关键词 "开源模型" 的搜索结果, 共 22 条, 只显示前 480 条
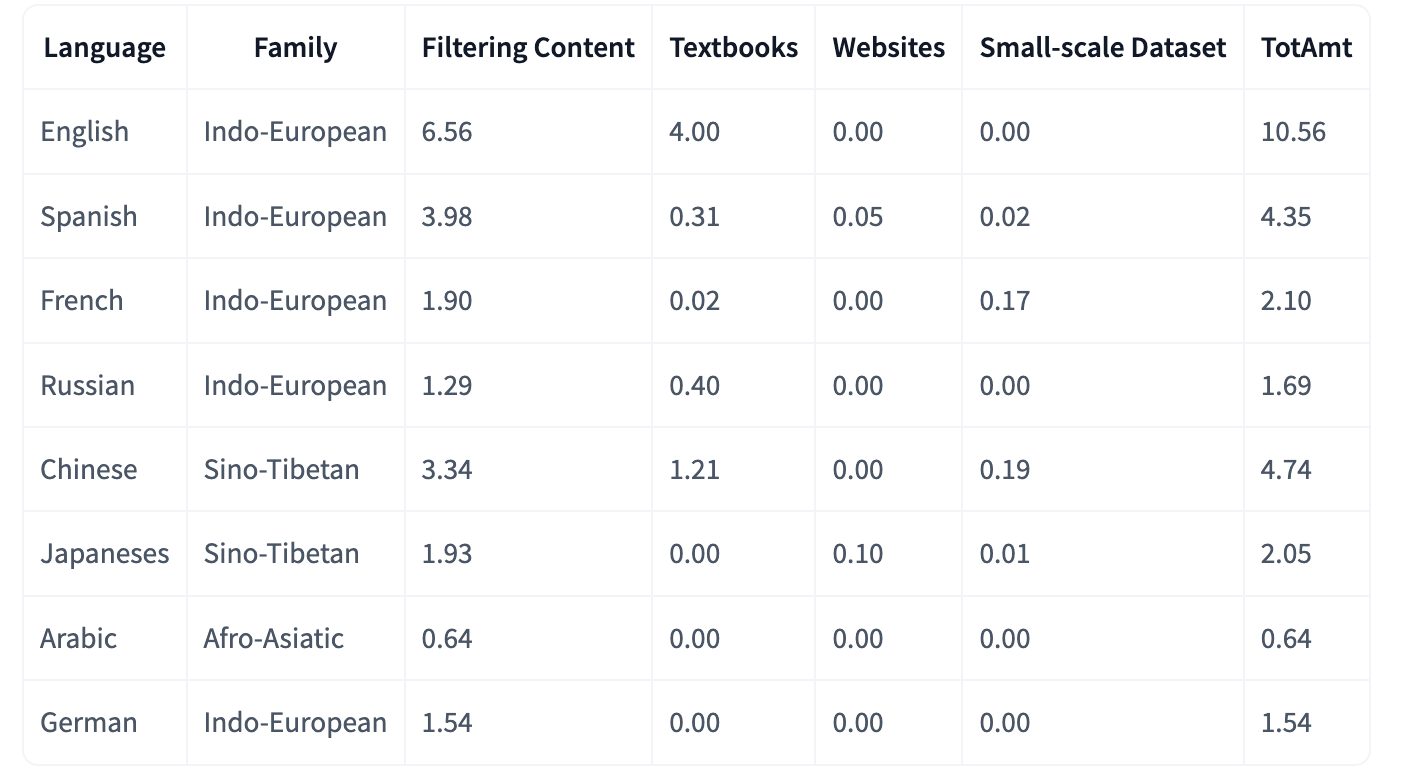
多语言医学语料库 MMedC。该语料库涵盖六种主要语言、约 255 亿标记,并用于通用大语言模型的自回归训练和领域适配。同时,研究者开发了具有推理能力的多语言医学多选问答基准MMedBench,以评估多语言医学模型的性能。在此基础上,通过在 MMedC 上训练多个开源模型,研究者提出了多语言医学大模型MMed-Llama 3。该模型在MMedBench 和英语基准测试中表现出色,在推理能力和问答准
语料库数据集。为了实现多语言医学专用适配,我们构建了一个新的多语言医学语料库(MMedC),其中包含约 255 亿个标记,涵盖 6 种主要语言,可用于对现有的通用 LLM 进行自回归训练。 基准。为了监测医学领域多语言法学硕士 (LLM) 的发展,我们提出了一个新的、具有合理性的多语言医学多项选择题答疑基准,称为 MMedBench。 模型评估。我们在基准测试中评估了许多流行的 LLM,以及在
Langchain-Chachat(原Langchain-ChatGLM)基于Langchain与ChatGLM、Qwen与Llama等语言模型的RAG与Agent应用| Langchain-Chatatch(以前称为 langchain-ChatGLM),基于本地知识的 LLM(如 ChatGLM、Qwen 和 Llama)RAG 和带有 langchain 的代理应用程序 ✅ 本项目支持主流
