关键词 "m2 macbook air" 的搜索结果, 共 17 条, 只显示前 480 条
A fairly customizable MCP server for Logseq
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
FunGPT 是基于 InternLM2.5 系列大模型开发的开源项目,专为情感调节设计。具备两大核心功能:甜言蜜语模式和犀利怼语模式。甜言蜜语模式能用温暖的话语和独特的夸奖提升用户心情,犀利怼语模式以幽默风趣的方式帮助用户释放压力。FunGPT 采用 1.8B 系列轻量化模型,结合 AWQ 量化技术,既节省 GPU 内存又提升推理速度。 FunGPT的主要功能 甜言蜜语模式:当用户情绪低
杭州剂泰医药科技有限责任公司,简称“剂泰医药”(METiS Pharmaceuticals)致力于推动AI药物及递送系统平台开发,通过自主研发及积极对外合作,在小分子及核酸药物领域与合作伙伴共同将更多具备高价值的药物管线推进至临床阶段。 剂泰医药专注于“AI+药物递送”技术布局,打造多器官靶向递送系统,加速CGT、核酸药物等领域产品开发。目前,公司已自主研发了AI驱动的核酸递送系统设计平台(
Graphiti 是一个用于构建和查询时序感知知识图谱的框架,专为在动态环境中运行的 AI 代理量身定制。与传统的检索增强生成 (RAG) 方法不同,Graphiti 持续将用户交互、结构化和非结构化企业数据以及外部信息集成到一个连贯且可查询的图中。该框架支持增量数据更新、高效检索和精确的历史查询,无需完全重新计算图谱,因此非常适合开发交互式、情境感知的 AI 应用程序。 使用 Graphiti
Moondream是一个免费开源的小型的人工智能视觉语言模型,虽然参数量小(Moondream1仅16亿,Moondream2为18.6亿)但可以提供高性能的视觉处理能力,可在本地计算机甚至移动设备或 Raspberry Pi 上运行,能够快速理解和处理输入的图像信息并对用户提出的问题进行解答。该模型由开发人员vikhyatk推出,使用SigLP、Phi-1.5和LLaVa训练数据集和模型权重初始
Aurora是微软研究院推出的13亿参数的大气基础模型,基于从海量大气数据中提取有价值信息,用在预测全球天气模式、空气污染和海洋波浪等大气过程。模型用预训练和微调的架构,处理不同分辨率和压力水平的数据。Aurora在多个预测任务中表现出色,包括高分辨率天气预测、空气污染预测和热带气旋轨迹预测,计算速度比传统数值天气模型快约5000倍。模型提高了预测精度,降低计算成本,为应对气候变化和极端天气事件提
