关键词 "mix sharing" 的搜索结果, 共 17 条, 只显示前 480 条
🪱 MCP Context Template is a repository designed to centrally manage AI tools (MCP) to reduce context sharing costs and improve development productivity.
We're creating a directory site for discovering MCP servers, along with sharing 100 ways to master Claude Code, MCP, and creative uses of computers.
A Model Context Protocol (MCP) server that integrates with the MISP (Malware Information Sharing Platform) to provide threat intelligence capabilities to Large Language Models.
We are building a local MCP server called mix_server ,a working connection to claude for desktop so you can talk to your tools thorugh natural language.
MCP Server for Mixpanel API (talk to your Mixpanel data)
Supporting multiple themes, automatic long text splitting, one-click image export, making your content creation easier and more efficient. Completely free, start using now! MD2Card is a simple and ea
Sharing the latest developments in the world of artificial intelligence. 每天3分钟学习最新的AI前沿信息
Lovart 全球首个设计 Agent 体验 Lovart 的三个特点: 一、全链路设计和执行,一句话搞定 以前的文生图工具,它们所提供的任务是“生成图片”这一环。 而设计 Agent,则像一位“设计执行官”,覆盖从创意拆解到专业交付的整个视觉流程。 从意图拆解 → 任务链 → 最后成品,一句话全搞定。 单次可以执行上
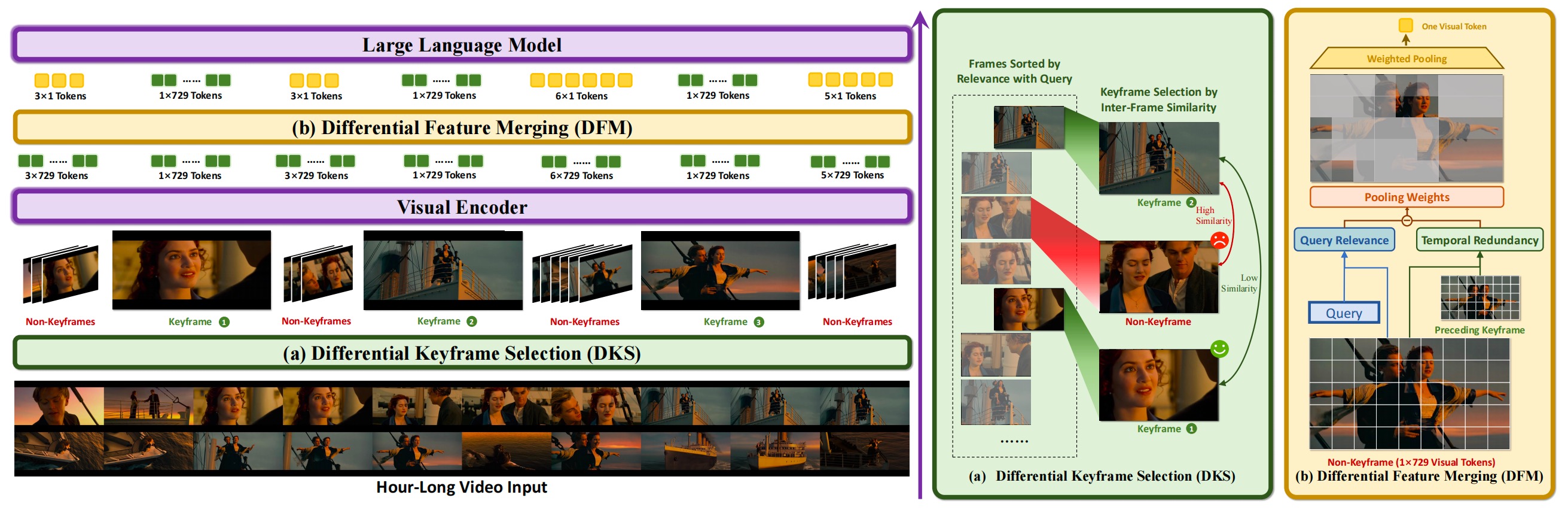
ViLAMP(VIdeo-LAnguage Model with Mixed Precision)是蚂蚁集团和中国人民大学联合推出的视觉语言模型,专门用在高效处理长视频内容。基于混合精度策略,对视频中的关键帧保持高精度分析,显著降低计算成本提高处理效率。ViLAMP在多个视频理解基准测试中表现出色,在长视频理解任务中,展现出显著优势。ViLAMP能在单张A100 GPU上处理长达1万帧(约3小时)
