关键词 "large dataset handling" 的搜索结果, 共 12 条, 只显示前 480 条
Easily connect to PostgreSQL databases via a plug-and-play MCP server. Supports SELECT, INSERT, UPDATE, and more with prepared statements, automatic connection handling, and full TypeScript support
A memory system for Cline that tracks progress between conversations. Avoid large token usage!
<p>Overview Spark-TTS 是由出门问问(Mobvoi)联合多所顶尖学术机构(如香港科技大学、上海交通大学)最新推出的新一代语音合成模型,其核心创新在于BiCodec编码技术和与文本大模型的结构统一性,利用大型语言模型 (LLM) 的强大功能实现高度准确且自然的语音合成。</p> <p>Spark-TTS is an advanced text
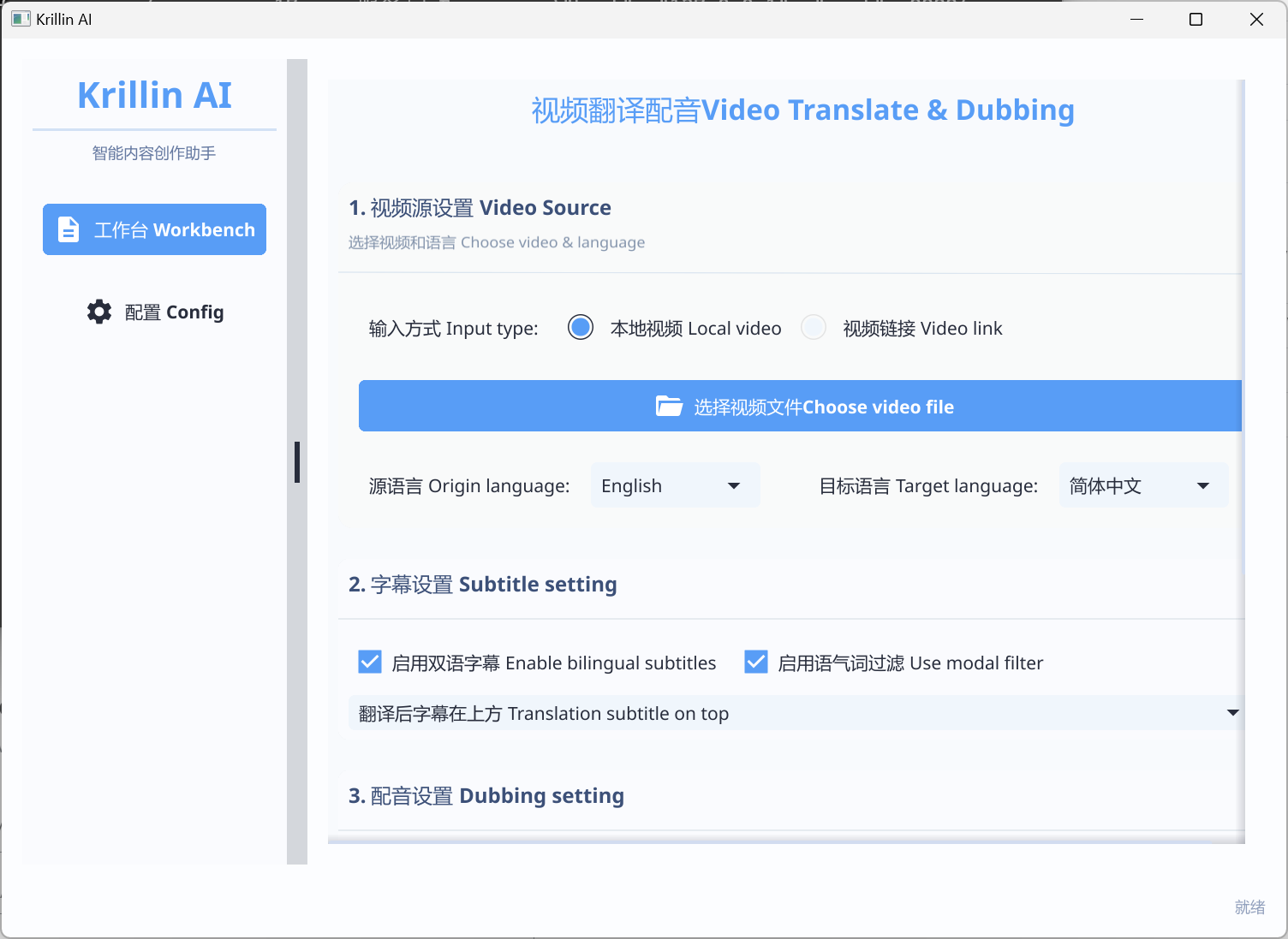
极简部署AI视频翻译配音工具 KrillinAI-一款AI视频翻译配音工具 提供了从视频下载,音频提取,音频转录,文本切割,翻译,对齐,到最终合成适配抖音,哔哩哔哩,小红书,视频号,快手等主流平台格式的一站式解决方案。 基于AI大模型的视频翻译和配音工具,专业级翻译,一键部署全流程,可以生成适配抖音,小红书,哔哩哔哩,视频号,TikTok,Youtube Shorts等形态的
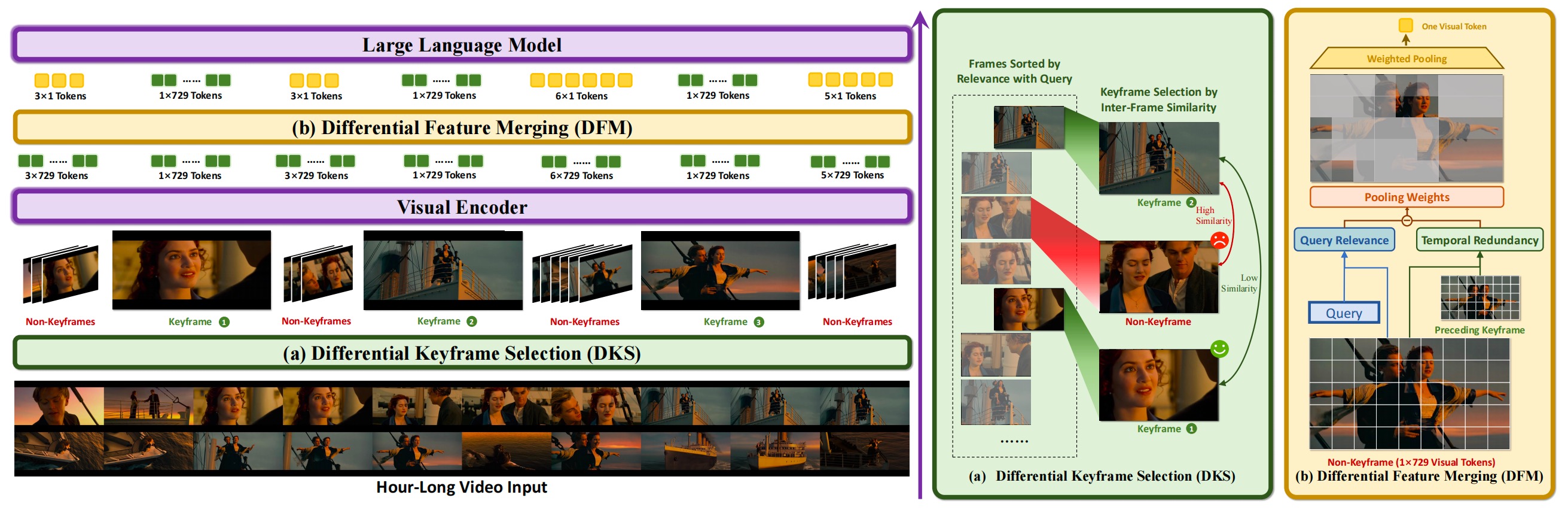
ViLAMP(VIdeo-LAnguage Model with Mixed Precision)是蚂蚁集团和中国人民大学联合推出的视觉语言模型,专门用在高效处理长视频内容。基于混合精度策略,对视频中的关键帧保持高精度分析,显著降低计算成本提高处理效率。ViLAMP在多个视频理解基准测试中表现出色,在长视频理解任务中,展现出显著优势。ViLAMP能在单张A100 GPU上处理长达1万帧(约3小时)
