关键词 "文本生成交互式 3D 场景" 的搜索结果, 共 24 条, 只显示前 480 条
VikingDB 是火山引擎推出的高性能向量数据库,专为处理海量高维向量数据设计。VikingDB 支持实时同步、异步写入等多种数据写入方式,具备自研的 HNSW、IVF 等高效索引算法,可实现百亿级向量的毫秒级检索,兼容稠密与稀疏向量检索。VikingDB 提供 SaaS 控制台、API 和多种语言的 SDK,支持自动弹性扩容,广泛应用在多模态搜索、智能推荐、RAG 场景及记忆库构建等领域,助力
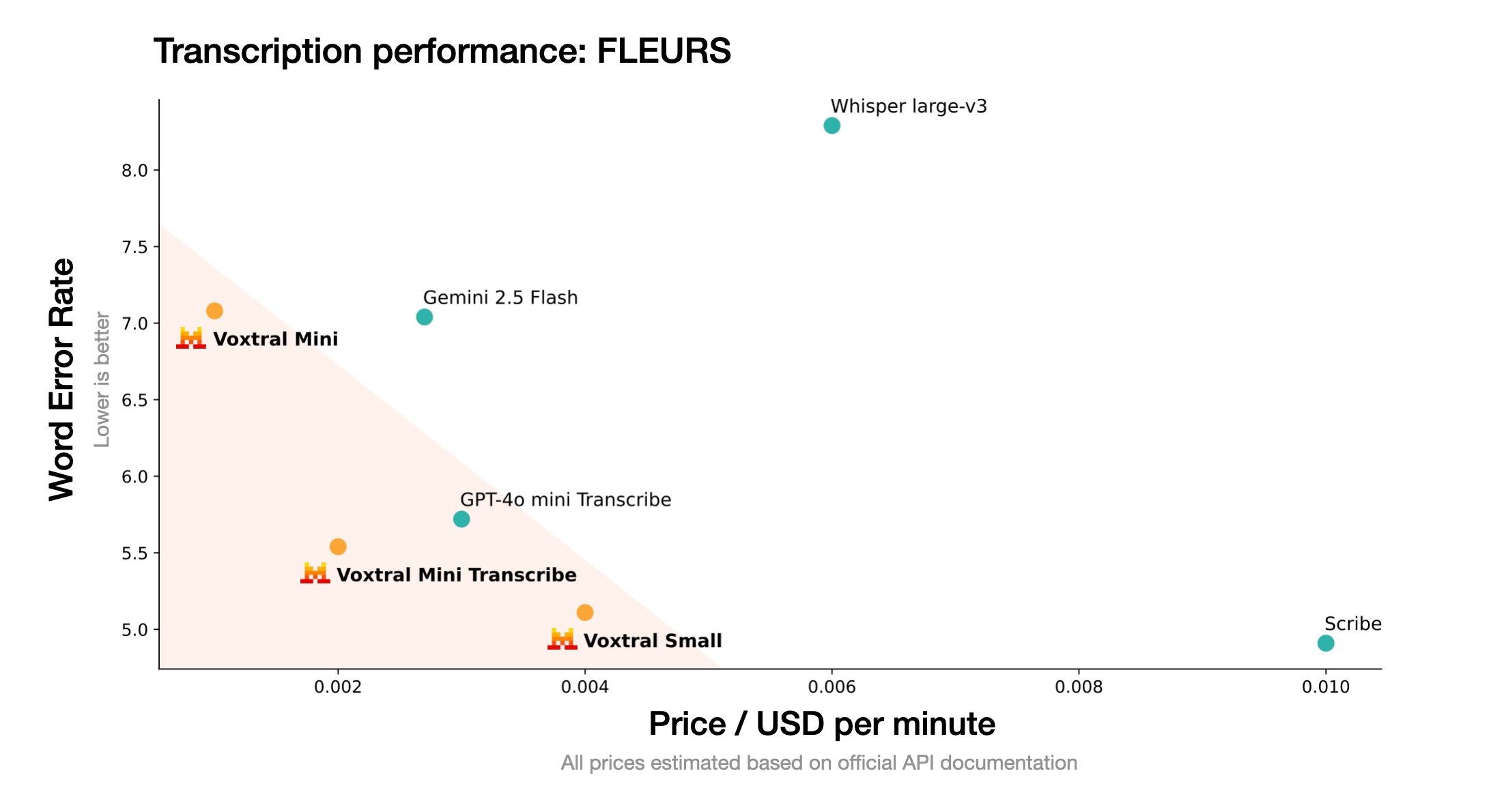
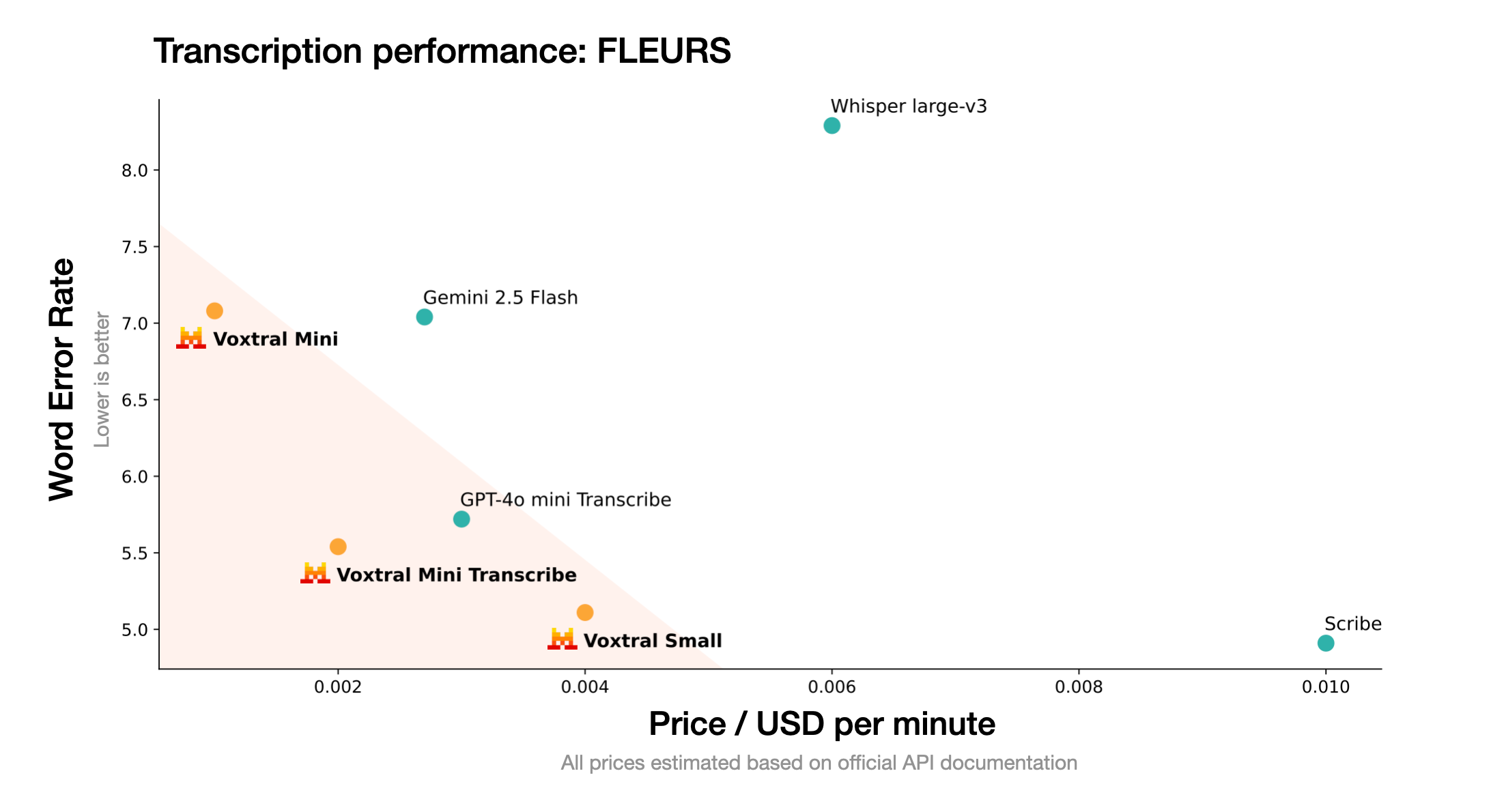
Voxtral 是 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。Voxtral提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音
业界首个开源高完成度轻量化通用多智能体产品(JoyAgent-JDGenie) 解决快速构建多智能体产品的最后一公里问题 简介 当前相关开源agent主要是SDK或者框架,用户还需基于此做进一步的开发,无法直接做到开箱即用。我们开源的JoyAgent-JDGenie是端到端的多Agent产品,对于输入的query或者任务,可以直接回答或者解决。例如用户query"给我做一个最
来福是北京耳朵时间科技推出的AI私人电台应用,应用主打AI语音驱动的“陪伴型内容”,结合语音合成与场景感知实现个性化播报,为用户提供沉浸式的音频体验。用户用语音交互点播节目、提问或聊天,享受7×24小时的声音陪伴。应用融合播客、智能语音助手与定制内容推荐的多重属性,用AI生成内容替代传统主播,重新定义私人电台的使用体验。 来福官网: https://laifu.fm/ 也可以下载APP使用
Copy2AI 是 AI创作助手,帮助提升用户的工作与创作效率。Copy2AI 包含三大核心产品,智能剪贴板,支持内容分析、翻译和润色;智能创作助手,提供灵感激发和文案生成;智能聊天助手,支持自然语言对话和文件分析。Copy2AI 支持本地AI部署,确保隐私安全,兼容Windows、macOS和Linux系统。Copy2AI基于强大的AI功能,适用日常办公、内容创作和生活场景,能成为用户得力助手。
Mistral AI,最新发布了首个开源语音模型:Voxtral语音理解模型系列! 该模型包含24B和3B两个参数规模的版本,均基于Apache 2.0许可证开源,同时提供API服务接口。 Voxtral模型支持32k token的上下文窗口,能够处理长达30分钟的音频转录任务或40分钟的语义理解任务,在各项基准测试指标上全面超越目前主流的开源语音转录模型Whisper large-v3。
