关键词 "24 languages" 的搜索结果, 共 19 条, 只显示前 480 条
普林斯顿与复旦推出HistBench和HistAgent,首个人文AI评测基准 普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。 历史是关于时间中的人的
Seaweed APT2是字节跳动推出的创新的AI视频生成模型,通过自回归对抗后训练(AAPT)技术,将双向扩散模型转化为单向自回归生成器,实现高效、高质量的视频生成。模型能在单次网络前向评估(1NFE)中生成包含多帧视频的潜空间帧,显著降低了计算复杂性,通过输入回收机制和键值缓存(KV Cache)技术,支持长时间视频生成,解决了传统模型在长视频生成中常见的动作漂移和物体变形问题。能在单块GPU
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
RAG-Anything是香港大学数据智能实验室推出的开源多模态RAG系统。系统支持处理包含文本、图像、表格和公式的复杂文档,提供从文档摄取到智能查询的端到端解决方案。系统基于多模态知识图谱、灵活的解析架构和混合检索机制,显著提升复杂文档处理能力,支持多种文档格式,如PDF、Office文档、图像和文本文件等。RAG-Anything核心优势包括端到端多模态流水线、多格式文档支持、多模态内容分析引
文本到图像的扩散模型的最新进展已取得显著成功,但它们往往难以完全捕捉用户的意图。现有的使用文本输入结合边界框或区域蒙版的方法无法提供精确的空间引导,常常导致对象方向错位或意外。为了解决这些限制,我们提出了涂鸦引导扩散(ScribbleDiff),这是一种无需训练的方法,它利用用户提供的简单涂鸦作为视觉提示来引导图像生成。然而,将涂鸦纳入扩散模型存在挑战,因为涂鸦具有稀疏和单薄的特性,很难确保准确的