Wan2.1,这是一套全面开放的视频基础模型,旨在突破视频生成的界限。Wan2.1提供以下主要功能: 👍 SOTA 性能:Wan2.1在多个基准测试中始终优于现有的开源模型和最先进的商业解决方案。 👍支持消费级 GPU:T2V-1.3B 型号仅需 8.19 GB VRAM,兼容几乎所有消费级 GPU。它可在约 4 分钟内在 RTX 4090 上生成一段 5 秒的 480P 视频(无需量化等
腾讯混元大模型旗下最新发布的Hunyuan3D-2.0系列开源模型,迎来了五款产品(Turbo、Pro、Standard、Lite、Vision)的全系列开源,构建起完整的工具链体系,标志着中国大模型技术首次在多模态领域实现完整开源布局。从30秒生成高精度3D资产的开源框架,到覆盖文本、图像、视频的全模态开源体系,腾讯混元大模型正以开放姿态引领一场全球范围内的数字创作革命。 这一突破得益于腾讯自
鲸智社区·大模型公共服务平台提供丰富的开闭源AI模型、数据集、开发工具等资源,构建大模型生态一站式解决方案,助力开发者探索和应用大模型技术,帮助企业快速选型和部署大模型应用。
Muyan-TTS,一款低成本、具备良好二次开发支持的模型并完全开源,以方便学术界和小型应用团队的音频技术爱好者。 当前开源的Muyan-TTS版本由于训练数据规模有限,致使其仅对英语语种呈现出良好的支持效果。不过,得益于与之同步开源的详尽训练方法,从事相关行业的开发者能够依据自身实际业务场景,灵活地对Muyan-TTS进行功能升级与定制化改造。 01. H
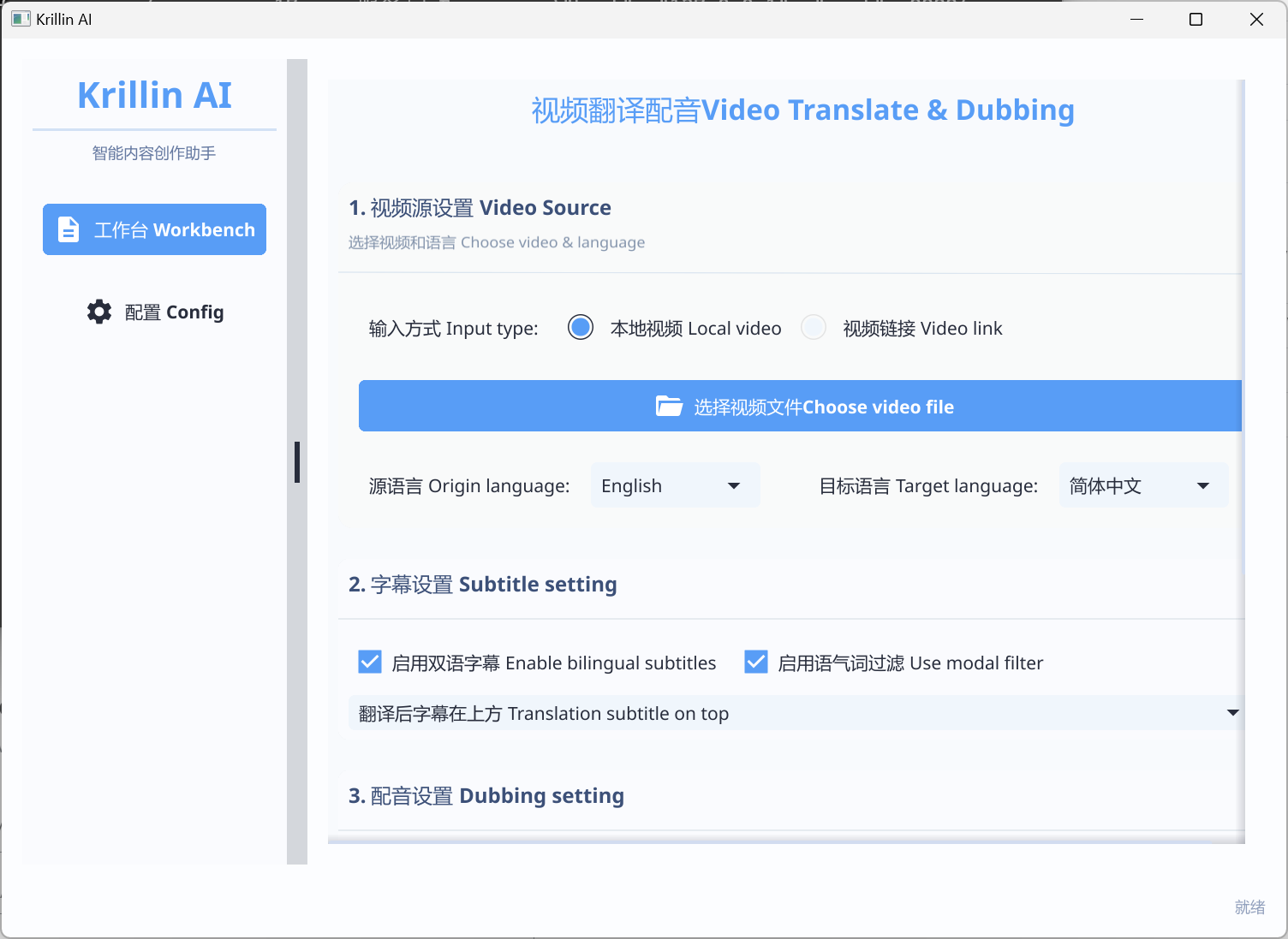
极简部署AI视频翻译配音工具 KrillinAI-一款AI视频翻译配音工具 提供了从视频下载,音频提取,音频转录,文本切割,翻译,对齐,到最终合成适配抖音,哔哩哔哩,小红书,视频号,快手等主流平台格式的一站式解决方案。 基于AI大模型的视频翻译和配音工具,专业级翻译,一键部署全流程,可以生成适配抖音,小红书,哔哩哔哩,视频号,TikTok,Youtube Shorts等形态的
昆仑万维正式开源(17B+)Matrix-Game大模型,即Matrix-Zero世界模型中的可交互视频生成大模型。Matrix-Game是Matrix系列在交互式世界生成方向的正式落地,也是工业界首个开源的10B+空间智能大模型,它是一个面向游戏世界建模的交互式世界基础模型,专为开放式环境中的高质量生成与精确控制而设计。 空间智能作为AI时代的重要前沿技术,正在重塑我们与虚拟世界的