PhotoG是全球首个内容营销端对端智能体,实现了基于大语言模型智能规划的全模态内容生成与自适应工具调用,致力于构建等同完整传统内容营销团队的全链路智能化。目前产品获得家具、鞋服、珠宝等领域数十家国际化品牌和超过十万海外用户的认可。 仅需一张产品图与自然语言,即可通过多智能体全自动生成基于市场调研和竞争格局的包含营销图片、营销视频、3D模型、营销文案、电商产品详情页、优化标题、描述和 SEO 等内
dots.ocr 是小红书 hi lab 开源的多语言文档布局解析模型。模型基于 17 亿参数的视觉语言模型(VLM),能统一进行布局检测和内容识别,保持良好的阅读顺序。模型规模虽小,但性能达到业界领先水平(SOTA),在 OmniDocBench 等基准测试中表现优异,公式识别效果能与Doubao-1.5和 gemini2.5-pro 等更大规模模型相媲美,在小语种解析方面优势显著。dots.o
SelectYet是实用的AI文献分析工具,基于先进的AI技术和“记忆摘要”技术,为研究人员提供高效便捷的文献处理服务。用户只需输入研究主题、上传PDF文献,设置自定义分析选项,可快速启动分析。工具能对海量文献进行结构化分析,快速提取关键信息,形成文献综述,加速信息筛选和整理的过程。SelectYet接入了deepseek-R1/V3模型,未来将融合更多模型的优势,提升分析的准确性和效率。 Se
LandPPT 是AI演示文稿生成平台,能将文档内容快速转换为专业的 PPT 演示文稿。LandPPT支持 OpenAI、Claude、Gemini 等多种 AI 模型,兼容 PDF、Word、Markdown 等文件格式,支持智能解析内容,生成结构清晰的大纲和精美的 PPT 页面。平台提供丰富的模板系统和自定义功能,用户基于现代化的 Web 界面进行可视化编辑、实时预览和多格式导出。LandPP
DreamVVT 是字节跳动和清华大学(深圳)联合推出的视频虚拟试穿(Video Virtual Try-On, VVT)技术,基于扩散 Transformer(DiTs)框架,通过两阶段方法实现高保真且时间连贯的虚拟试穿效果。第一阶段从输入视频中采样关键帧,结合视觉语言模型(VLM)生成语义一致的试穿图像;第二阶段利用骨骼图和运动信息,结合预训练视频生成模型,确保视频的动态连贯性。DreamVV
MemU 是面向AI情感陪伴开源的AI记忆框架。MemU 能记住用户与 AI 的每一次对话,提取重点并建立知识图谱,让 AI 真正理解用户。MemU 的记忆会自主进化,随着使用不断优化。MemU 支持快速集成,只需几行代码能让 AI 拥有持久记忆。相比其他框架,MemU 准确率高达92%,成本降低90%,检索速度快至50毫秒。在情感陪伴、教育等其他场景,MemU 都能成为用户贴心的智能伙伴。 M