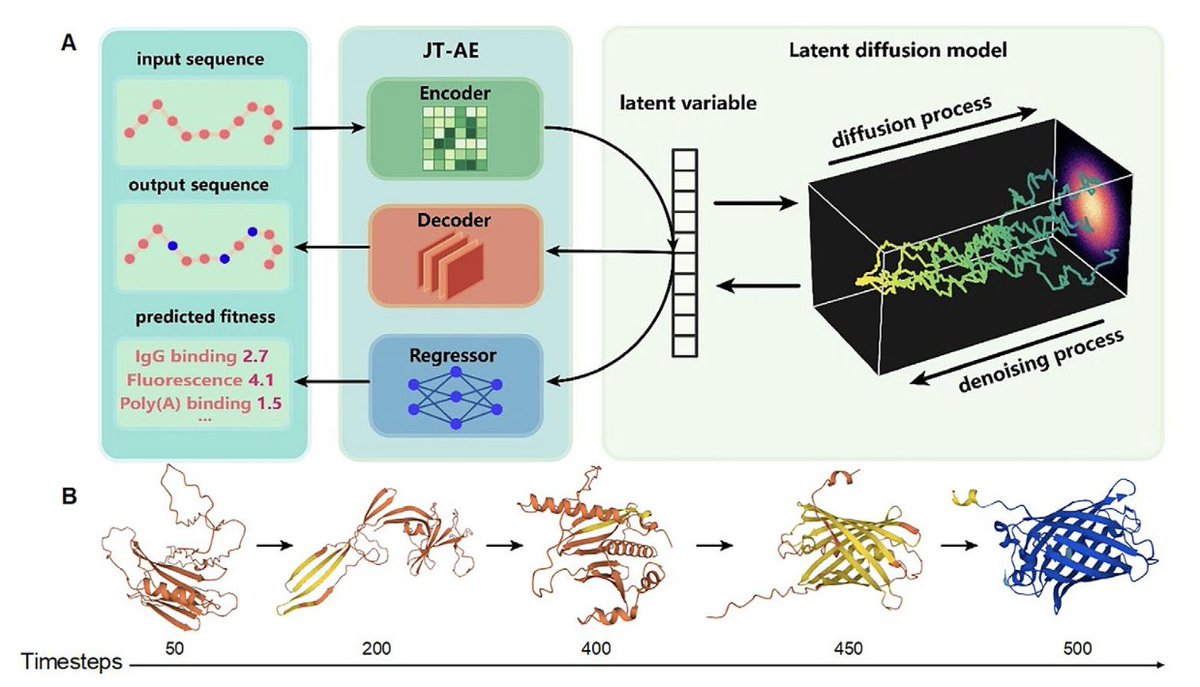
1.PRO-LDM 引入了一种模块化潜在扩散模型,用于全长蛋白质序列设计,该模型兼具无条件生成和功能优化,将准确性与计算效率完美结合。 2. 一项重大创新在于在潜在空间中应用扩散,显著降低采样成本,同时保持生成序列的保真度和多样性。 3. PRO-LDM 通过将条件潜在扩散与监督适应度预测相结合,实现了具有目标特性(例如荧光、溶解度、热/化学稳定性)的蛋白质序列的可控设计。 4. 通过无分类
FateTell 是融合东方命理与 AI 技术的命运探索工具。FateTell 基于 DeepSeek、Gemini、GPT 等先进模型构建,邀请专业命理师共同搭建完整的命理测评体系。通过 AI 对话与个性化解读报告,FateTell 提供每日运势、AI 占卜、年运分析、命理学习、命盘分析等多维内容。FateTell 帮助用户在自我认知与现实决策之间找到连接,用科技赋能传统文化,为现代人提供一种独
Skala 是专为全球创业者设计的 AI 法律平台,把公司注册、融资、合同、商标等高频法律需求整合在一处。用户可在几分钟内完成美国、阿联酋等多地公司设立,用 AI 助手或真人律师快速生成 NDA、期权计划等文件。平台提供股权/代币融资模板、电子签名、进度追踪和 83(b) 提醒,让初创企业以 SaaS 价格享受跨国律所级服务。 Skala的主要功能 全球公司注册:最快 15 分钟在美国