BILIVE 是基于 AI 技术的开源工具,专为 B 站直播录制与处理设计。工具支持自动录制直播、渲染弹幕和字幕,支持语音识别、自动切片精彩片段,生成有趣的标题和风格化的视频封面。BILIVE 能自动将处理后的视频投稿至 B 站,综合多种模态模型,兼容超低配置机器,无需 GPU 即可运行,适合个人用户和小型服务器使用。 1. Introduction Have you notice
Devstral是Mistral AI和All Hands AI推出的专为软件工程任务设计的编程专用模型。Devstral在解决真实世界软件问题上表现出色,在SWE-Bench Verified基准测试中,得分46.8%大幅领先其他开源模型。Devstral支持处理复杂代码库中的上下文关系、识别组件间联系及发现细微的代码错误。Devstral轻量级,能在单个RTX 4090或32GB内存的Mac上
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数,其中70亿为活跃参数。采用混合变换器专家架构(MoT),通过两个独立编码器分别捕捉图像的像素级和语义级特征。BAGEL遵循“下一个标记组预测”范式进行训练,使用海量多模态标记数据进行预训练,包括语言、图像、视频和网络数据。在性能方面,BAGEL在多模态理解基准测试中超越了Qwen2.5-VL和InternVL-2.5等顶级开源视觉语言模型
