关键词 "huggingface openai detector" 的搜索结果, 共 24 条, 只显示前 480 条
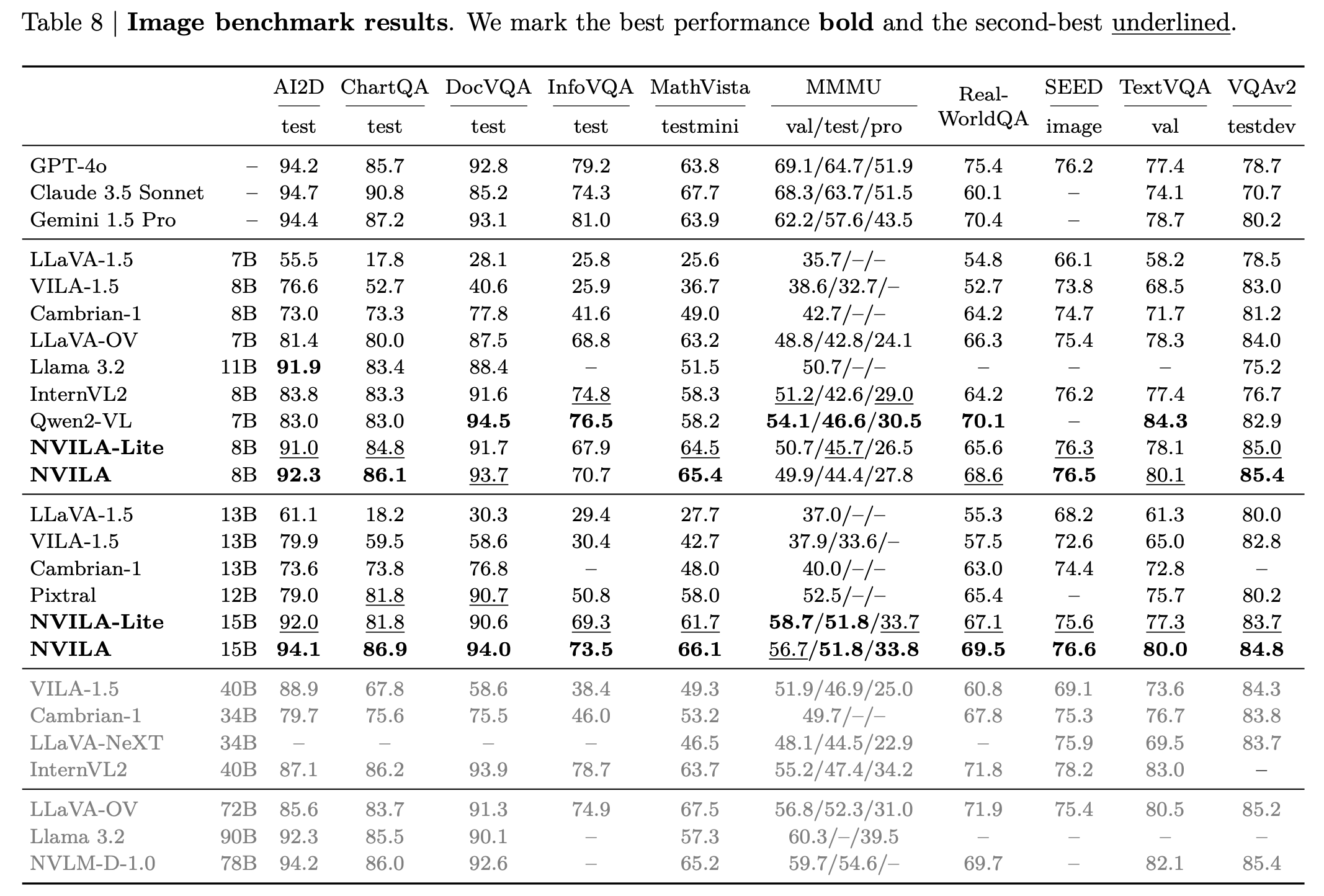
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等
DMind是DMind研究机构发布的专为Web3领域优化的大型语言模型。针对区块链、去中心化金融和智能合约等场景深度优化,使用Web3数据微调采用RLHF技术对齐。DMind在Web3专项基准测试中表现优异,性能远超一线通用模型,推理成本仅为主流大模型的十分之一。包含DMind-1和DMind-1-mini两个版本,前者适合复杂指令和多轮对话,后者轻量级,响应快、延迟低,适合代理部署和链上工具。
ScrapeGraphAI 是基于大型语言模型(LLM)驱动的智能网络爬虫工具包,专注于从各类网站和HTML内容中高效提取结构化数据。具备三大核心功能:SmartScraper可根据用户提示精准抓取网页中的结构化信息;SearchScraper基于AI驱动的搜索技术从搜索引擎结果中提取关键信息;Markdownify可将网页内容快速转换为整洁的Markdown格式,方便后续处理和存储。 Sc
