关键词 "payment collection" 的搜索结果, 共 7 条, 只显示前 480 条
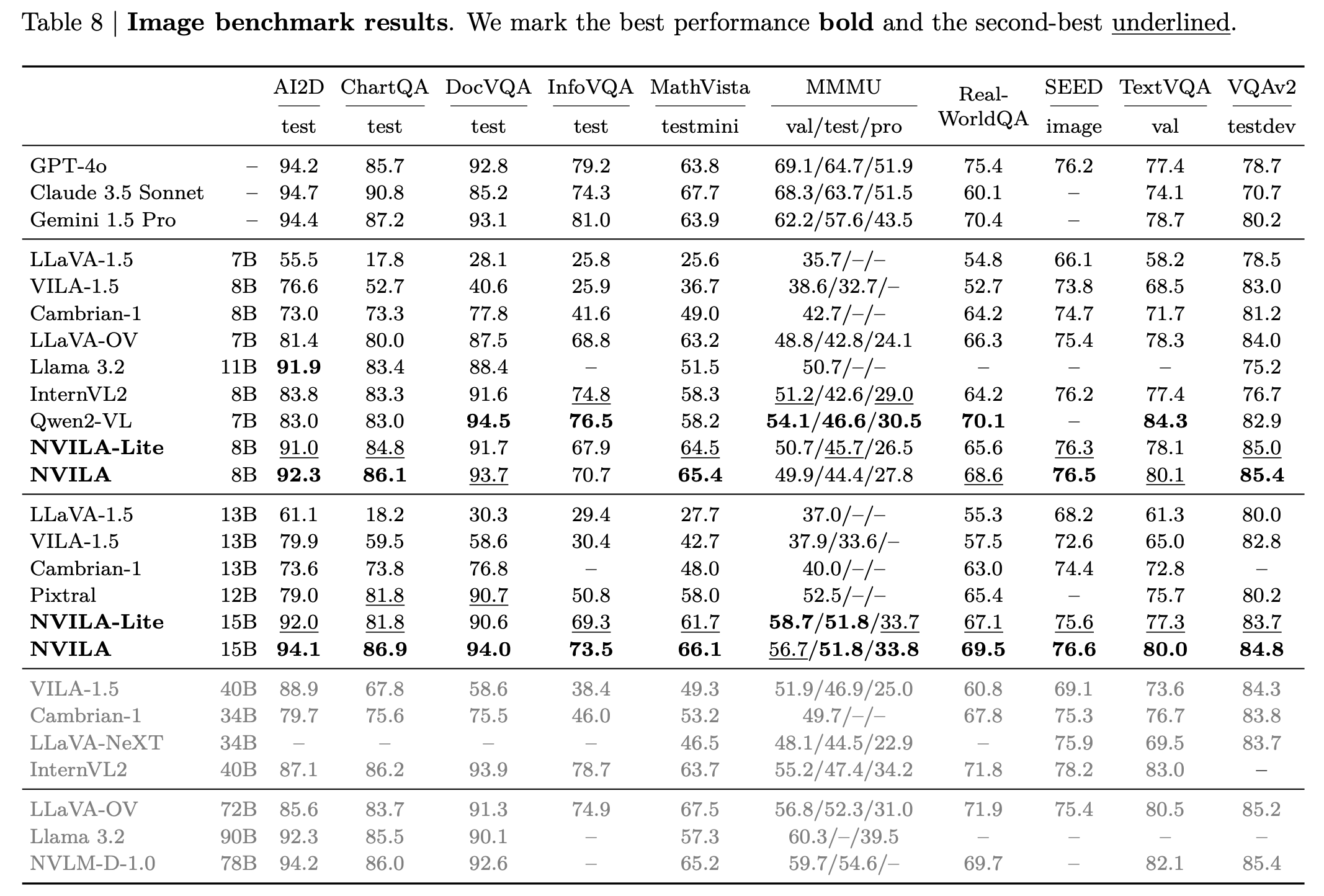
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等
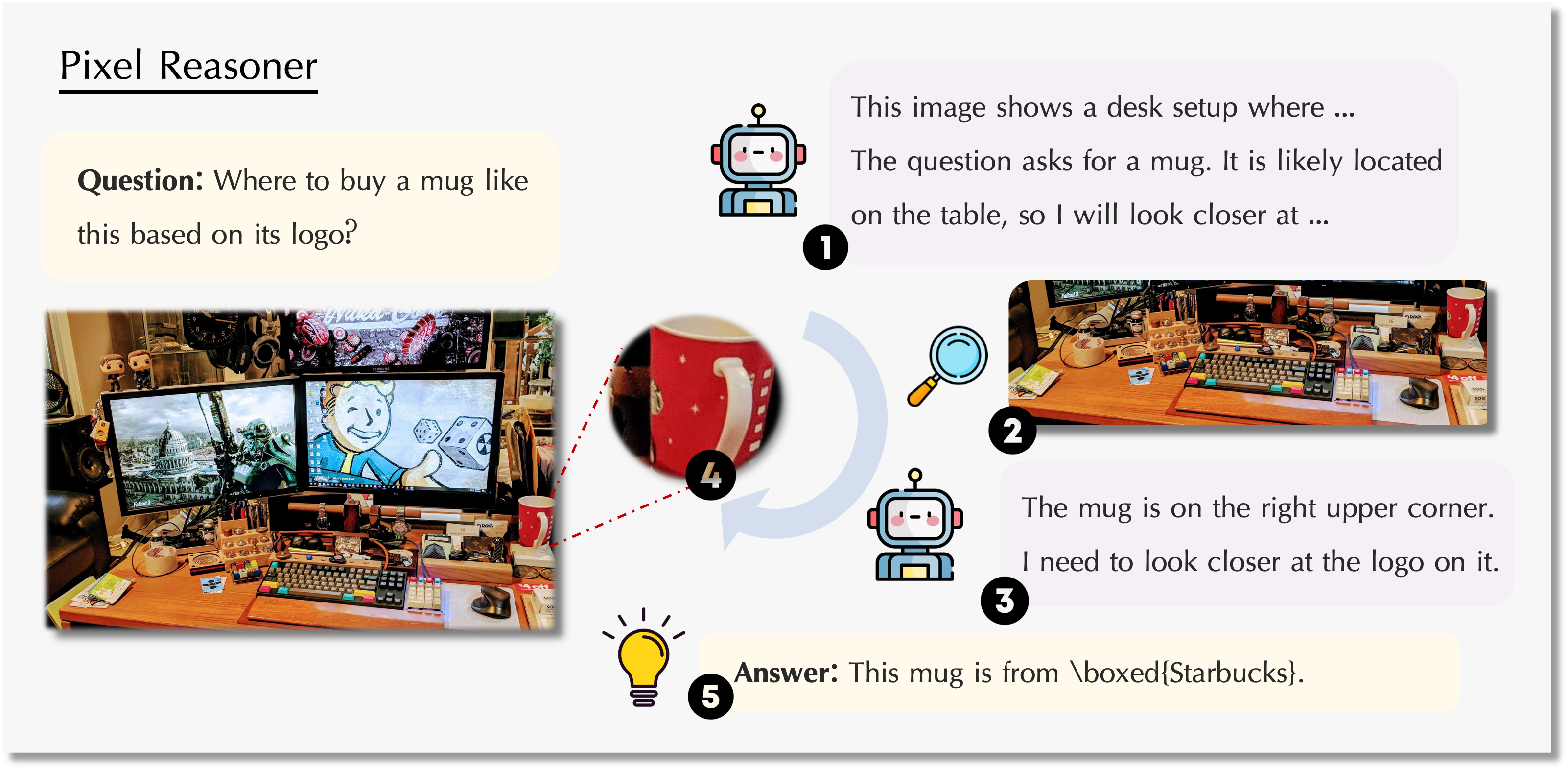
视觉语言模型(VLM),基于像素空间推理增强模型对视觉信息的理解和推理能力。模型能直接在视觉输入上进行操作,如放大图像区域或选择视频帧,更细致地捕捉视觉细节。Pixel Reasoner用两阶段训练方法,基于指令调优让模型熟悉视觉操作,用好奇心驱动的强化学习激励模型探索像素空间推理。Pixel Reasoner在多个视觉推理基准测试中取得优异的成绩,显著提升视觉密集型任务的性能。 Pixel R
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
Lingshu是阿里巴巴达摩院推出的专注于医学领域的多模态大型语言模型。模型支持超过12种医学成像模态,包括X光、CT扫描、MRI等,在多模态问答、文本问答及医学报告生成等任务上展现出卓越的性能。