Ludo.ai 是强大的AI游戏开发平台,能帮助开发者从创意构思到实际开发的全过程。平台提供丰富的功能,包括游戏概念生成、AI 驱动的 3D 资产和图像生成、自定义精灵动画、视频生成、可玩原型制作、市场趋势分析、代码生成等。基于这些工具,开发者能快速生成创意、优化设计、验证想法,加速开发流程。 Ludo.ai的官网地址 官网地址:https://ludo.ai/
Aluo AI 是专为电商卖家和内容创作者设计的 AI 图像处理平台。通过先进的 AI 技术,帮助用户在短短 30 秒内将普通产品图片转变为专业级的营销视觉内容。平台的核心功能包括高精度的背景去除、智能产品图片生成以及强大的 AI 图片编辑工具。用户无需任何设计经验或复杂软件,只需上传图片,AI 能自动识别去除背景,生成高质量的产品展示图,提供丰富的场景模板供选择。 Aluo AI的主要功能
TextureNoise 是强大的在线3D纹理生成与编辑工具,帮助用户快速高效地创建高质量纹理。通过快速生成功能,能在几秒钟内生成令人惊叹的纹理,显著提升工作流程效率,节省时间。TextureNoise 提供画笔工具,支持用户对纹理的特定区域进行精确编辑和细节修饰,确保所有编辑和修复无缝融合,保持纹理的整体一致性。支持通用文件格式,与任何数字内容创作软件(如Blender、Maya等)完全兼容。
Baichuan-M2在HealthBench上得到60.1的高分,以32B的较小尺寸不仅反超OpenAI 最新开源模型gpt-oss120b(得分57.6),更是力压Qwen3-235B、Deepseek R1、Kimi K2等当前世界所有开源大模型。 针对医疗领域用户隐私考虑下的模型私有化部署需求,我们对Baichuan-M2进行了极致轻量化,量化后的模型精度接近无损,可以在RTX409
Eleven Music 是 ElevenLabs 推出的 AI 音乐生成工具,能根据简单的文本提示快速生成高质量、定制化的音乐作品,支持多种风格、语言和场景。用户能通过自然语言描述调整歌曲的风格、节奏、歌词等,支持逐段编辑,实现无缝过渡和精确的情绪转换。生成的音乐适用电影、广告、游戏等多种商业用途,支持多语言歌词创作,提供工作室级别的音频输出,是音乐创作者、企业和广告商的理想选择。
Sim 是开源的 AI Agent 工作流构建工具。Sim通过轻量级、拖拽式的 Figma 风格界面,让开发者无需复杂编码能快速构建和部署 AI 工作流。Sim 支持主流的大型语言模型(LLM)和多种工具(如 Slack、GitHub 等)的无缝集成,能自动化执行任务,如代码审查、客户支持、数据分析等。Sim 支持实时协作和模块化设计,适合团队共享编辑和适配多种业务场景。Sim的主要功能拖拽式工作