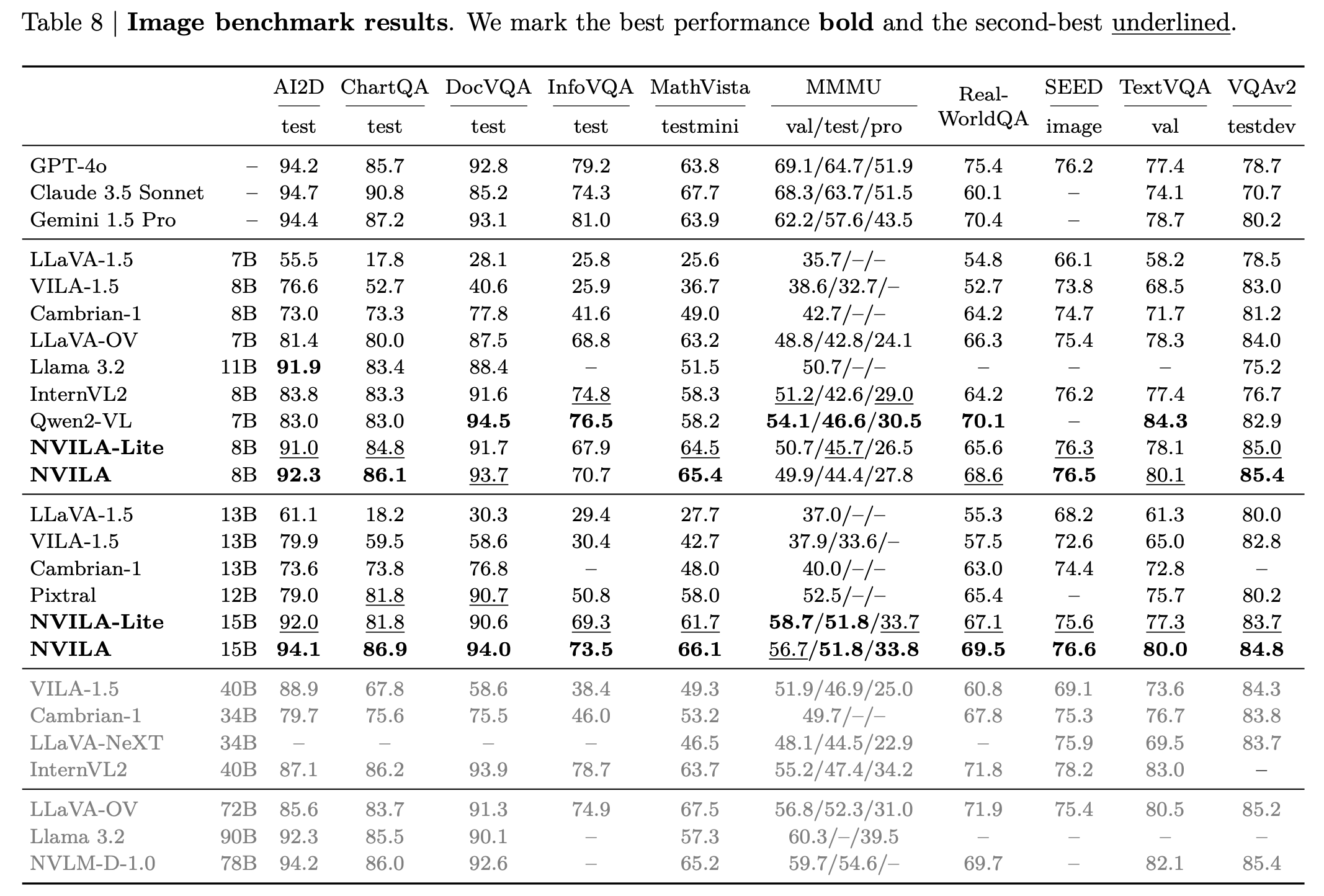
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等
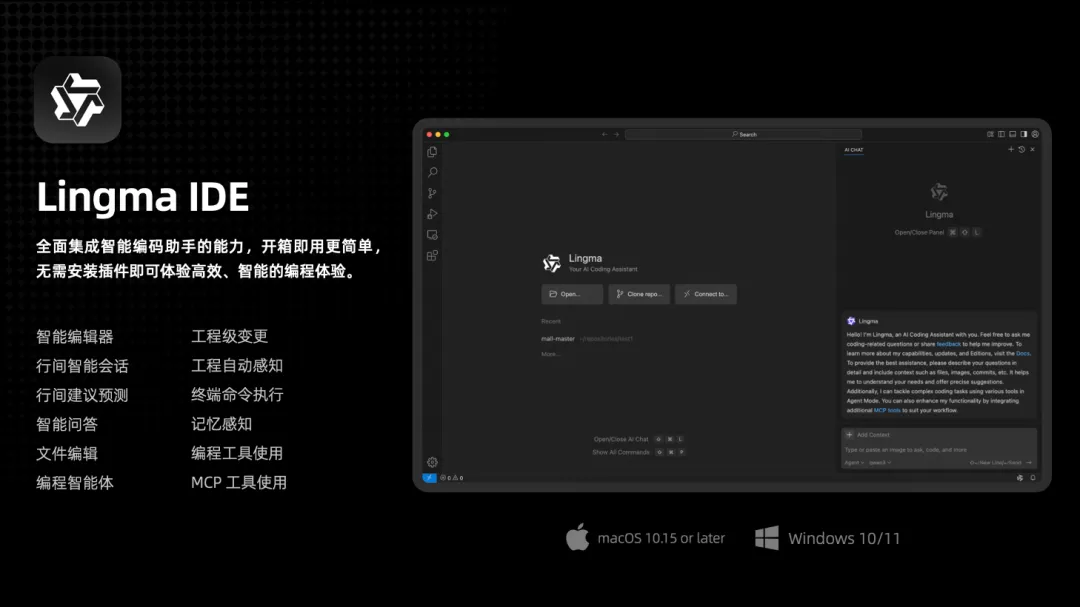
# 核心亮点 支持最强开源模型千问3,其代码能力达到业界领先水平,同时支持MCP协议,具备强大的工具调用能力,可以帮助开发者快速开发智能体应用。 全面集成通义灵码智能编码助手(即通义灵码插件)的能力,无需安装插件开箱即用,直接体验高效、智能的编程体验。 自带编程智能体模式,开发者只需描述编码任务,通义灵码便可以自主地进行工程感知、代码检索、执行终端、调用MCP工具等,
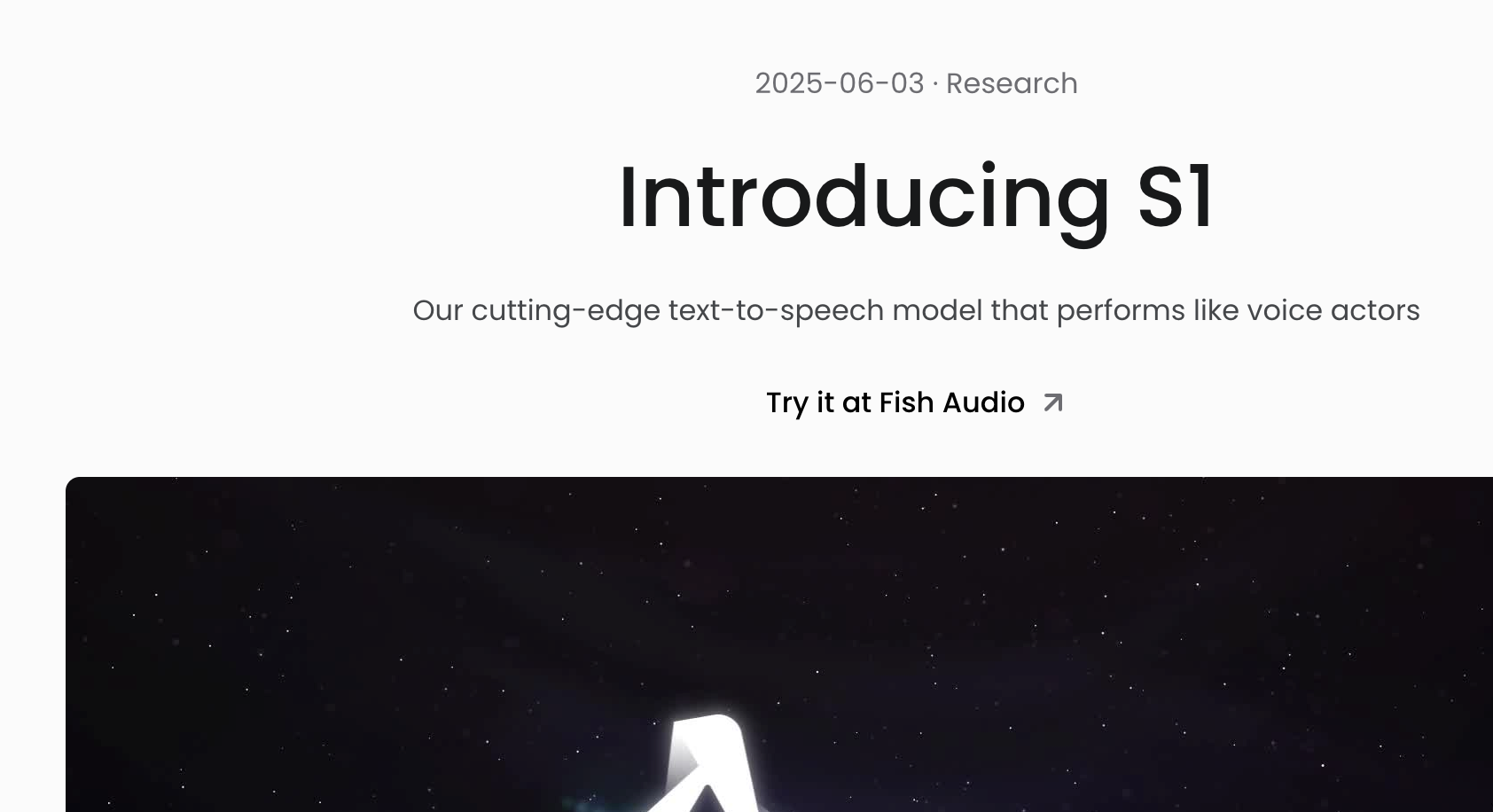
OpenAudio S1是Fish Audio推出的文本转语音(TTS)模型,基于超过200万小时的音频数据训练,支持13种语言。采用双自回归(Dual-AR)架构和强化学习与人类反馈(RLHF)技术,生成的声音高度自然、流畅,几乎与人类配音无异。模型支持超过50种情感和语调标记,用户可通过自然语言指令灵活调整语音表达。OpenAudio S1支持零样本和少样本语音克隆,仅需10到30秒的音频样本
