关键词 "huggingface openai detector" 的搜索结果, 共 24 条, 只显示前 480 条
Lovart 全球首个设计 Agent 体验 Lovart 的三个特点: 一、全链路设计和执行,一句话搞定 以前的文生图工具,它们所提供的任务是“生成图片”这一环。 而设计 Agent,则像一位“设计执行官”,覆盖从创意拆解到专业交付的整个视觉流程。 从意图拆解 → 任务链 → 最后成品,一句话全搞定。 单次可以执行上
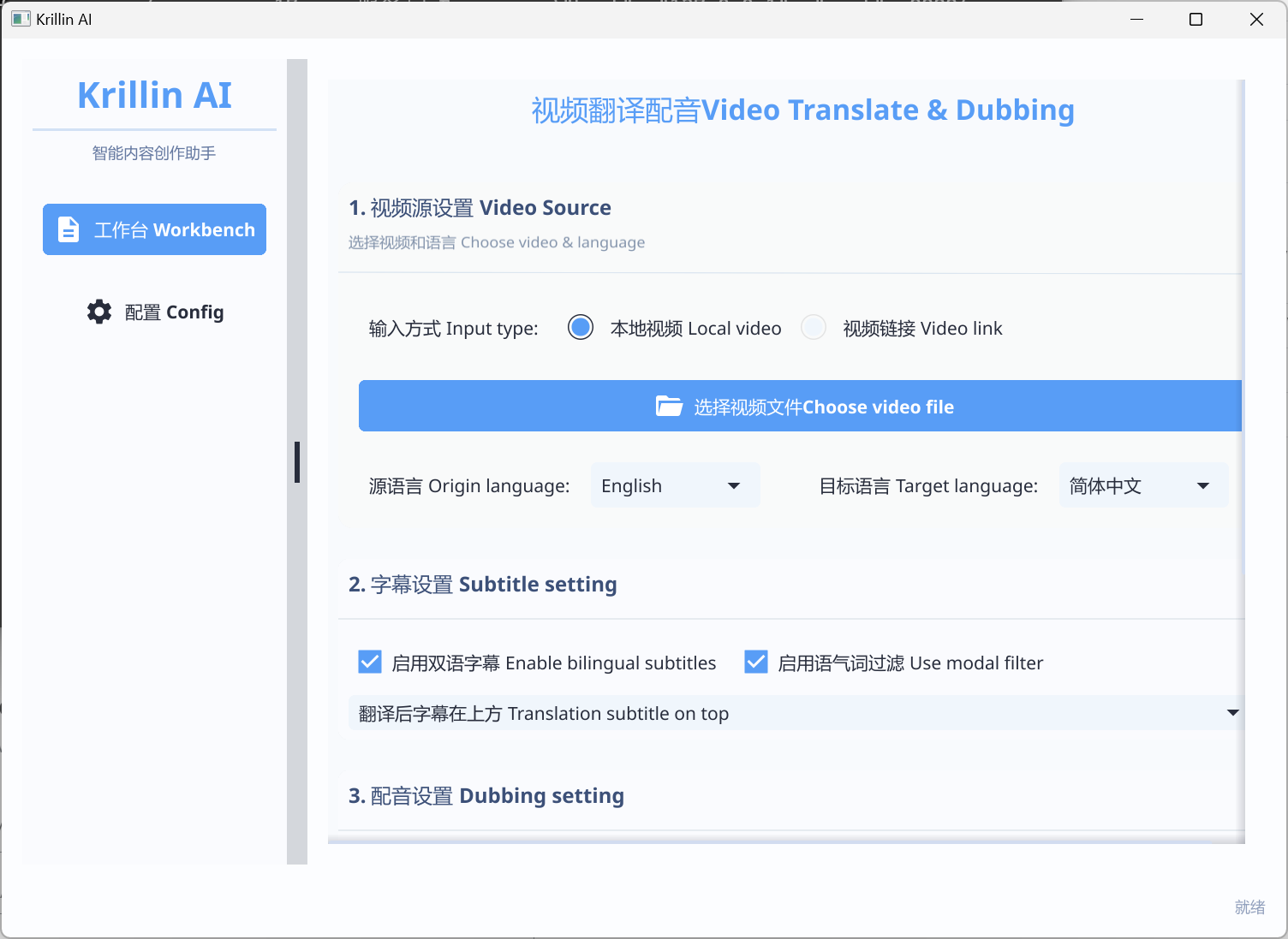
极简部署AI视频翻译配音工具 KrillinAI-一款AI视频翻译配音工具 提供了从视频下载,音频提取,音频转录,文本切割,翻译,对齐,到最终合成适配抖音,哔哩哔哩,小红书,视频号,快手等主流平台格式的一站式解决方案。 基于AI大模型的视频翻译和配音工具,专业级翻译,一键部署全流程,可以生成适配抖音,小红书,哔哩哔哩,视频号,TikTok,Youtube Shorts等形态的
字节开源DreamO,统一图像定制框架,把图像换装、换脸、换造型、换风格以及组合操作装在了一起 支持ID、IP、Try-On等组合,支持16GB/24GB显卡运行,用于虚拟试穿、商品广告、营销广告什么的比较实用 四个能力: IP,处理角色形象,支持人物、物体、动物等输入 ID,人脸身份处理 Try-On,虚拟试穿,可以同时换多件衣服 Style,风格迁移,目前还不能和其他任务组合 DreamO正
Step1X-3D是什么 Step1X-3D 是StepFun联合LightIllusions推出的高保真、可控的 3D 资产生成框架。基于严格的数据整理流程,从超过 500 万个 3D 资产中筛选出 200 万个高质量数据,创建标准化的几何和纹理属性数据集。Step1X-3D 支持多模态条件输入,如文本和语义标签,基于低秩自适应(LoRA)微调实现灵活的几何控制。Step1X-3D 推动了 3