BnbIcons是AI驱动的图标生成工具,能创建类似Airbnb风格的等轴测图标。用户只需输入文字描述或上传参考图片,AI能生成符合要求的图标。提供464+个预制图标,涵盖多种类别和风格,可快速找到所需图标。用户可以批量创建图标,输入一系列类别,可生成整套匹配的图标,节省设计时间。 BnbIcons的主要功能 AI辅助图标生成:通过AI技术,根据用户输入的文本描述或上传的参考图片,快速
Free AI Hairstyle Changer, discover your perfect look! Choose from over 60+ hairstyles, including bob, wavy curls, buzz cut, slicked back, braids, and more
VTable: 不只是高性能的多维数据分析表格,更是行列间创作的方格艺术家!免费,开源,基于Canvas 的 百万数据秒级渲染前端表格组件库 VTable是字节跳动开源可视化解决方案 VisActor 的组件之一。 在现代应用程序中,表格组件是不可或缺的一部分,它们能够快速展示大量数据,并提供良好的可视化效果和交互体验。VTable是一款基于可视化渲染引擎VRender的高性能表格组件库,为用
SmolVLA 是 Hugging Face 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。 SmolVLA的主要功能 多模态输入处理:SmolVLA 能处理多种输入,包括多幅图像、语言指令以及
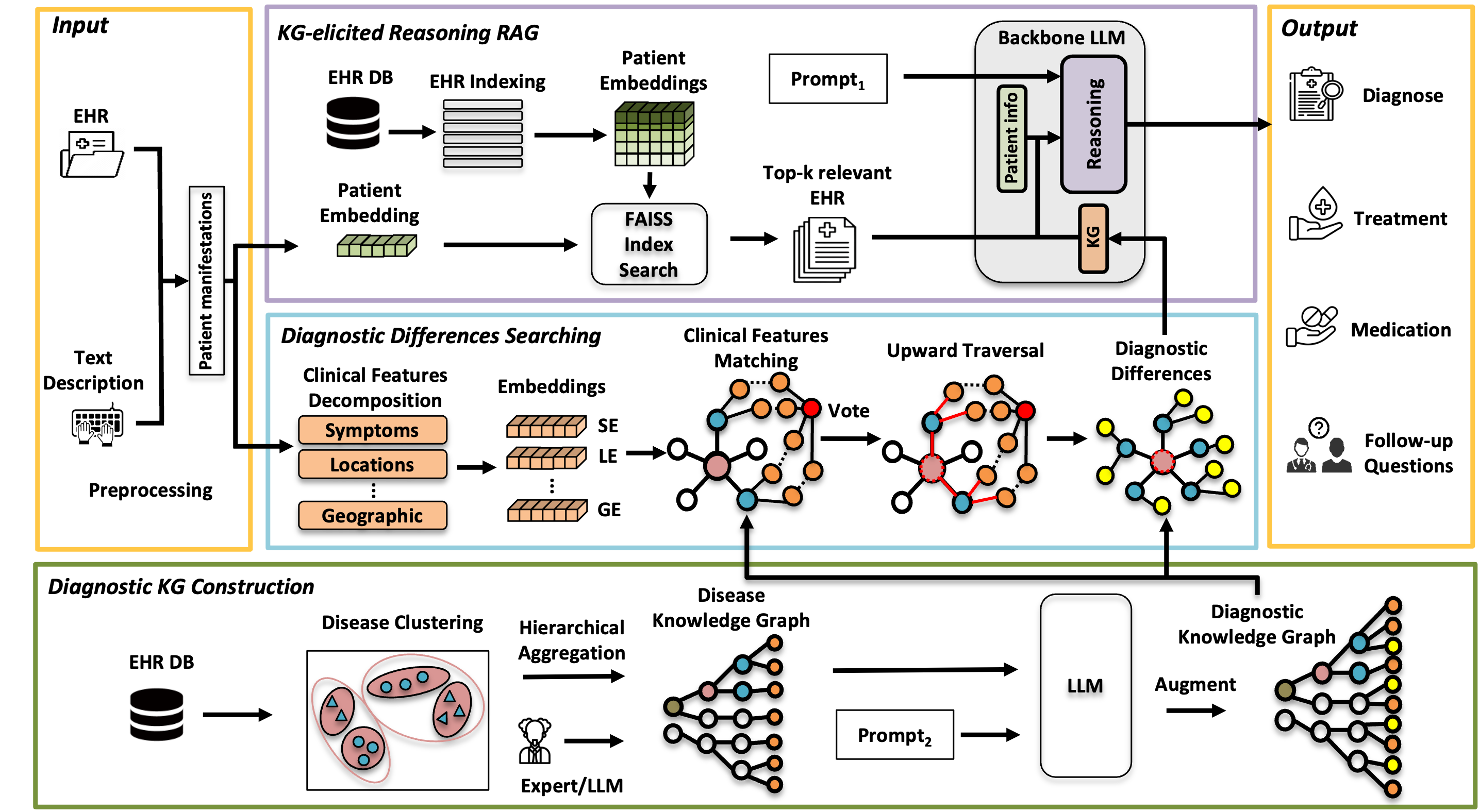
MedRAG是南洋理工大学研究团队提出的医学诊断模型,通过结合知识图谱推理增强大语言模型(LLM)的诊断能力。模型构建了四层细粒度诊断知识图谱,可精准分类不同病症表现,通过主动补问机制填补患者信息空白。MedRAG在真实临床数据集上诊断准确率提升了11.32%,具备良好的泛化能力,可应用于不同LLM基模型。MedRAG支持多模态输入,能实时解析症状并生成精准诊断建议。 MedRAG的主要功能