Kimi-Dev是Moonshot AI推出的开源代码模型,专为软件工程任务设计。模型拥有 72B 参数量,编程水平比最新的DeepSeek-R1还强,和闭源模型比较也表现优异。在 SWE-bench Verified数据集上达到60.4%的性能,超越其他开源模型,成为当前开源模型中的SOTA。Kimi-Dev 基于强化学习和自我博弈机制,能高效修复代码错误、编写测试代码。模型基于MIT协议开源,
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
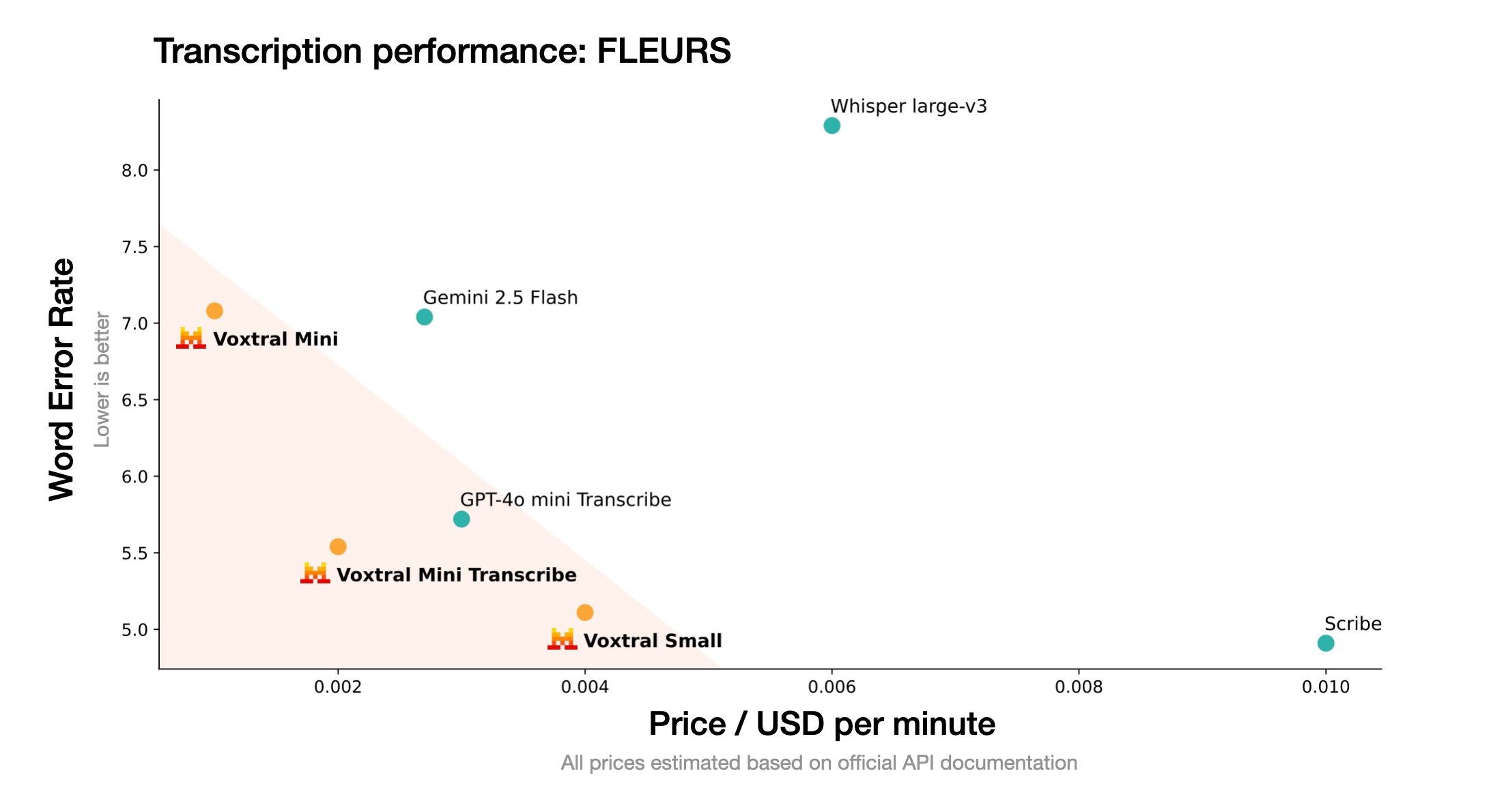
Voxtral 是 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。Voxtral提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音
Baichuan-M2在HealthBench上得到60.1的高分,以32B的较小尺寸不仅反超OpenAI 最新开源模型gpt-oss120b(得分57.6),更是力压Qwen3-235B、Deepseek R1、Kimi K2等当前世界所有开源大模型。 针对医疗领域用户隐私考虑下的模型私有化部署需求,我们对Baichuan-M2进行了极致轻量化,量化后的模型精度接近无损,可以在RTX409