Lingshu基于多阶段训练,逐步嵌入医学专业知识,显著提升在医学领域的推理和问题解决能力。推出7B、32B两个参数版本,其中32B版本在多个医学多模态问答任务中超越GPT-4.1等专有模型。Lingsh
RoboBrain 2.0 是强大的开源具身大脑模型,能统一感知、推理和规划,支持复杂任务的执行。RoboBrain 2.0 包含 7B(轻量级)和 32B(全规模)两个版本,基于异构架构,融合视觉编码器和语言模型,支持多图像、长视频和高分辨率视觉输入,及复杂任务指令和场景图。模型在空间理解、时间建模和长链推理方面表现出色,适用机器人操作、导航和多智能体协作等任务,助力具身智能从实验室走向真实场景
Qianfan-VL 是百度智能云千帆专为企业级多模态应用场景打造的视觉理解大模型。它提供 3B、8B 和 70B 三种尺寸,不仅具备出色的通用能力,还针对 OCR、教育等垂直领域进行了专项强化。该模型基于开源模型,并在百度自研的昆仑芯 P800 上完成了全流程计算任务,展现出卓越的性能和效率。核心功能多尺寸模型:提供从轻量级到大规模的三种版本,满足不同企业和开发者的需求,适用于各种场景,从端上实
只显示前20页数据,更多请搜索
Showing 361 to 367 of 367 results