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
II-Agent:一个用于构建和部署智能体的全新开源框架。II-Agent 是一款开源智能助手,旨在简化和增强跨领域的工作流程。它代表了我们与技术互动方式的重大进步——从被动工具转变为能够独立执行复杂任务的智能系统。作为简易的COZE,Dify平替。 ii-agent开源框架,擅长构建跨多个领域工作流的Agent,能独立执行复杂任务已是Agent标配 其技能覆盖研究与核查、内容生成、数据分析可视
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
Sapling AI 是检测文本是否由AI生成的免费在线工具,用户可以通过上传文本或直接粘贴内容进行检测,工具基于机器学习算法分析文本特征,识别出由 AI 模型(如 ChatGPT 和 GPT-4)生成的内容。Sapling 能在短至 50 个字的文本中进行检测,将 AI 生成的部分高亮显示,同时提供整体的 AI 生成内容比例。 Sapling AI Content Detector的主要功能
企业 IM、在线客服、企业知识库 / 帮助文档、客户之声、工单系统、AI 对话、工作流、项目管理。 Docker 快速开始 方法一:克隆项目并启动docker compose容器,需要另行安装ollama,默认使用 qwen3:0.6b 模型 git clone https://gitee.com/270580156/weiyu.git && cd weiyu/deplo
Operator是OpenAI推出的首款AI智能体。能像人类一样操作网页浏览器的AI工具,可以自动完成各种在线任务,如预订餐厅、购买机票、填写表单等。Operator基于Computer-Using Agent(CUA)的新模型驱动,模型结合了GPT-4o的视觉能力和强化学习的高级推理能力。通过屏幕截图“观察”网页,使用虚拟鼠标和键盘进行操作。Operator目前处于研究预览阶段,仅对美国的Cha
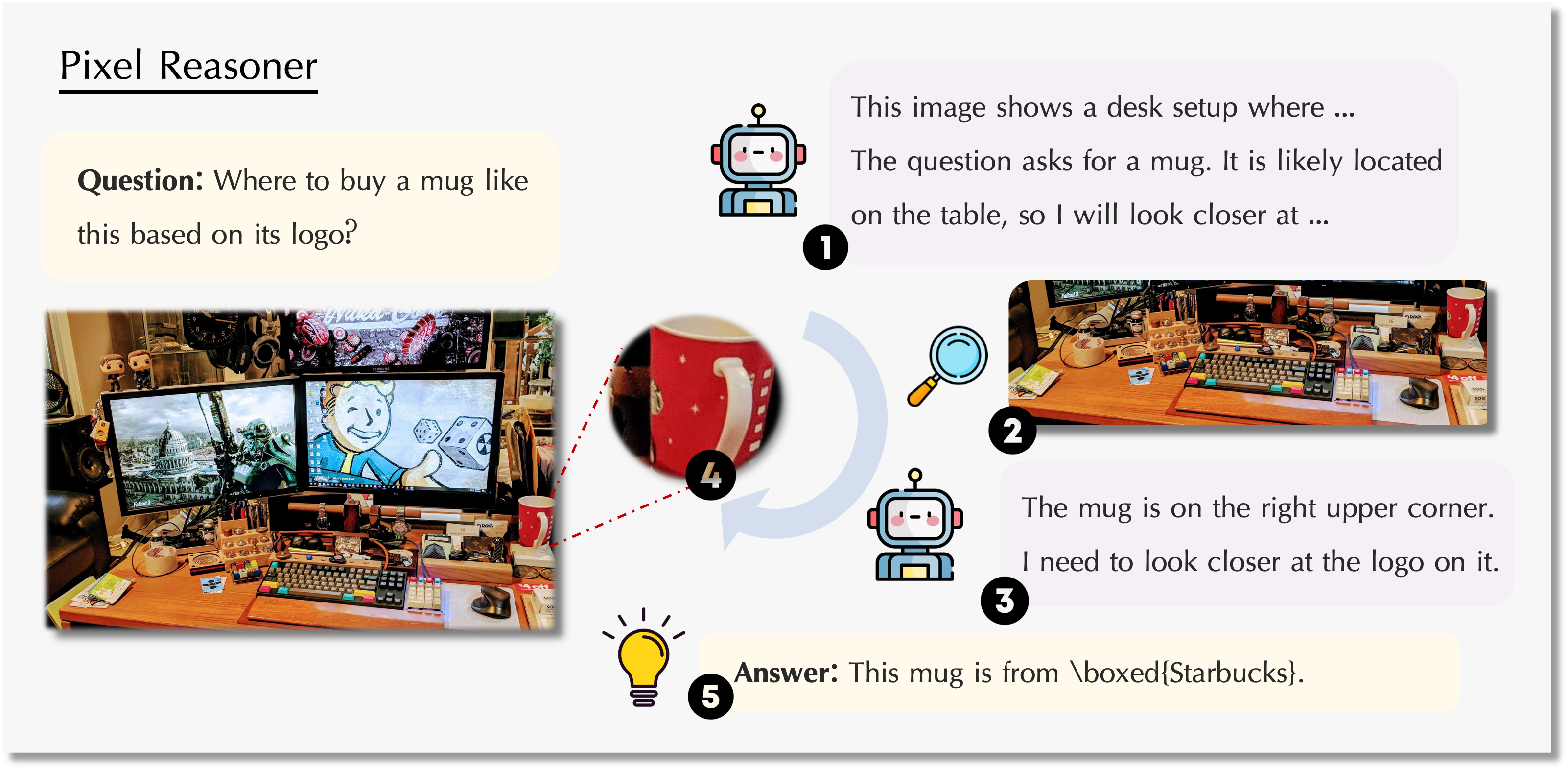
视觉语言模型(VLM),基于像素空间推理增强模型对视觉信息的理解和推理能力。模型能直接在视觉输入上进行操作,如放大图像区域或选择视频帧,更细致地捕捉视觉细节。Pixel Reasoner用两阶段训练方法,基于指令调优让模型熟悉视觉操作,用好奇心驱动的强化学习激励模型探索像素空间推理。Pixel Reasoner在多个视觉推理基准测试中取得优异的成绩,显著提升视觉密集型任务的性能。 Pixel R
