关键词 "语音识别" 的搜索结果, 共 21 条, 只显示前 480 条
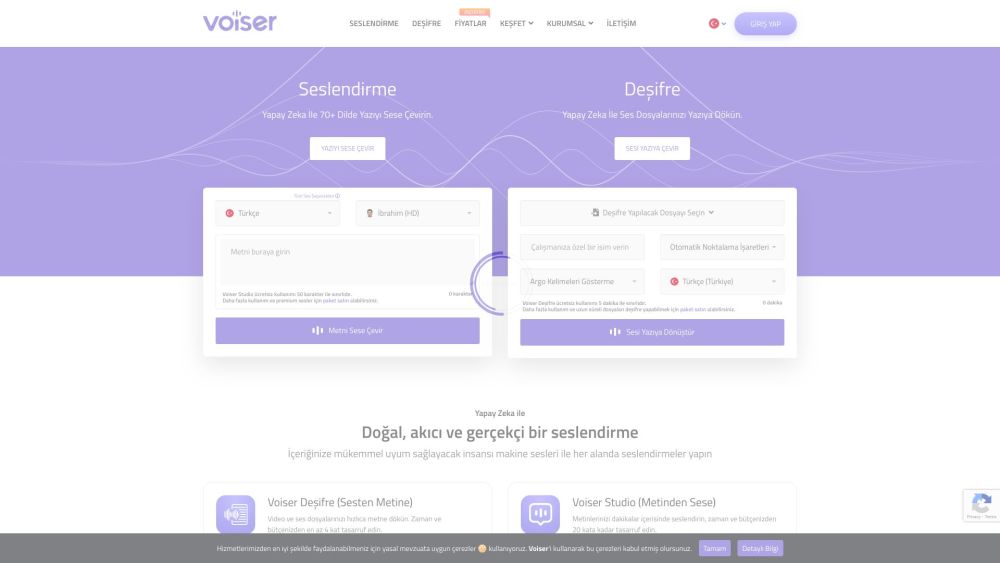
Voiser is an AI program that converts text to speech and speech to text with human-like voices.
AI virtual maths tutor for children aged 5 to 13
Dump your thoughts. Perfect memory.
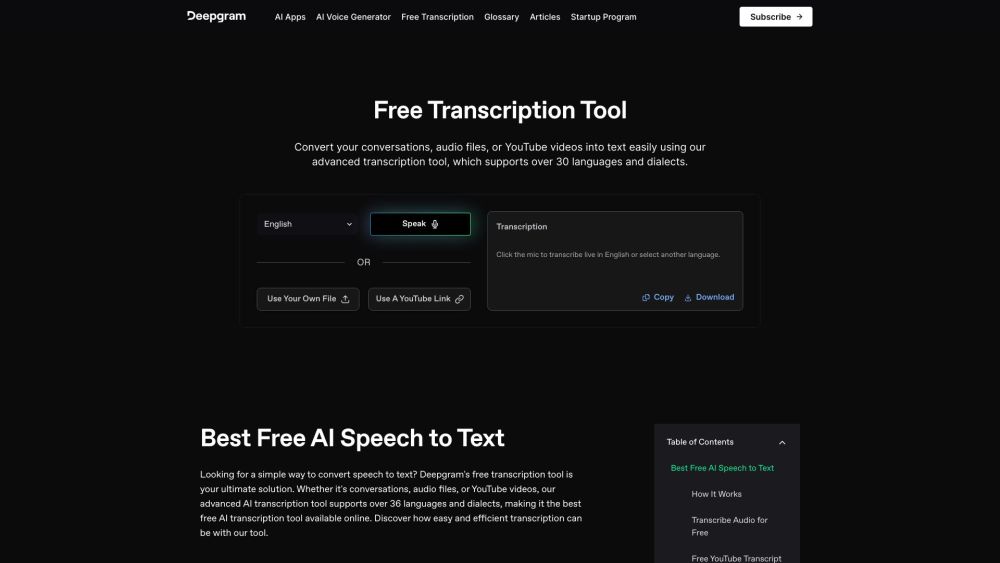
Free AI transcription tool for converting audio to text.
Real-time speech-to-text and text-to-speech APIs powered by Deepgram's voice AI models
Voicemaker® converts text to human-like voices, offering various voice profiles and customization options.