VACE(Video Creation and Editing)是阿里巴巴通义实验室推出的一站式视频生成与编辑框架。基于整合多种视频任务(如参考视频生成、视频到视频编辑、遮罩编辑等)到一个统一模型中,实现高效的内容创作和编辑功能。VACE的核心在于Video Condition Unit(VCU),将文本、图像、视频和遮罩等多种模态输入整合为统一的条件单元,支持多种任务的灵活组合。开源的 Wan2
WorldMem 是南洋理工大学、北京大学和上海 AI Lab 推出的创新 AI 世界生成模型。模型基于引入记忆机制,解决传统世界生成模型在长时序下缺乏一致性的关键问题。在WorldMem中,智能体在多样化场景中自由探索,生成的世界在视角和位置变化后能保持几何一致性。WorldMem 支持时间一致性建模,模拟动态变化(如物体对环境的影响)。模型在 Minecraft 数据集上进行大规模训练,在真实
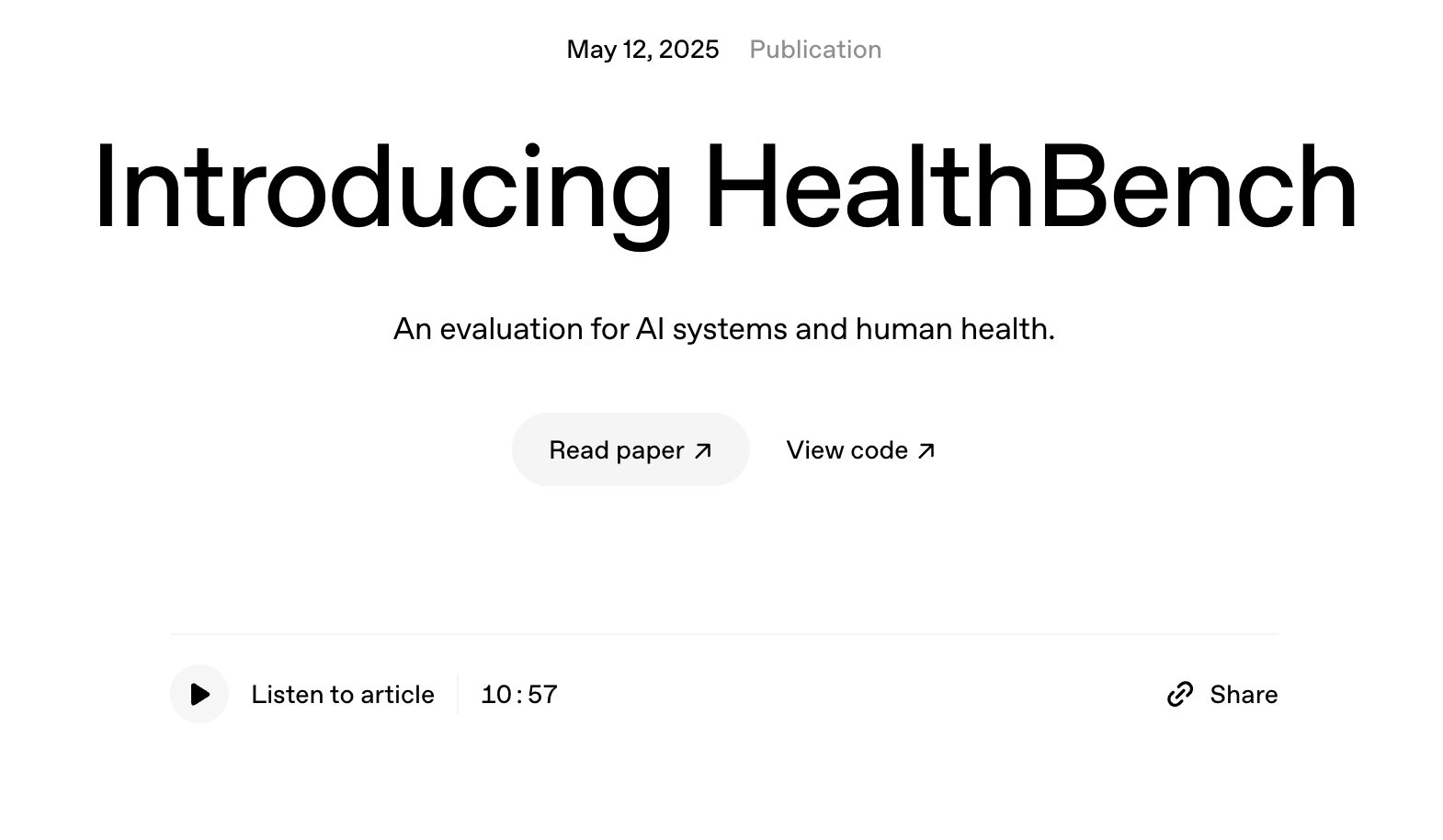
HealthBench是OpenAI推出的开源医疗测试基准,用在评估大型语言模型(LLMs)在医疗保健领域的表现和安全性。HealthBench包含5000个模型与用户或医疗专业人员之间的多轮对话,用262名医生创建的对话特定评分标准进行评估。对话覆盖多种健康情境(如紧急情况、临床数据转换、全球健康)和行为维度(如准确性、指令遵循、沟通)。HealthBench能衡量模型的整体表现,按主题(如紧急
ZenCtrl 是 Fotographer AI 推出的 AI 图像生成工具,支持从单张图像生成高质量、多视角和多样化场景的图像,无需额外训练数据。基于先进算法和图像处理技术,支持实时元素再生,适用于产品摄影、虚拟试穿、人物肖像控制、插画等场景。ZenCtrl 为创意和商业领域中高效、灵活的视觉内容生成解决方案。 ZenCtrl的主要功能 多视角和多样化场景生成:从单张主题图像生成高质量、