Youtu-agent 是腾讯优图实验室推出的开源智能体框架,用在构建、运行和评估自主智能体。框架基于开源模型DeepSeek-V3实现领先性能,支持多种模型 API 和工具集成,具备强大的智能体能力,如数据分析、文件处理和深度研究。框架用灵活的架构设计,支持 YAML 配置和自动智能体生成,简化开发流程。Youtu-agent 在 WebWalkerQA 和 GAIA 基准测试中表现出色,适用智
MiroMind:由陈天桥先生创立的预测型 AI 平台MiroMind 是由陈天桥推出的一个专注于 AI 领域的平台,致力于开发全球领先的预测型大模型。该平台的核心理念是让 AI “记住过去、洞察未来”,通过其独特的记忆驱动机制,帮助 AI 进行更精准的预测与决策。MiroMind 的主要产品包括:MiroThinker:一个开源的深度研究模型,在 GAIA 等基准测试中表现出色,超越了许多同类开
Qianfan-VL 是百度智能云千帆专为企业级多模态应用场景打造的视觉理解大模型。它提供 3B、8B 和 70B 三种尺寸,不仅具备出色的通用能力,还针对 OCR、教育等垂直领域进行了专项强化。该模型基于开源模型,并在百度自研的昆仑芯 P800 上完成了全流程计算任务,展现出卓越的性能和效率。核心功能多尺寸模型:提供从轻量级到大规模的三种版本,满足不同企业和开发者的需求,适用于各种场景,从端上实
只显示前20页数据,更多请搜索