多语言效率工具,支持高精度录音转文本、智能会议总结和自动思维导图生成,覆盖110+语言。办公场景中应用广泛,适合会议和文档处理。
一个基本的端到端语音识别工具包和开源 SOTA 预训练模型,支持语音识别、语音活动检测、文本后处理等。 FunASR离线文件转写软件包,提供了一款功能强大的语音离线文件转写服务。拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。服务
Kimi-Audio,这是一个开源音频基础模型,在音频理解、生成和对话方面表现出色。此存储库包含 Kimi-Audio 的官方实现、模型和评估工具包。 通用功能:处理语音识别(ASR)、音频问答(AQA)、音频字幕(AAC)、语音情感识别(SER)、声音事件/场景分类(SEC/ASC)和端到端语音对话等多种任务。 最先进的性能:在众多音频基准测试中取得 SOTA 结果(参见评估和技术报告)。
它是开源了从FreeSWITCH模块,语音合成,语音识别,到java版的电话工具条等,完整的源码都提供了。 项目采用Apache2.0用户协议。 主要功能如下: 1. 支持对接大模型 2. 支持实时流式语音合成 3. 支持acd话务排队 4. 支持AI通话无缝转接人工坐席 5. 支持电话工具条 6. 支持IMS视频通话/语音通话转视频 7. 支
"暴躁教授读论文"是一个学术论文阅读伴侣应用程序,旨在通过富有个性的AI助手提高论文阅读效率。它集成了PDF处理、AI翻译、RAG检索、AI问答和语音交互等多种功能,为学术研究者提供一站式的论文阅读解决方案。 主要特性 论文自动处理:导入PDF后自动提取、翻译和结构化论文内容 双语显示:支持中英文对照阅读论文 AI智能问答:与论文内容结合,提供专业的解释和分析 个性化AI教授:AI以"暴
极简部署AI视频翻译配音工具 KrillinAI-一款AI视频翻译配音工具 提供了从视频下载,音频提取,音频转录,文本切割,翻译,对齐,到最终合成适配抖音,哔哩哔哩,小红书,视频号,快手等主流平台格式的一站式解决方案。 基于AI大模型的视频翻译和配音工具,专业级翻译,一键部署全流程,可以生成适配抖音,小红书,哔哩哔哩,视频号,TikTok,Youtube Shorts等形态的
