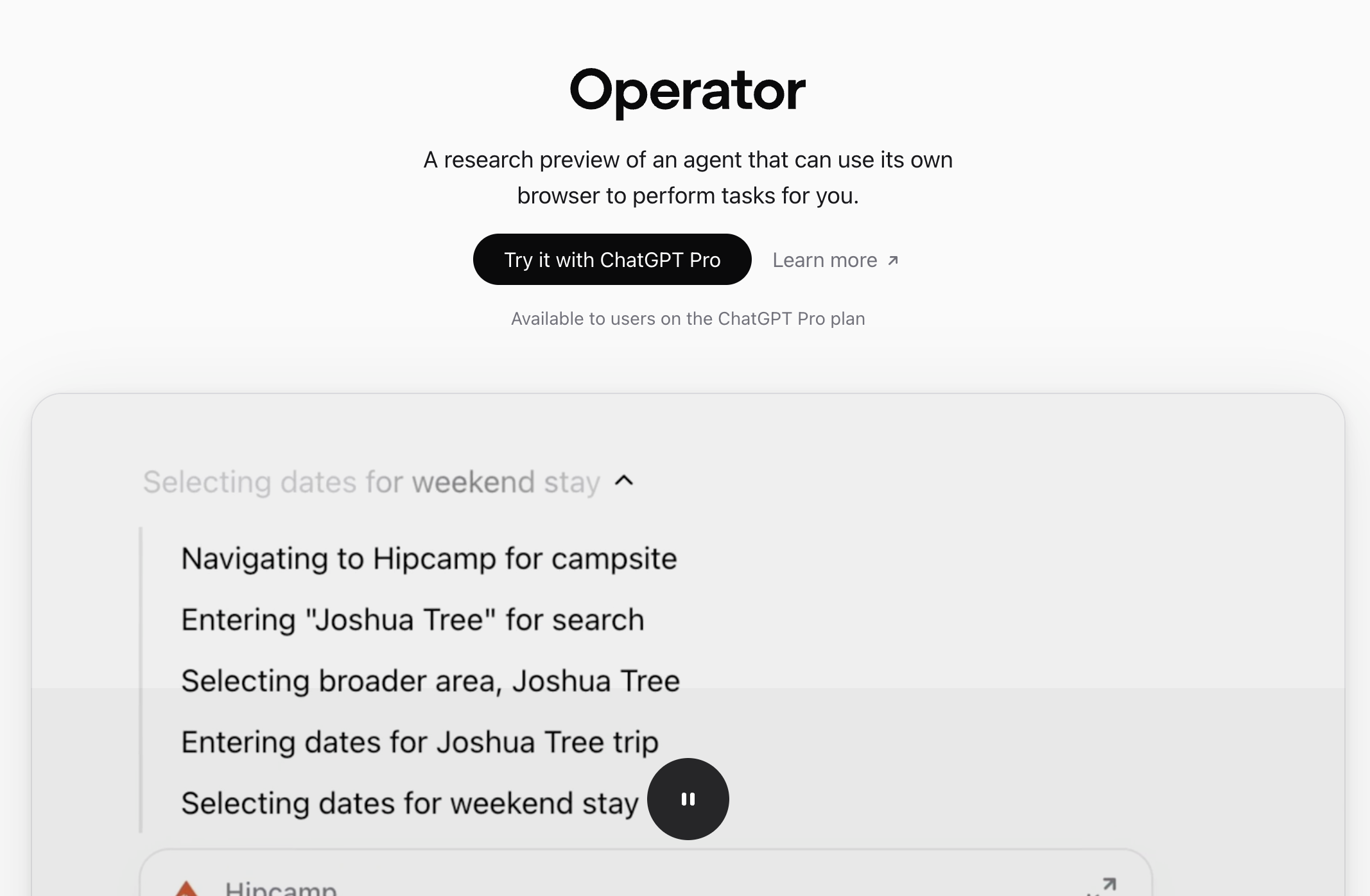
Operator是OpenAI推出的首款AI智能体。能像人类一样操作网页浏览器的AI工具,可以自动完成各种在线任务,如预订餐厅、购买机票、填写表单等。Operator基于Computer-Using Agent(CUA)的新模型驱动,模型结合了GPT-4o的视觉能力和强化学习的高级推理能力。通过屏幕截图“观察”网页,使用虚拟鼠标和键盘进行操作。Operator目前处于研究预览阶段,仅对美国的Cha
Company Research Agent是基于多智能体框架的公司研究工具,支持一键自动生成全面的公司研究报告。工具从公司网站、新闻文章、财务报告和行业分析等多源数据中收集信息,基于Gemini 2.5 Flash和GPT-4.1-mini等模型进行高语境研究综合及精确的报告格式化和编辑。工具具备AI内容过滤功能,确保信息的相关性和准确性,基于WebSocket实现实时进度流,为用户提供高效、便
Jaaz 是开源的AI设计Agent,本地免费 Lovart 平替项目。具备强大的 AI 设计能力,能智能生成设计提示,批量生成图像、海报、故事板等。Jaaz 支持 Ollama、Stable Diffusion、Flux Dev 等本地图像和语言模型,实现免费的图像生成。用户可以通过 GPT-4o、Flux Kontext 等技术,在对话中编辑图像,进行对象移除、风格转换等操作。Jaaz 提供无
银河通用发布全球首个产品级端到端具身 FSD 大模型 ——TrackVLA,一款具备纯视觉环境感知、语言指令驱动、可自主推理、具备零样本(Zero-Shot)泛化能力的具身大模型。 TrackVLA 是银河通用推出的产品级导航大模型,纯视觉环境感知、自然语言指令驱动、端到端输出语言和机器人动作,是一个由仿真合成动作数据训练的“视觉-语言-动作”(Vision-Language-Action, V
Firesearch 是 Mendable AI 团队推出的 AI 驱动的深度研究工具。基于 Firecrawl 多源网络内容提取技术,结合 OpenAI GPT-4o 的搜索规划和内容生成能力,将复杂的查询分解为多个子问题,分别进行搜索和内容提取。Firesearch 支持实时进度更新、答案验证(置信度 0.7 以上)、自动重试、完整引用和上下文记忆等功能,帮助用户高效地获取准确、全面的研究结果
只显示前20页数据,更多请搜索
Showing 361 to 384 of 404 results