Elser AI 是专注于动漫创作的生成式人工智能平台。核心功能是通过 AI 技术帮助用户快速生成高质量的漫画内容,包括角色、场景、分镜和剧本等。平台的 Comic AI 2.0 版本增加了多种风格和高级模型,用户可以根据自己的需求选择不同的漫画风格,如日漫、美漫和国漫等。Elser AI 提供了推荐内容和最新发布的作品,供用户浏览和参考。Elser AI的官网地址官网地址:https://com
Youtu-agent 是腾讯优图实验室推出的开源智能体框架,用在构建、运行和评估自主智能体。框架基于开源模型DeepSeek-V3实现领先性能,支持多种模型 API 和工具集成,具备强大的智能体能力,如数据分析、文件处理和深度研究。框架用灵活的架构设计,支持 YAML 配置和自动智能体生成,简化开发流程。Youtu-agent 在 WebWalkerQA 和 GAIA 基准测试中表现出色,适用智
FramePackLoop 是基于 FramePack 推出的无限循环视频生成工具。工具通过创建主视频和连接视频,将视频组合成循环视频,适用视频背景、图标等场景。用户能自定义视频长度、循环次数等参数,支持 LoRA 模型和批量生成功能。工具提供丰富的自定义选项,适合视频制作和游戏开发等多种用途。FramePackLoop的项目地址GitHub仓库:https://github.com/red-po
Typeless是智能语音转录工具,能自动去除语音中的填充词和重复内容,能根据上下文自动调整语气和格式。Typeless支持100多种语言,能添加个人词典,确保转录准确。Typeless注重隐私,零数据保留,所有记录仅存储于本地。应用适用会议、写作和多任务处理等多种场景,让用户专注于表达,将语音转化为高效工作的利器,让思想自然流淌。官网地址官网地址:https://www.typeless.com
OmniHuman-1.5 字节推出的先进的AI模型,能从单张图片和语音轨道生成富有表现力的数字人动画。模型基于双重系统认知理论,融合多模态大语言模型和扩散变换器,模拟人类的深思熟虑和直觉反应。模型能生成动态的多角色动画,支持通过文本提示进行细化,实现更精准的动画效果。OmniHuman-1.5 的动画具有复杂的角色互动和丰富的情感表现,为动画制作和数字内容创作带来全新的可能性,大大提升创作效率和
LoomlyAI 是专注于视觉内容解决方案的 AI 平台,提供 AI 模特和智能换装功能。基于 AI 模型取代传统模特拍摄,快速生成高质量的商业图片和视频,解决模特拍摄成本高、版权复杂和流程繁琐的问题。平台产品亮点包括无 AI 感的多样化模特库、10 秒快速生成的智能换装功能及一键生成视频的功能。LoomlyAI 适用电商、社交媒体和内容创作,帮助用户高效制作视觉内容,提升商业价值。LoomlyA
只显示前20页数据,更多请搜索
Showing 385 to 408 of 441 results