BILIVE 是基于 AI 技术的开源工具,专为 B 站直播录制与处理设计。工具支持自动录制直播、渲染弹幕和字幕,支持语音识别、自动切片精彩片段,生成有趣的标题和风格化的视频封面。BILIVE 能自动将处理后的视频投稿至 B 站,综合多种模态模型,兼容超低配置机器,无需 GPU 即可运行,适合个人用户和小型服务器使用。 1. Introduction Have you notice
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引入对比监督信号,进一步优化模型训练。SuperEdit不需要额外的视觉语言模型(VLM)或预训练任务,仅依赖高质量的监督信号,在多个基准测试中实现显著的性能提升。 Super
WebThinker是中国人民大学、北京智源人工智能研究院和华为泊松实验室等机构提出的深度研究智能体。WebThinker赋能大型推理模型(LRMs)在推理过程中自主进行网络搜索、网页导航和报告撰写。WebThinker基于深度网页探索器和自主思考、搜索、写作策略,让LRMs能动态获取信息,实时生成高质量研究报告。WebThinker基于强化学习的训练策略进一步优化工具使用效率。WebThinke
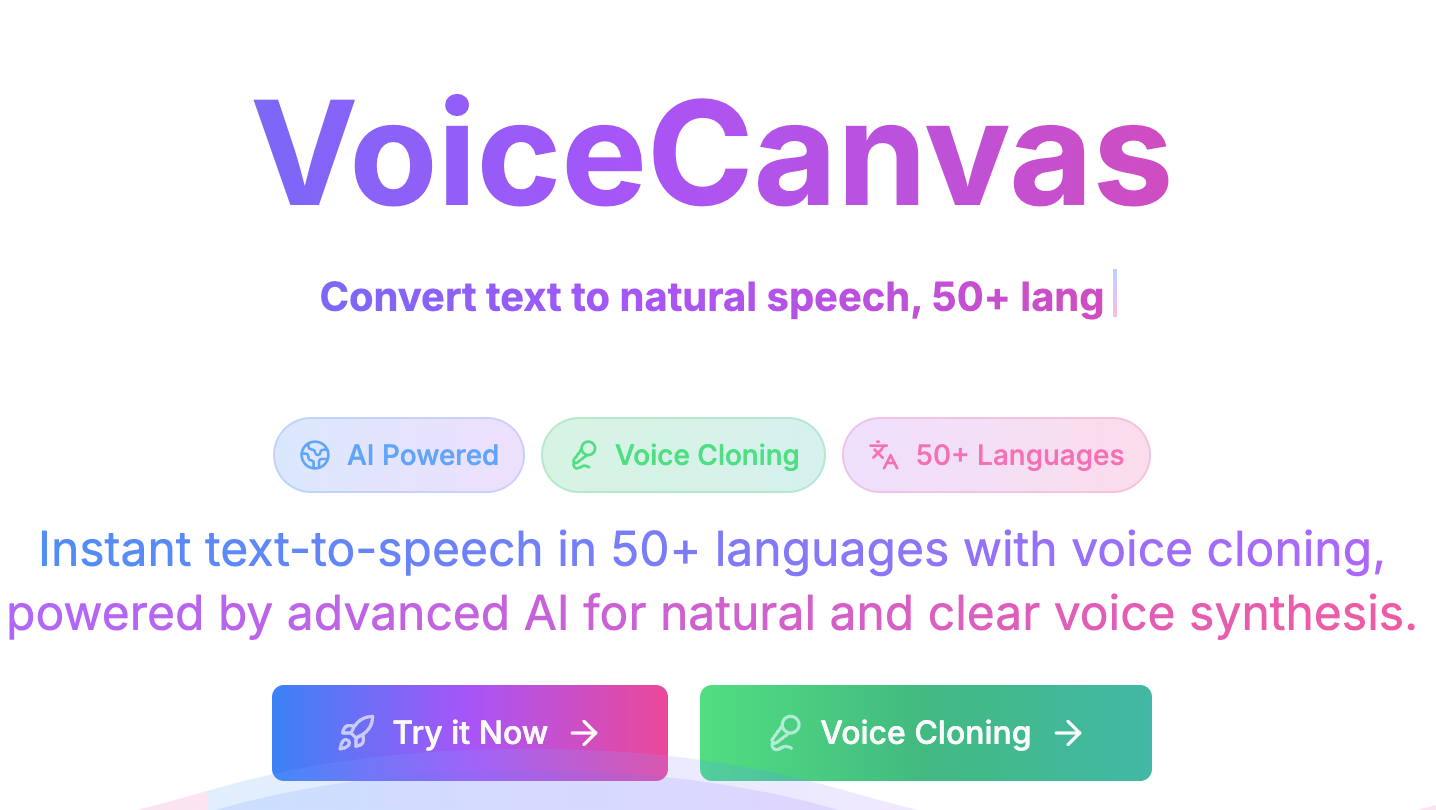
VoiceCanvas 是开源的多语言语音合成平台。基于 AI 技术提供高质量的文字转语音服务,支持超过 50 种语言,集成 OpenAI TTS、AWS Polly 和 MiniMax 等多种语音服务。VoiceCanvas 提供个人声音克隆功能,用户上传几秒音频样本能创建个性化声音。VoiceCanvas适合内容创作者、教育工作者和企业用户,显著提升语音内容制作效率。 VoiceCanvas