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
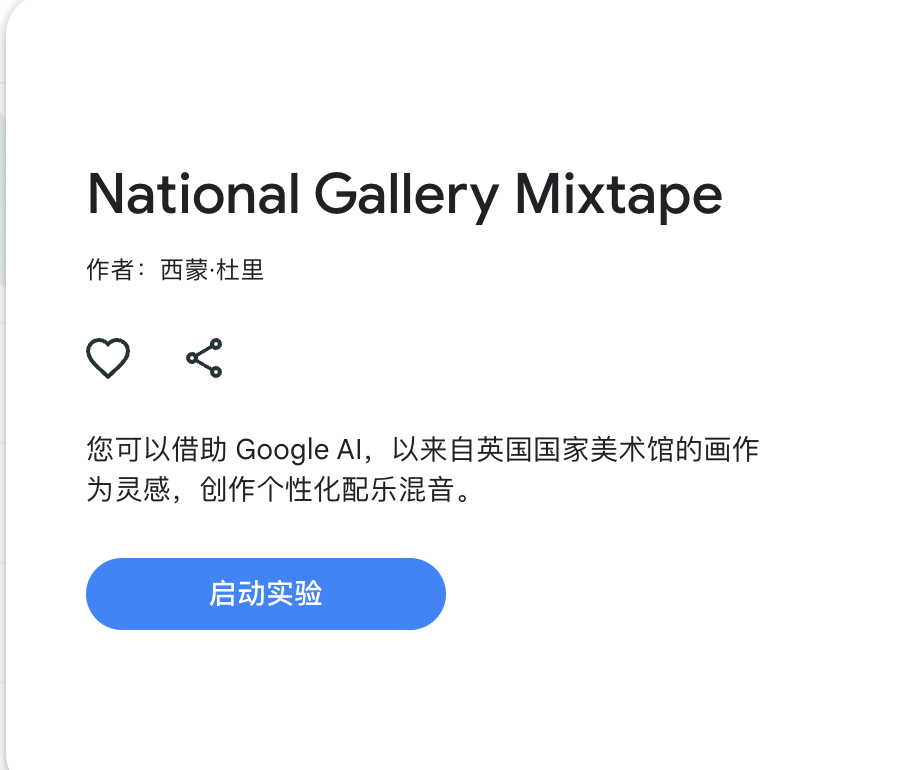
National Gallery Mixtape 是伦敦国家美术馆联合 Google Arts & Culture 推出的 AI 音乐实验工具。汇集了伦敦国家美术馆精选的200幅世界名画,涵盖从文艺复兴时期到现代的各种风格和主题。用户可从这些画作中最多选择6幅,拖放到指定区域,AI会分析画作的色彩、主题、情感和历史背景等元素,生成与之匹配的音乐片段。能通过调整音乐片段的音量、顺序和叠加方式
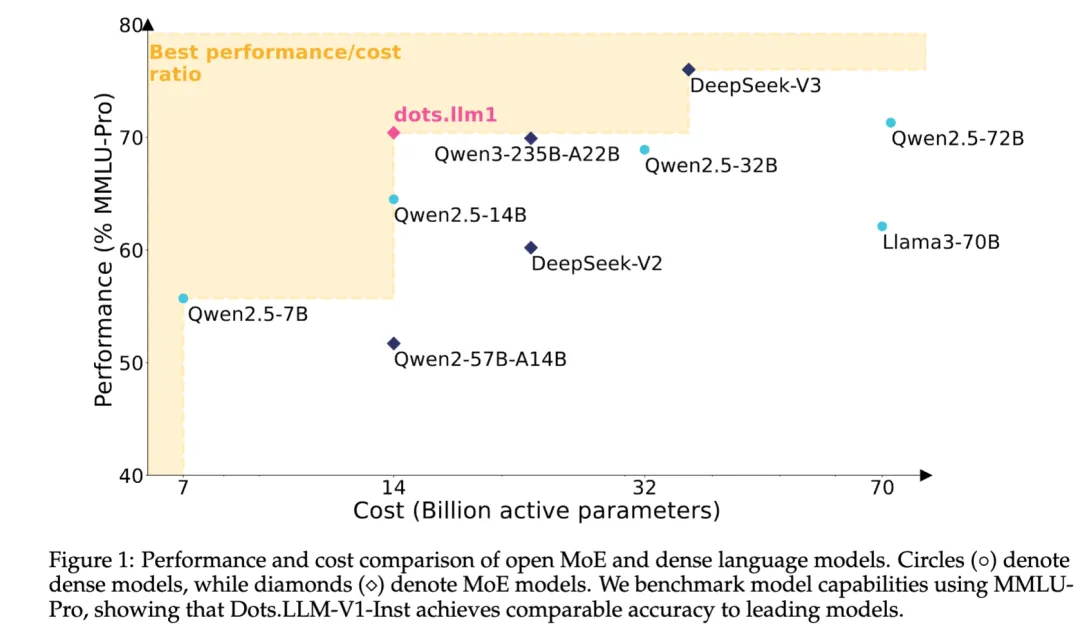
小红书hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源文本大模型 dots.llm1。 dots.llm1是一个中等规模的Mixture of Experts (MoE)文本大模型,在较小激活量下取得了不错的效果。该模型充分融合了团队在数据处理和模型训练效率方面的技术积累,并借鉴了社区关于 MoE 的最新开源成果。hi lab团队开源了所有模型和必要的训练
Open-Lovable 是 Firecrawl 团队推出的开源项目,通过 AI 技术快速将任意网站克隆为现代 React 应用。用户输入目标网站 URL 后,通过 Firecrawl 抓取内容,用 AI 模型生成 React 代码,最终输出完整应用。Open-Lovable用多个 AI 提供商的 API(如 Anthropic、OpenAI 等)实现自动化构建。使用时需注意版权和法律问题,确保行
Mixboard 是谷歌实验室推出的全新 AI 画板工具,由 Nano Banana 提供支持。工具通过自然语言交互,让用户能轻松将任何想法即时可视化。用户输入文本提示或选择预置模板,AI 能生成一系列相关图片。Mixboard 支持批量编辑、组合图片、风格迁移,能对图片进行客观描述、调整文字格式。Mixboard 适用创意设计、家居装饰、派对策划等多种场景,帮助用户快速探索和优化创意。Mixbo
AI Song Maker is an AI-powered platform that turns text and lyrics into custom songs. Create, remix, and produce royalty-free music effortlessly in various styles.
Wan Animate is your ultimate AI character animation and replacement platform powered by Wan 2.2 Animate technology. Simply upload a character image and reference video, then watch Wan Animate bring yo
只显示前20页数据,更多请搜索
Showing 361 to 377 of 377 results