Offerin AI 是专为求职者设计的智能面试辅助工具。基于先进的语音识别技术,实时捕捉面试问题,迅速提供精准答案。基于GPT-4技术,Offerin AI 能秒级响应,同时支持联网搜索确保信息的准确性。具备编程模式,帮助解决算法和编程问题,双设备互连功能,无需担心平台监控。Offerin AI 支持多种操作系统和会议软件,适用于程序员、产品经理等多种职位的面试和笔试。 🚀产品亮点
BILIVE 是基于 AI 技术的开源工具,专为 B 站直播录制与处理设计。工具支持自动录制直播、渲染弹幕和字幕,支持语音识别、自动切片精彩片段,生成有趣的标题和风格化的视频封面。BILIVE 能自动将处理后的视频投稿至 B 站,综合多种模态模型,兼容超低配置机器,无需 GPU 即可运行,适合个人用户和小型服务器使用。 1. Introduction Have you notice
VoiceCanvas 是开源的多语言语音合成平台。基于 AI 技术提供高质量的文字转语音服务,支持超过 50 种语言,集成 OpenAI TTS、AWS Polly 和 MiniMax 等多种语音服务。VoiceCanvas 提供个人声音克隆功能,用户上传几秒音频样本能创建个性化声音。VoiceCanvas适合内容创作者、教育工作者和企业用户,显著提升语音内容制作效率。 VoiceCanvas
OmniAudio 是阿里巴巴通义实验室语音团队推出的从360°视频生成空间音频(FOA)的技术。为虚拟现实和沉浸式娱乐提供更真实的音频体验。通过构建大规模数据集Sphere360,包含超过10.3万个视频片段,涵盖288种音频事件,总时长288小时,为模型训练提供了丰富资源。OmniAudio 的训练分为两个阶段:自监督的coarse-to-fine流匹配预训练,基于大规模非空间音频资源进行自监
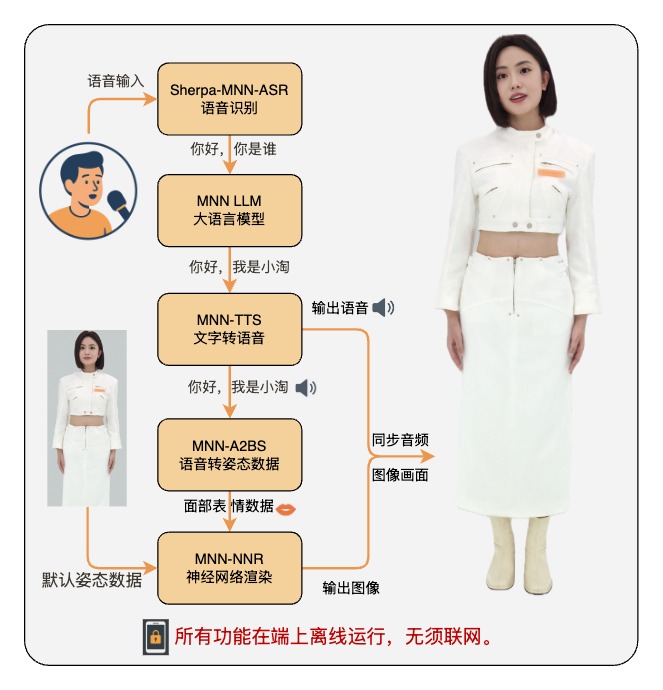
MNN轻量级高性能推理引擎 通用性 - 支持TensorFlow、Caffe、ONNX等主流模型格式,支持CNN、RNN、GAN等常用网络。 高性能 - 极致优化算子性能,全面支持CPU、GPU、NPU,充分发挥设备算力。 易用性 - 转换、可视化、调试工具齐全,能方便地部署到移动设备和各种嵌入式设备中。 什么是 TaoAvatar?它是阿里最新研究