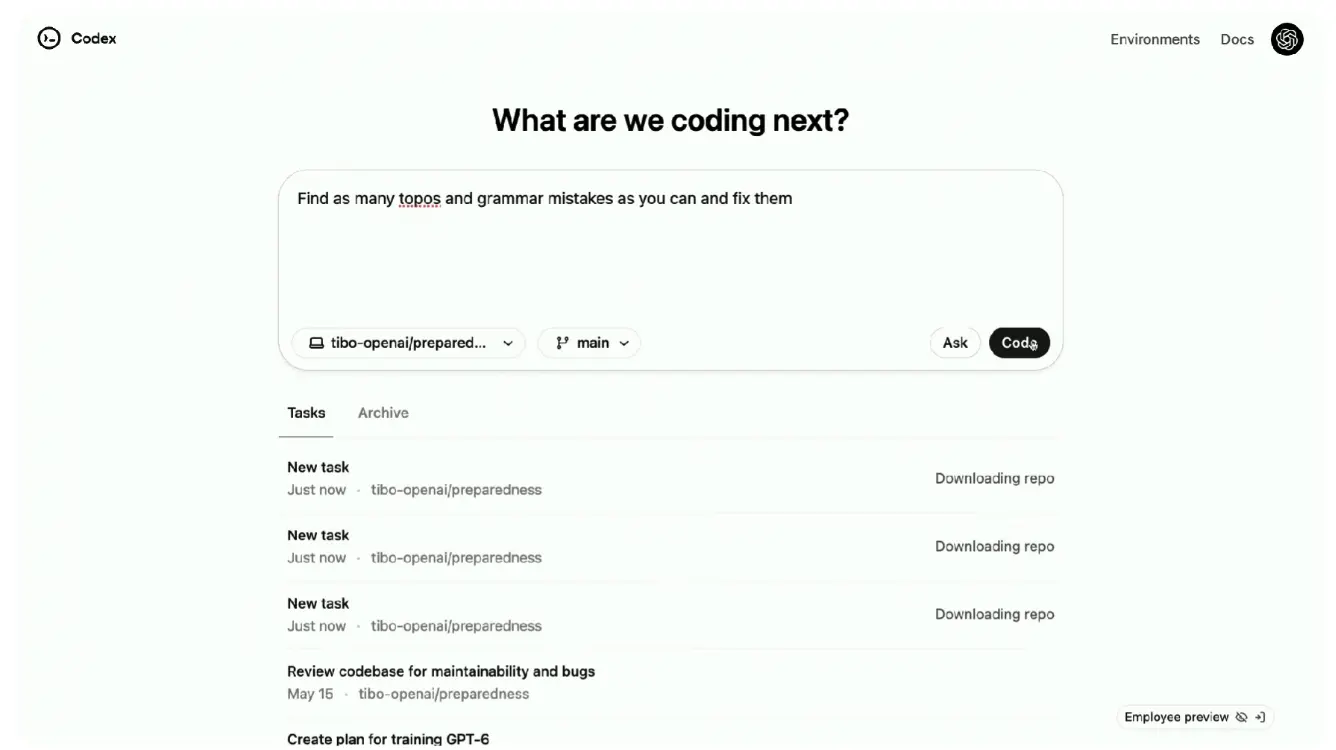
Codex 是一款支持并行处理多个任务的云端编程 Agent,能够提供如编程功能、回答代码库的问题、修复错误等功能。 Codex 基于 codex-1 模型驱动,OpenAI 方面表示这一模型由 o3 模型针对编程进行优化而得来。codex-1 通过强化学习在各种环境中,对现实世界的编码任务进行训练,从而能够生成接近人类风格和 PR 偏好的代码。 在 OpenAI 自己的代码评估和内部
卡内基梅隆大学的研究团队开发出一款名为 LegoGPT 的 AI 模型,能够根据文字指令生成可实际搭建的乐高设计。 比如输入文本「基本款沙发」,一眨眼的功夫,乐高沙发就拼好了。 团队训练了一种自回归大型语言模型,通过预测下一个 token 的方式,判断下一块该放置什么积木。团队还为模型增加了有效性校验和带有物理感知的回滚机制,确保生成的设计不会出现积木重叠或悬空等问题,也就是说最终结果始终可行
类似 Manus 但基于 Deepseek R1 Agents 的本地模型。 Manus AI 的本地替代品,它是一个具有语音功能的大语言模型秘书,可以 Coding、访问你的电脑文件、浏览网页,并自动修正错误与反省,最重要的是不会向云端传送任何资料。采用 DeepSeek R1 等推理模型构建,完全在本地硬体上运行,进而保证资料的隐私。 Features: 100% 本机运行:
flowith 团队推出了其最新的 AI 智能体产品Agent Neo。是世界首个可以支持无限步骤・无限上下文・无限工具的 AI Agent。 据称,Agent Neo 具备处理无限工作流步骤的能力,支持长时间云端执行,并拥有嵌套代理层级结构。用户还可以通过其知识市场将专业知识变现。 官方演示展示了通过单一提示生成完整游戏设计文档的案例,并强调其能够处理超过 1000 个逻辑步骤,7