Vid2World是清华大学联合重庆大学推出的创新框架,支持将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。模型基于视频扩散因果化和因果动作引导两大核心技术,解决传统VDM在因果生成和动作条件化方面的不足。Vid2World在机器人操作和游戏模拟等复杂环境中表现出色,支持生成高保真、动态一致的视频序列,支持基于动作的交互式预测。Vid2World为提升世界模
FinRobot是一个超越 FinGPT 范畴的 AI 代理平台,是专为金融应用精心设计的综合解决方案。它集成了多种 AI 技术,超越了单纯的语言模型。这种广阔的视野凸显了平台的多功能性和适应性,能够满足金融行业的多方面需求。 AI代理的概念:AI代理是一种智能体,它使用大型语言模型作为大脑来感知环境、做出决策并执行动作。与传统的人工智能不同,AI代理具有独立思考和利用工具逐步实现既定目标的能力
LMEval 是谷歌推出的开源框架,用在简化大型模型(LLMs)的跨提供商评估。框架支持多模态(文本、图像、代码)和多指标评估,兼容 Google、OpenAI、Anthropic 等主流模型提供商。LMEval 基于增量评估引擎,运行必要的测试,节省时间和计算资源。框架自加密的 SQLite 数据库确保评估结果的安全存储。LMEvalboard 提供交互式可视化界面,帮助用户快速分析模型性能,直