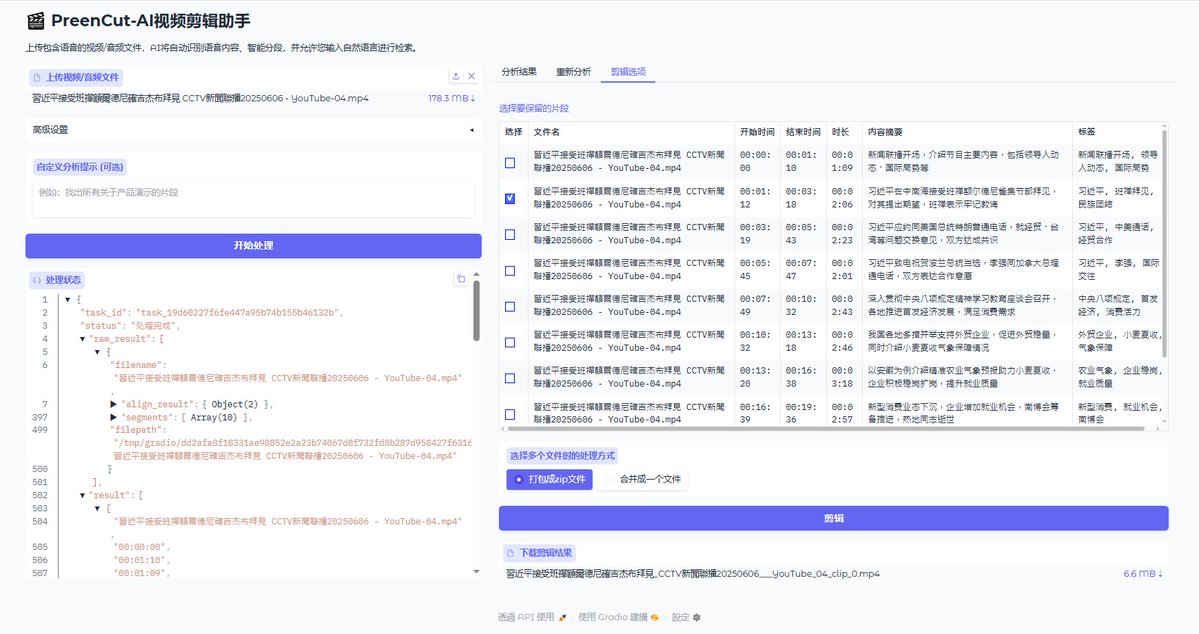
通过 AI 自动分析视频内容并生成文字转录,其中语义化搜索功能颇有用,支持自然语言描述快速找到想要的视频片段。 GitHub:http://github.com/roothch/PreenCut… 主要功能: - 基于 WhisperX 的自动语音识别,生成准确的视频转录 - AI 智能分析,自动分段并总结每段内容要点 - 自然语言查询,用描述性文字快速找到目标片段 - 智能剪辑导出,可选择单个
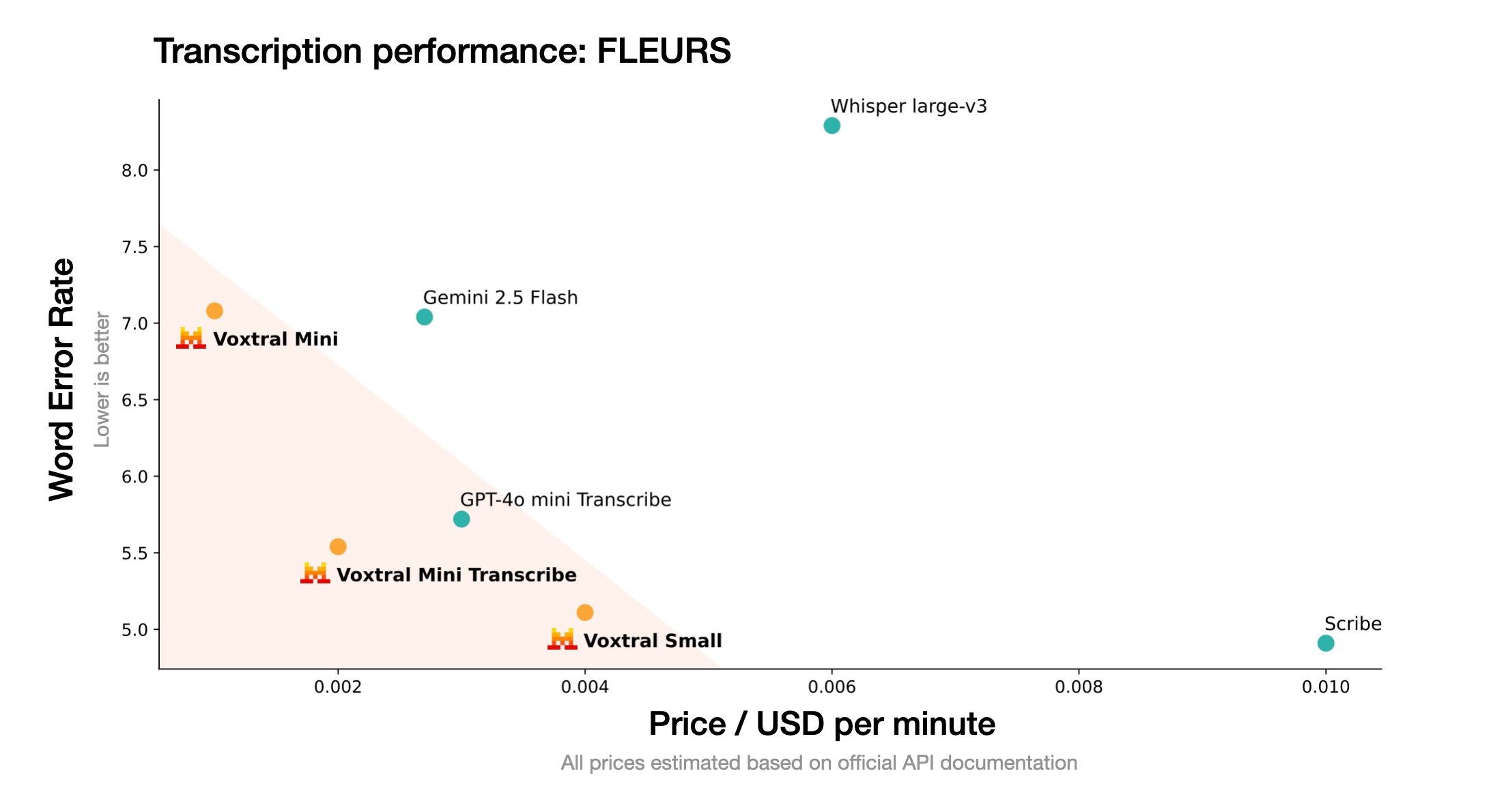
Voxtral 是 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。Voxtral提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音
研究模式可将 Le Chat 转变为一个协调的研究助手,能够规划、明确需求、搜索和综合信息。提出一个有深度的问题,它会将其分解,收集可靠的资料,并构建一个结构清晰、有参考文献支持且易于理解的报告。 它由工具增强型深度研究 Agent 驱动,但设计得简单、透明且真正有帮助,仿佛与一个组织良好的研究伙伴合作。 Mistral AI 也在官网展示了一些用例。深度研究模式能够追踪市场趋势、撰写商业策略
阿里巴巴推出FunAudio-ASR语音识别大模型,专为解决企业落地难题。模型通过创新的Context增强模块,有效优化了“幻觉”“串语种”等关键问题。在高噪声等复杂场景下,其识别准确率显著提升,幻觉率从78.5%降至10.7%。目前,FunAudio-ASR 已在钉钉的“AI听记”、视频会议、DingTalk A1硬件等多个场景中应用,验证了其在真实企业环境中的稳定性和高精度识别能力,特别是在垂
只显示前20页数据,更多请搜索
Showing 241 to 261 of 261 results