Blip 3o 是一个基于 Hugging Face 平台的应用程序,利用先进的生成模型从文本生成图像,或对现有图像进行分析和回答。该产品为用户提供了强大的图像生成和理解能力,非常适合设计师、艺术家和开发者。此技术的主要优点是其高效的图像生成速度和优质的生成效果,同时还支持多种输入形式,增强了用户体验。该产品是免费的,定位于开放给广大用户使用。 需求人群: "该产品适合设计师、开发者和
昆仑万维面向全球市场,同步发布天工超级智能体(Skywork Super Agents)。这款产品采用了AI agent架构和deep research技术,能够一站式生成文档、PPT、表格(excel)、网页、播客和音视频多模态内容。它具有强大的deep research能力,在GAIA榜单上排名全球第一,超过了OpenAI Deep Research和Manus。 天工超级智能体(Skywo
Devstral是Mistral AI和All Hands AI推出的专为软件工程任务设计的编程专用模型。Devstral在解决真实世界软件问题上表现出色,在SWE-Bench Verified基准测试中,得分46.8%大幅领先其他开源模型。Devstral支持处理复杂代码库中的上下文关系、识别组件间联系及发现细微的代码错误。Devstral轻量级,能在单个RTX 4090或32GB内存的Mac上
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
Graphiti 是一个用于构建和查询时序感知知识图谱的框架,专为在动态环境中运行的 AI 代理量身定制。与传统的检索增强生成 (RAG) 方法不同,Graphiti 持续将用户交互、结构化和非结构化企业数据以及外部信息集成到一个连贯且可查询的图中。该框架支持增量数据更新、高效检索和精确的历史查询,无需完全重新计算图谱,因此非常适合开发交互式、情境感知的 AI 应用程序。 使用 Graphiti
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数,其中70亿为活跃参数。采用混合变换器专家架构(MoT),通过两个独立编码器分别捕捉图像的像素级和语义级特征。BAGEL遵循“下一个标记组预测”范式进行训练,使用海量多模态标记数据进行预训练,包括语言、图像、视频和网络数据。在性能方面,BAGEL在多模态理解基准测试中超越了Qwen2.5-VL和InternVL-2.5等顶级开源视觉语言模型
Moondream是一个免费开源的小型的人工智能视觉语言模型,虽然参数量小(Moondream1仅16亿,Moondream2为18.6亿)但可以提供高性能的视觉处理能力,可在本地计算机甚至移动设备或 Raspberry Pi 上运行,能够快速理解和处理输入的图像信息并对用户提出的问题进行解答。该模型由开发人员vikhyatk推出,使用SigLP、Phi-1.5和LLaVa训练数据集和模型权重初始
mPLUG-Owl3是阿里巴巴推出的通用多模态AI模型,专为理解和处理多图及长视频设计。在保持准确性的同时,显著提升了推理效率,能在4秒内分析完2小时电影。模型采用创新的Hyper Attention模块,优化视觉与语言信息的融合,支持多图场景和长视频理解。mPLUG-Owl3在多个基准测试中达到行业领先水平,其论文、代码和资源已开源,供研究和应用。 mPLUG-Owl3的主要功能 多
只显示前20页数据,更多请搜索
Showing 385 to 408 of 482 results