FairyGen 是大湾区大学推出的动画故事视频生成框架,支持从单个手绘角色草图出发,生成具有连贯叙事和一致风格的动画故事视频。框架借助多模态大型语言模型(MLLM)进行故事规划,基于风格传播适配器将角色的视觉风格应用到背景中,用 3D Agent重建角色生成真实的运动序列,基于两阶段运动适配器优化视频动画的连贯性与自然度。FairyGen 在风格一致性、叙事连贯性和运动质量方面表现出色,为个性化
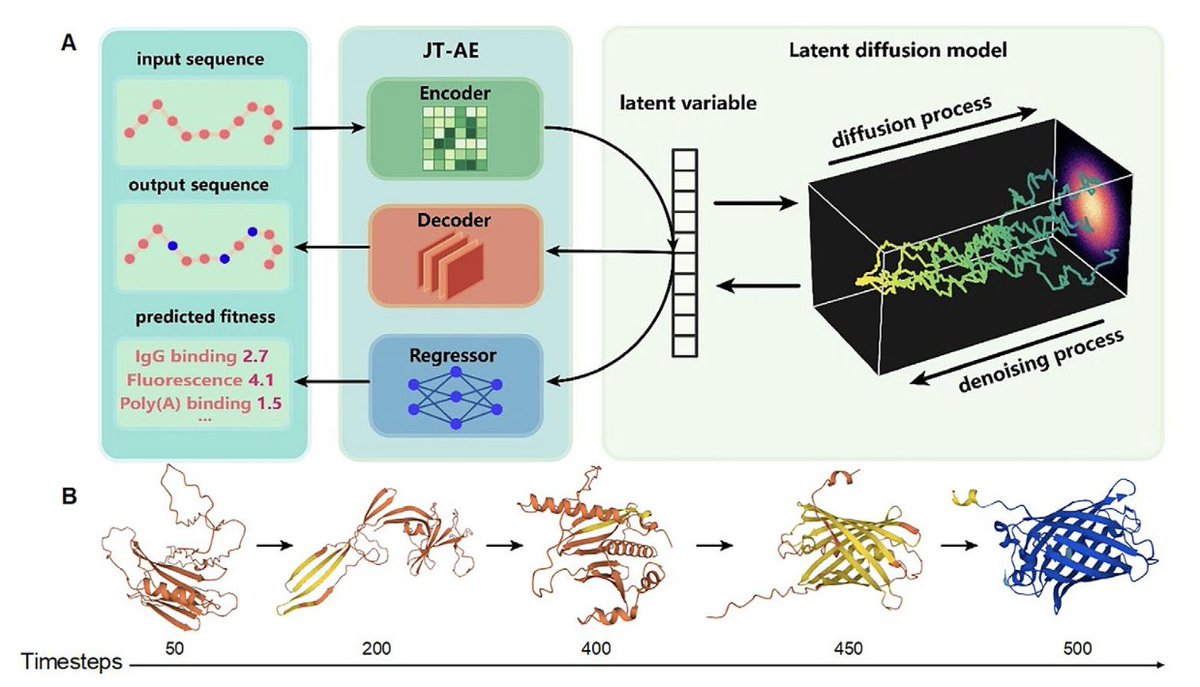
1.PRO-LDM 引入了一种模块化潜在扩散模型,用于全长蛋白质序列设计,该模型兼具无条件生成和功能优化,将准确性与计算效率完美结合。 2. 一项重大创新在于在潜在空间中应用扩散,显著降低采样成本,同时保持生成序列的保真度和多样性。 3. PRO-LDM 通过将条件潜在扩散与监督适应度预测相结合,实现了具有目标特性(例如荧光、溶解度、热/化学稳定性)的蛋白质序列的可控设计。 4. 通过无分类
AudioGenie是腾讯AI Lab团队推出的多模态音频生成工具,能从视频、文本、图像等多种模态输入生成音效、语音、音乐等多种音频输出。工具采用无训练的多智能体框架,通过生成团队和监督团队的双层架构实现高效协同。生成团队负责将复杂的输入分解为具体的音频子事件,通过自适应混合专家(MoE)协作机制动态选择最适合的模型进行生成。监督团队则负责时空一致性验证,通过反馈循环进行自我纠错,确保生成的音频高
Baichuan-M2在HealthBench上得到60.1的高分,以32B的较小尺寸不仅反超OpenAI 最新开源模型gpt-oss120b(得分57.6),更是力压Qwen3-235B、Deepseek R1、Kimi K2等当前世界所有开源大模型。 针对医疗领域用户隐私考虑下的模型私有化部署需求,我们对Baichuan-M2进行了极致轻量化,量化后的模型精度接近无损,可以在RTX409
AIRI 是开源的 AI 虚拟角色灵魂项目,能让用户拥有可互动的数字伴侣。AIRI 支持 Web、macOS 和 Windows 平台,具备多模态交互能力,包括聊天、玩游戏(如《我的世界》《异星工厂》)等。桌面版能独立运行,不干扰其他工作,支持 VRM 和 Live2D 模型,具备自动眨眼、视线追踪等动画效果。AIRI 支持语音交互,能接入多种大语言模型和语音服务。AIRI的官网地址官网地址:ht
只显示前20页数据,更多请搜索
Showing 265 to 281 of 281 results