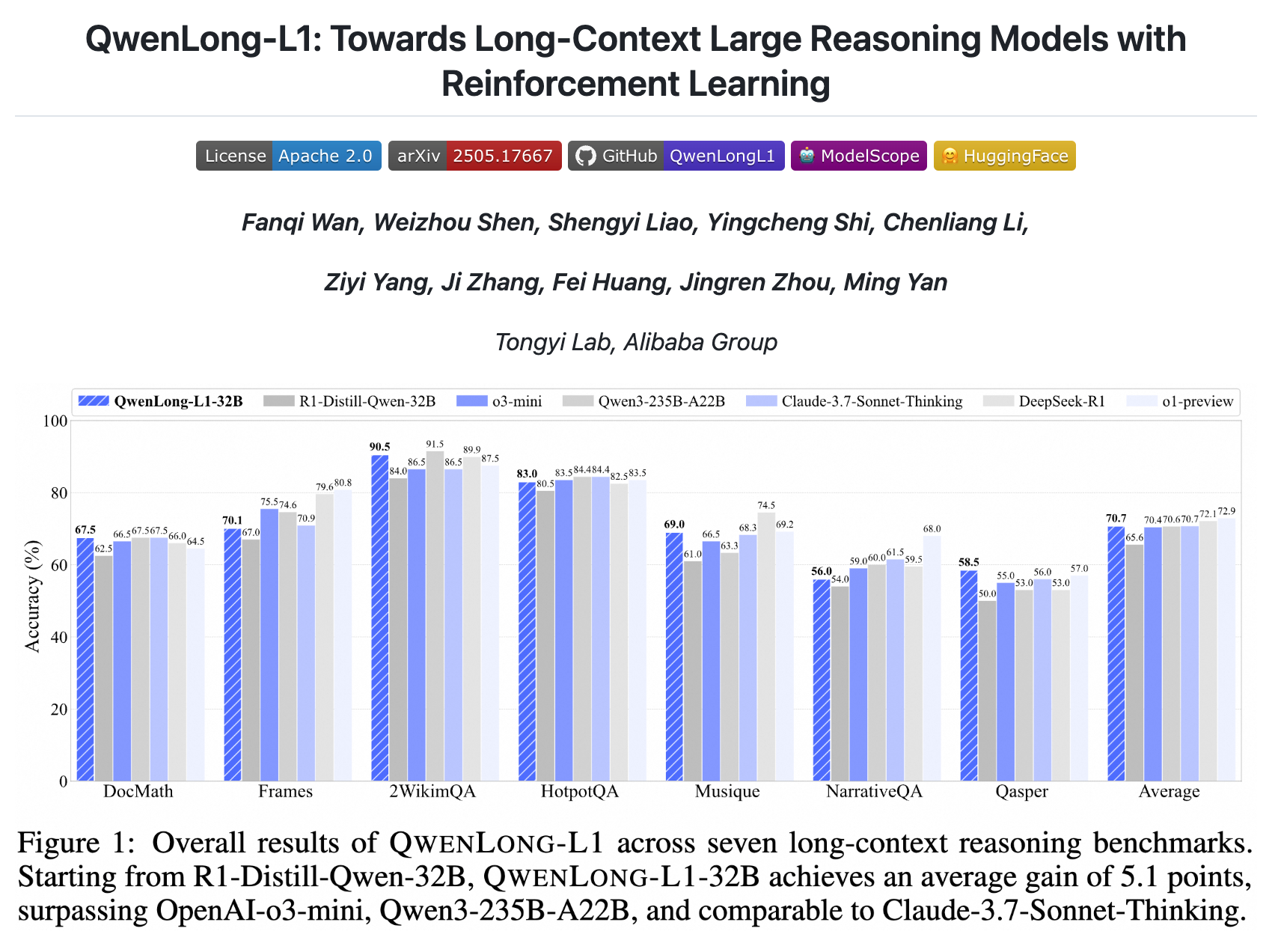
QwenLong-L1-32B 是阿里巴巴集团 Qwen-Doc 团队推出的,基于强化学习训练的首个长文本推理大模型。模型基于渐进式上下文扩展、课程引导的强化学习和难度感知的回顾性采样策略,显著提升在长文本场景下的推理能力。模型在多个长文本文档问答(DocQA)基准测试中表现优异,平均准确率达到了70.7%,超越OpenAI-o3-mini和Qwen3-235B-A22B等现有旗舰模型,且与Cla
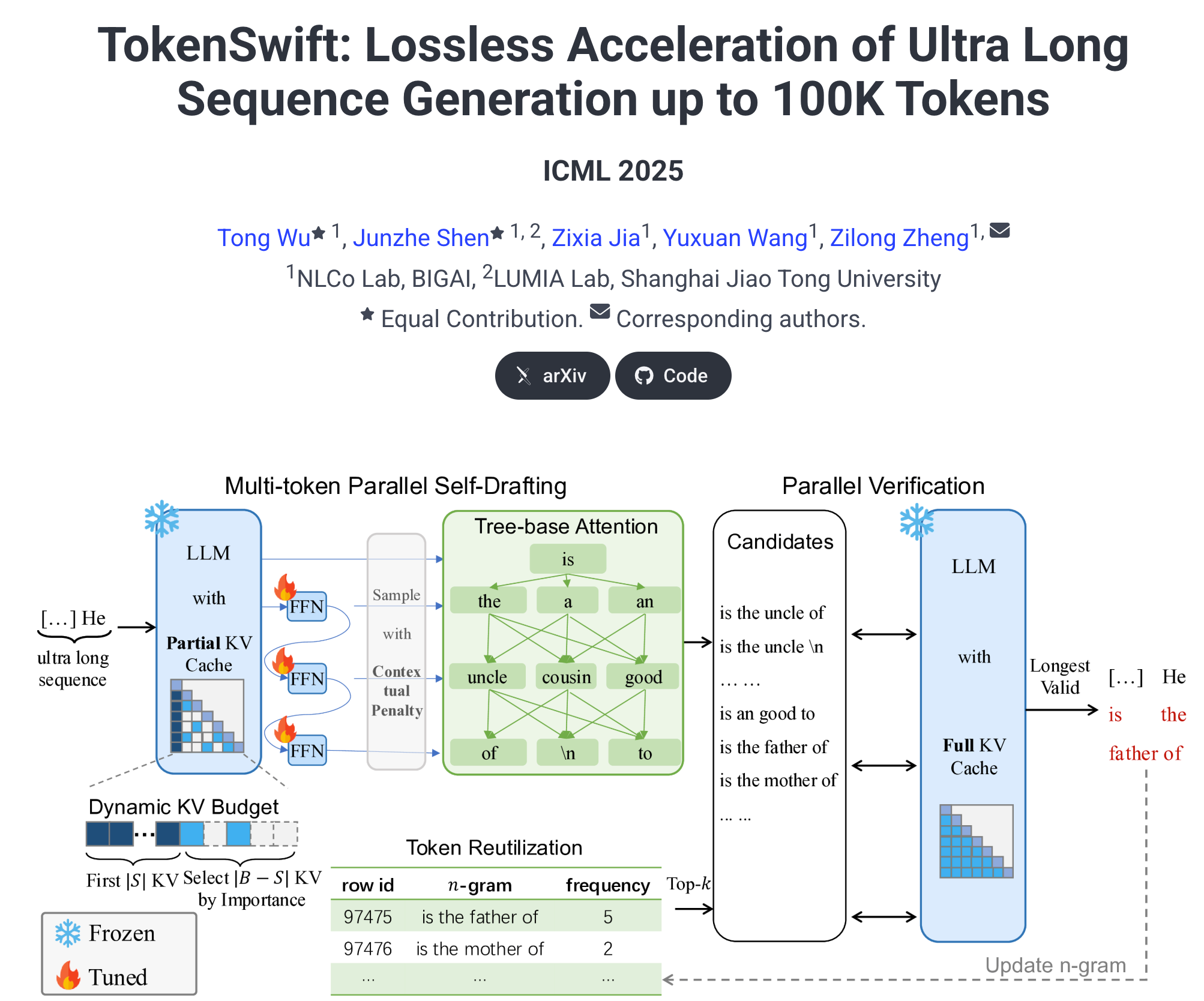
TokenSwift 是北京通用人工智能研究院团队推出的超长文本生成加速框架,能在90分钟内生成10万Token的文本,相比传统自回归模型的近5小时,速度提升了3倍,生成质量无损。TokenSwift 通过多Token生成与Token重用、动态KV缓存更新以及上下文惩罚机制等技术,减少模型加载延迟、优化缓存更新时间并确保生成多样性。支持多种不同规模和架构的模型,如1.5B、7B、8B、14B的MH
Onit的主要功能 高亮文本自动加载:支持用户在任何应用程序中高亮选择文本,Onit自动将文本加载到聊天窗口中,无需手动复制粘贴。 自动上下文提取:Onit能自动读取当前活动窗口的内容,作为上下文加载到聊天窗口中,方便用户快速获取AI的帮助。 