BILIVE 是基于 AI 技术的开源工具,专为 B 站直播录制与处理设计。工具支持自动录制直播、渲染弹幕和字幕,支持语音识别、自动切片精彩片段,生成有趣的标题和风格化的视频封面。BILIVE 能自动将处理后的视频投稿至 B 站,综合多种模态模型,兼容超低配置机器,无需 GPU 即可运行,适合个人用户和小型服务器使用。 1. Introduction Have you notice
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引入对比监督信号,进一步优化模型训练。SuperEdit不需要额外的视觉语言模型(VLM)或预训练任务,仅依赖高质量的监督信号,在多个基准测试中实现显著的性能提升。 Super
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
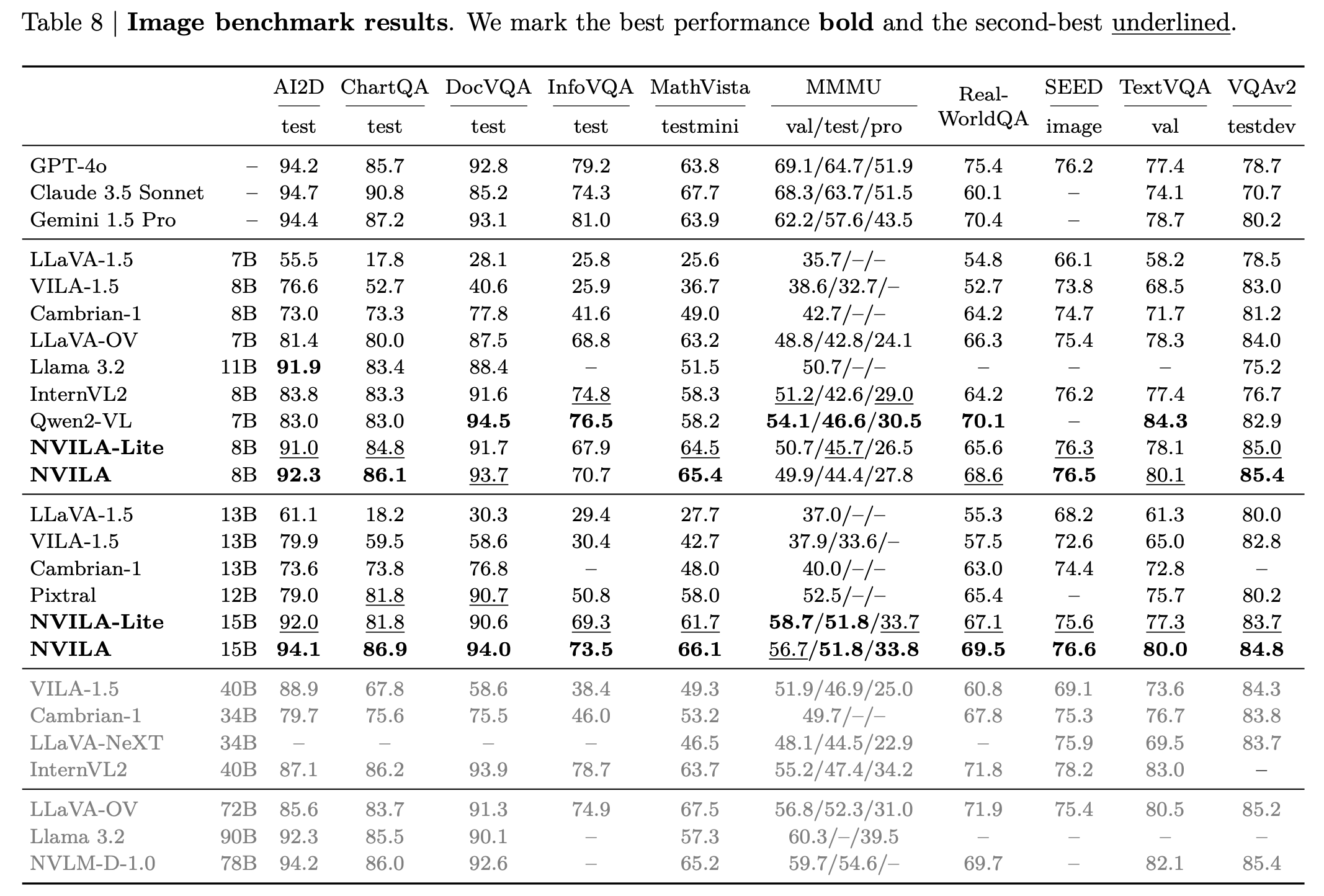
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