自由切换模型:支持用户自由切换不同的AI模型(如OpenAI、Anthropic、xAI等),根据需求选择最适合的模型。 本地模式:Onit支持
Ming-Lite-Omni是蚂蚁集团开源的统一多模态大模型。模型基于MoE架构,融合文本、图像、音频和视频等多种模态的感知能力,具备强大的理解和生成能力。模型在多个模态基准测试中表现出色,在图像识别、视频理解、语音问答等任务上均取得优异成绩。模型支持全模态输入输出,能实现自然流畅的多模态交互,为用户提供一体化的智能体验。Ming-Lite-Omni具备高度的可扩展性,可广泛用在OCR识别、知识问
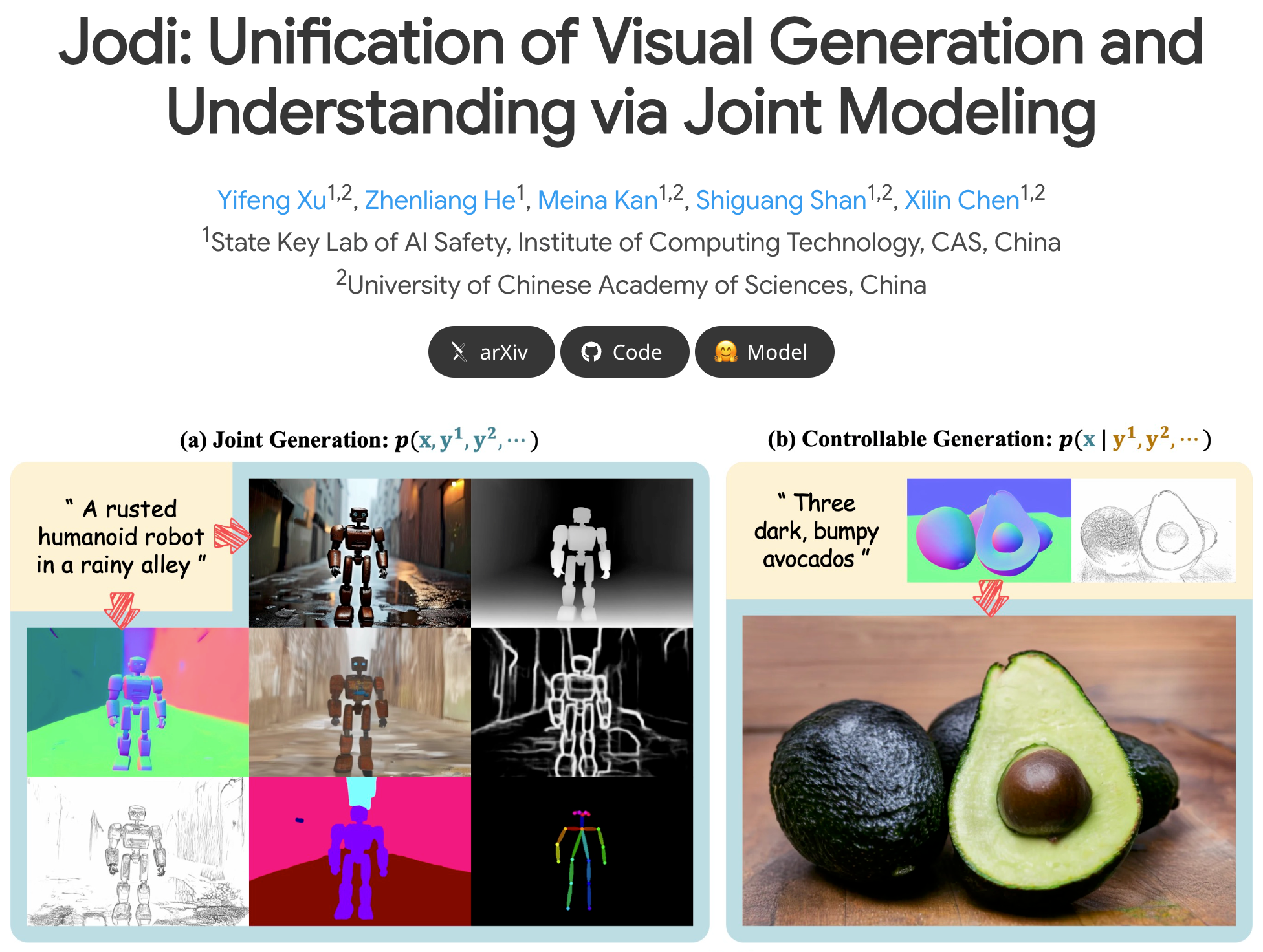
Jodi是中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,将视觉生成与理解统一起来。Jodi基于线性扩散Transformer和角色切换机制,执行联合生成(同时生成图像和多个标签)、可控生成(基于标签组合生成图像)及图像感知(从图像预测多个标签)三种任务。Jodi用包含20万张高质量图像和7个视觉域标签的Joint-1.6M数据集进行训练。Jodi在生成
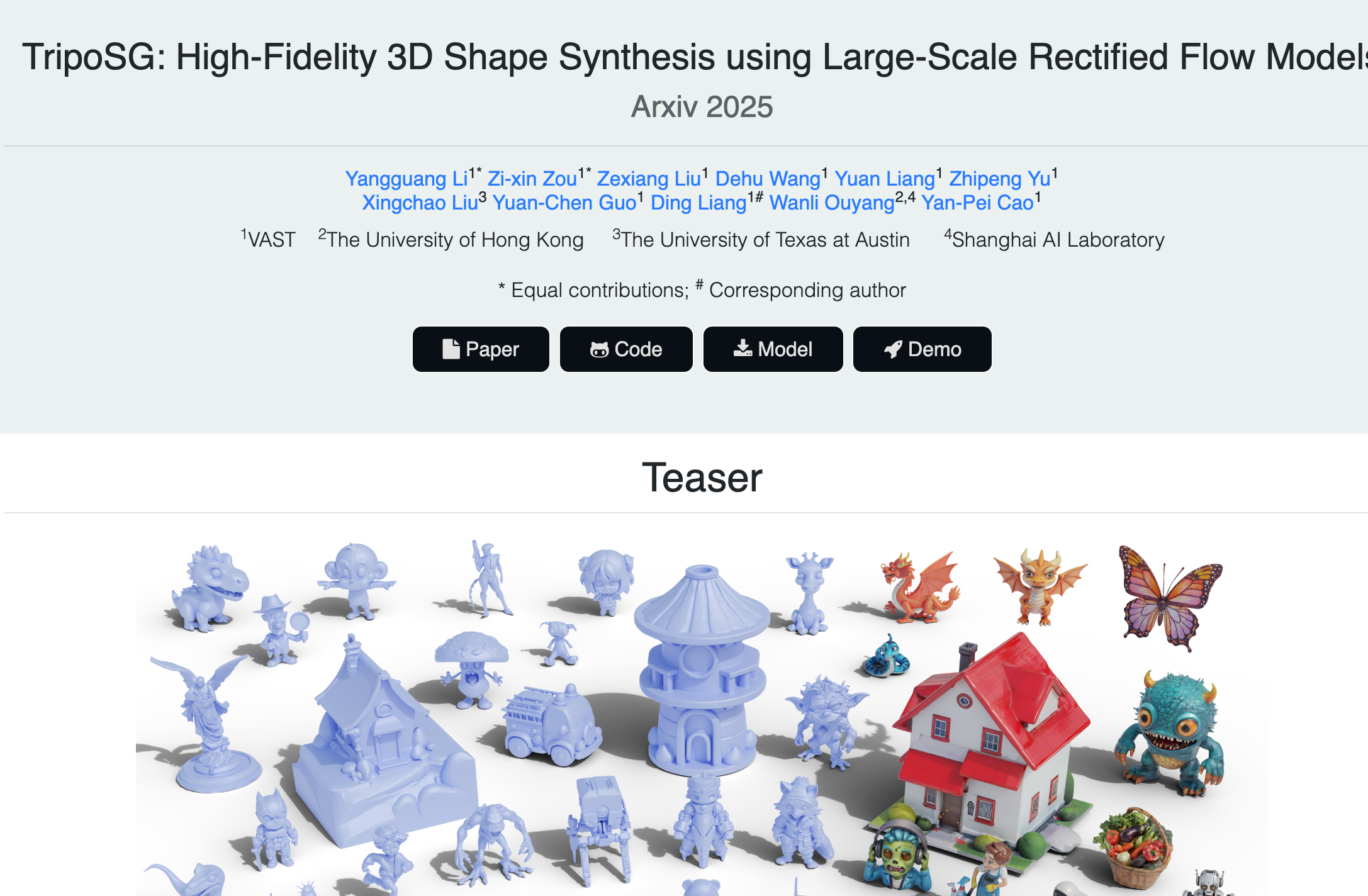
TripoSG 是 VAST-AI-Research 团队推出的基于大规模修正流(Rectified Flow, RF)模型的高保真 3D 形状合成技术, 通过大规模修正流变换器架构、混合监督训练策略以及高质量数据集,实现了从单张输入图像到高保真 3D 网格模型的生成。TripoSG 在多个基准测试中表现出色,生成的 3D 模型具有更高的细节和更好的输入条件对齐。 TripoSG的主要功能
Jaaz 是开源的AI设计Agent,本地免费 Lovart 平替项目。具备强大的 AI 设计能力,能智能生成设计提示,批量生成图像、海报、故事板等。Jaaz 支持 Ollama、Stable Diffusion、Flux Dev 等本地图像和语言模型,实现免费的图像生成。用户可以通过 GPT-4o、Flux Kontext 等技术,在对话中编辑图像,进行对象移除、风格转换等操作。Jaaz 提供无
Firesearch 是 Mendable AI 团队推出的 AI 驱动的深度研究工具。基于 Firecrawl 多源网络内容提取技术,结合 OpenAI GPT-4o 的搜索规划和内容生成能力,将复杂的查询分解为多个子问题,分别进行搜索和内容提取。Firesearch 支持实时进度更新、答案验证(置信度 0.7 以上)、自动重试、完整引用和上下文记忆等功能,帮助用户高效地获取准确、全面的研究结果