WebSailor 是阿里通义实验室开源的网络智能体,专注于复杂信息检索与推理任务。通过创新的数据合成方法(如 SailorFog-QA)和训练技术(如拒绝采样微调和 DUPO 算法),在高难度任务中表现出色,在 BrowseComp 等评测中超越多个知名模型,登顶开源网络智能体榜单。WebSailor 的推理重构技术能高效处理复杂任务,生成简洁且精准的推理链。在复杂场景中表现出色,在简单任务中展
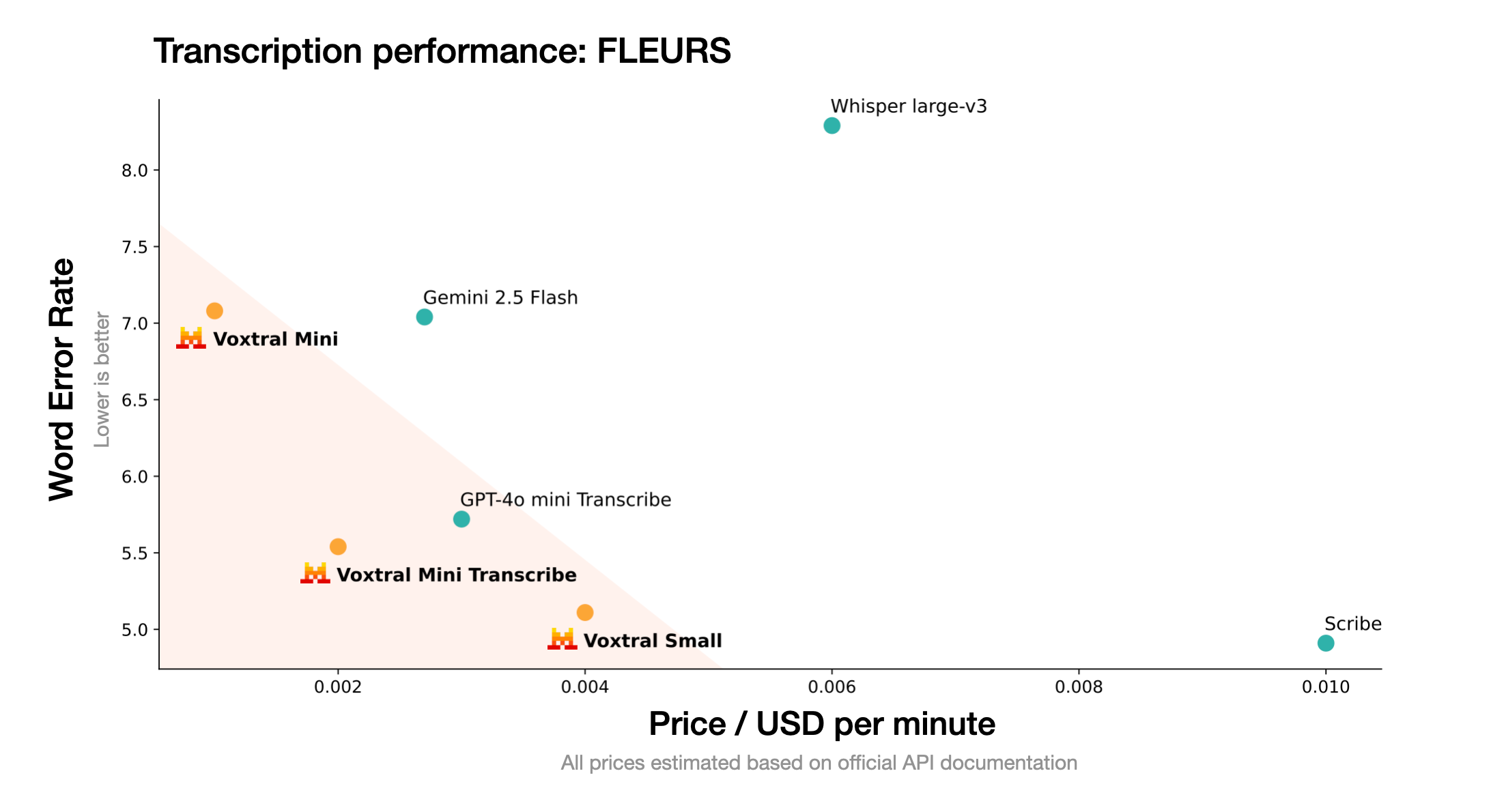
Mistral AI,最新发布了首个开源语音模型:Voxtral语音理解模型系列! 该模型包含24B和3B两个参数规模的版本,均基于Apache 2.0许可证开源,同时提供API服务接口。 Voxtral模型支持32k token的上下文窗口,能够处理长达30分钟的音频转录任务或40分钟的语义理解任务,在各项基准测试指标上全面超越目前主流的开源语音转录模型Whisper large-v3。
只显示前20页数据,更多请搜索
Showing 289 to 300 of 300 results