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视
MoonCast 是零样本播客生成系统,从纯文本源合成自然的播客风格语音。通过长上下文语言模型和大规模语音数据训练,能生成几分钟长的播客音频,支持中文和英文。生成语音的自然性和连贯性,在长音频生成中能保持高质量。MoonCast 使用特定的LLM提示来生成播客脚本,通过语音合成模块将其转换为最终的播客音频。用户可以通过简单的命令和预训练权重快速生成播客。 MoonCast的项目地址 项目官
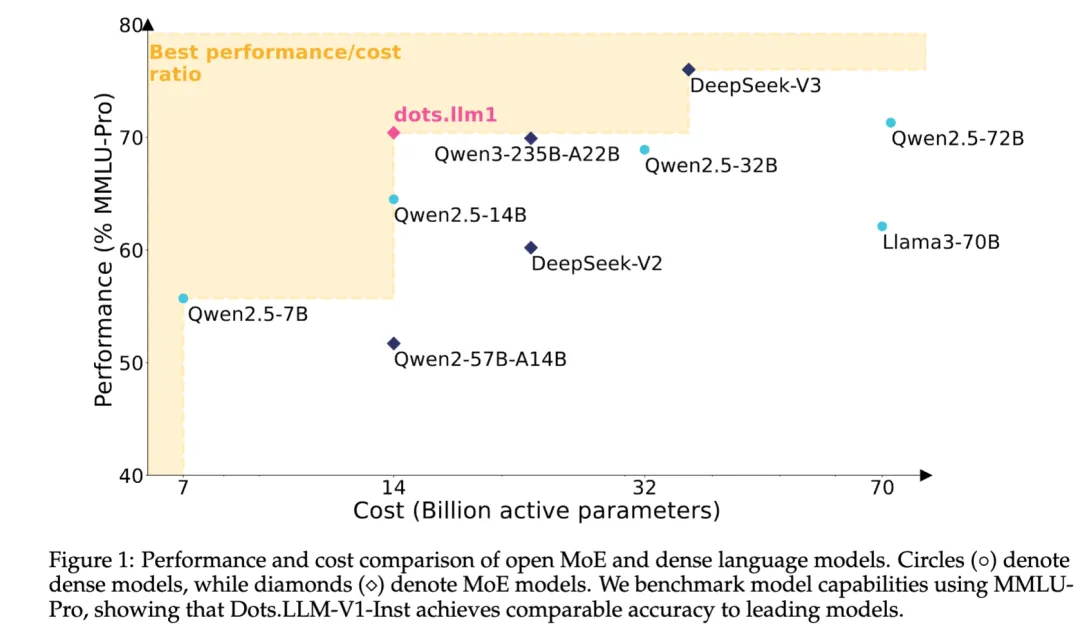
小红书hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源文本大模型 dots.llm1。 dots.llm1是一个中等规模的Mixture of Experts (MoE)文本大模型,在较小激活量下取得了不错的效果。该模型充分融合了团队在数据处理和模型训练效率方面的技术积累,并借鉴了社区关于 MoE 的最新开源成果。hi lab团队开源了所有模型和必要的训练
只显示前20页数据,更多请搜索
Showing 409 to 432 of 482 results