Todai 是AI个人情绪健康助手,通过智能日记、语音/文本记录和幸福生活指数(HLI)动态追踪,帮助用户了解自身情绪模式,发现变化规律,提供科学支持的实用工具(如正念练习、目标设定等)实现情绪平衡和幸福感提升。由心理学家和认知行为专家参与开发,确保方法专业有效,支持用户随时随地获得个性化的全天候支持,无需等待或担心评判。 Todai的主要功能 AI 情绪日记:随时用文字或语音记录当下
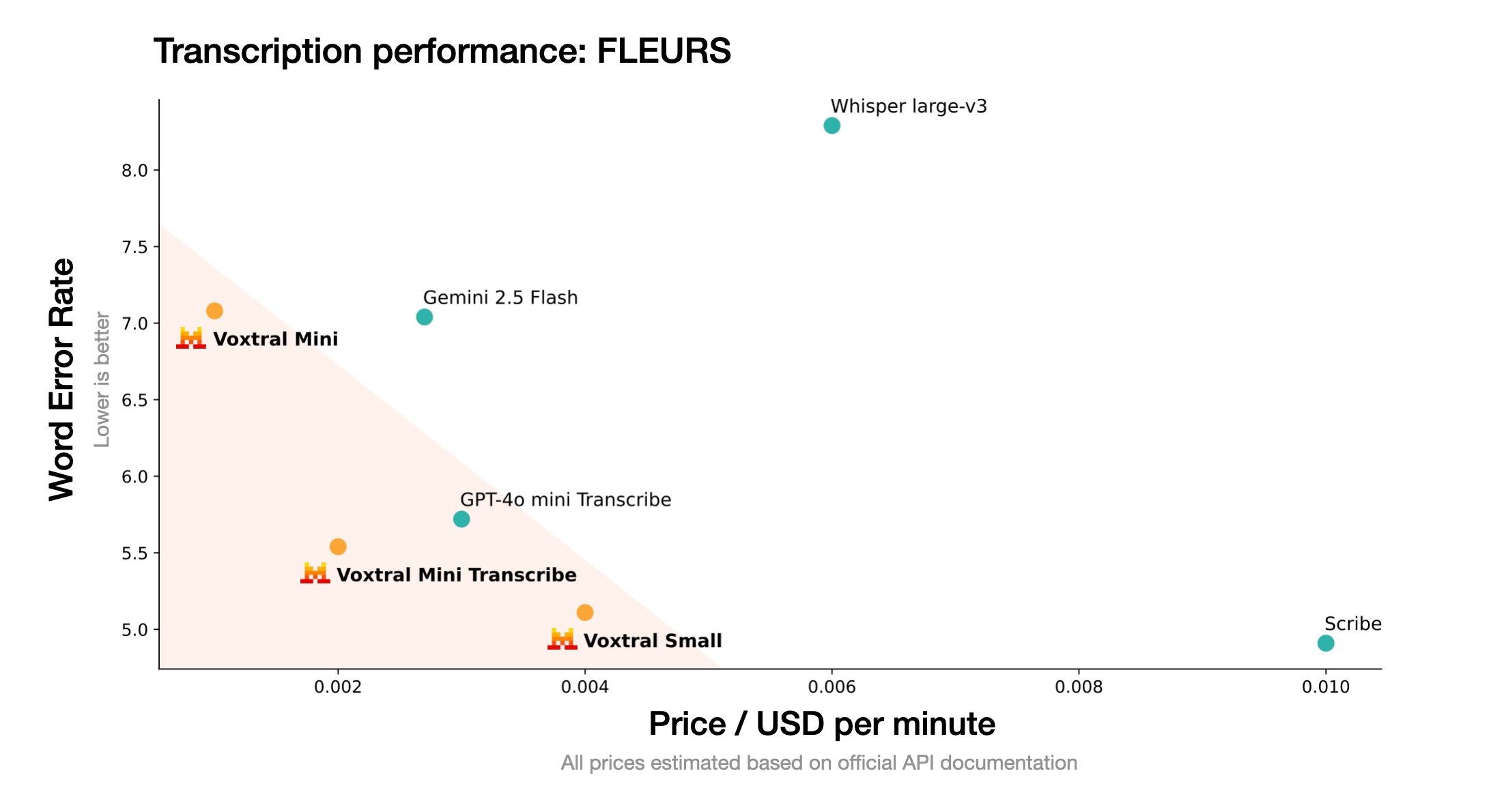
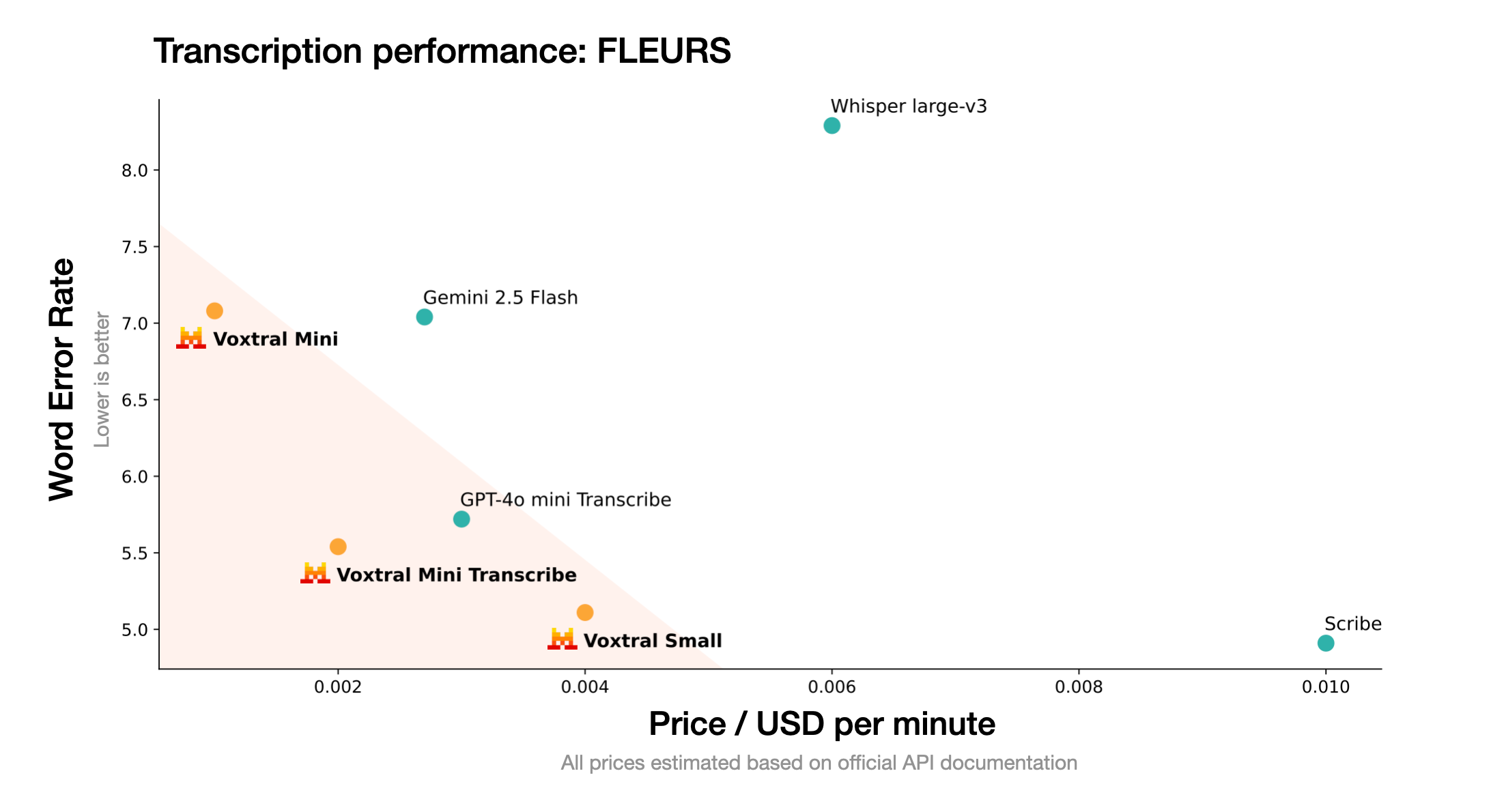
Voxtral 是 Mistral AI 推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。Voxtral提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音
林间聊愈室是Mindera Technology推出的提供24小时AI陪伴的心理健康应用,为人们提供一个安全、私密的环境,在这里可以随时随地分享他们的感受和经历。用户可以在这里与可爱的动物角色——花花狸、森森鹿和咕咕熊——进行互动,分享情绪和日常琐事。
Experience revolutionary language learning through real-time conversation practice, instant grammar correction, pronunciation training, and personalized vocabulary building in 30+ languages.
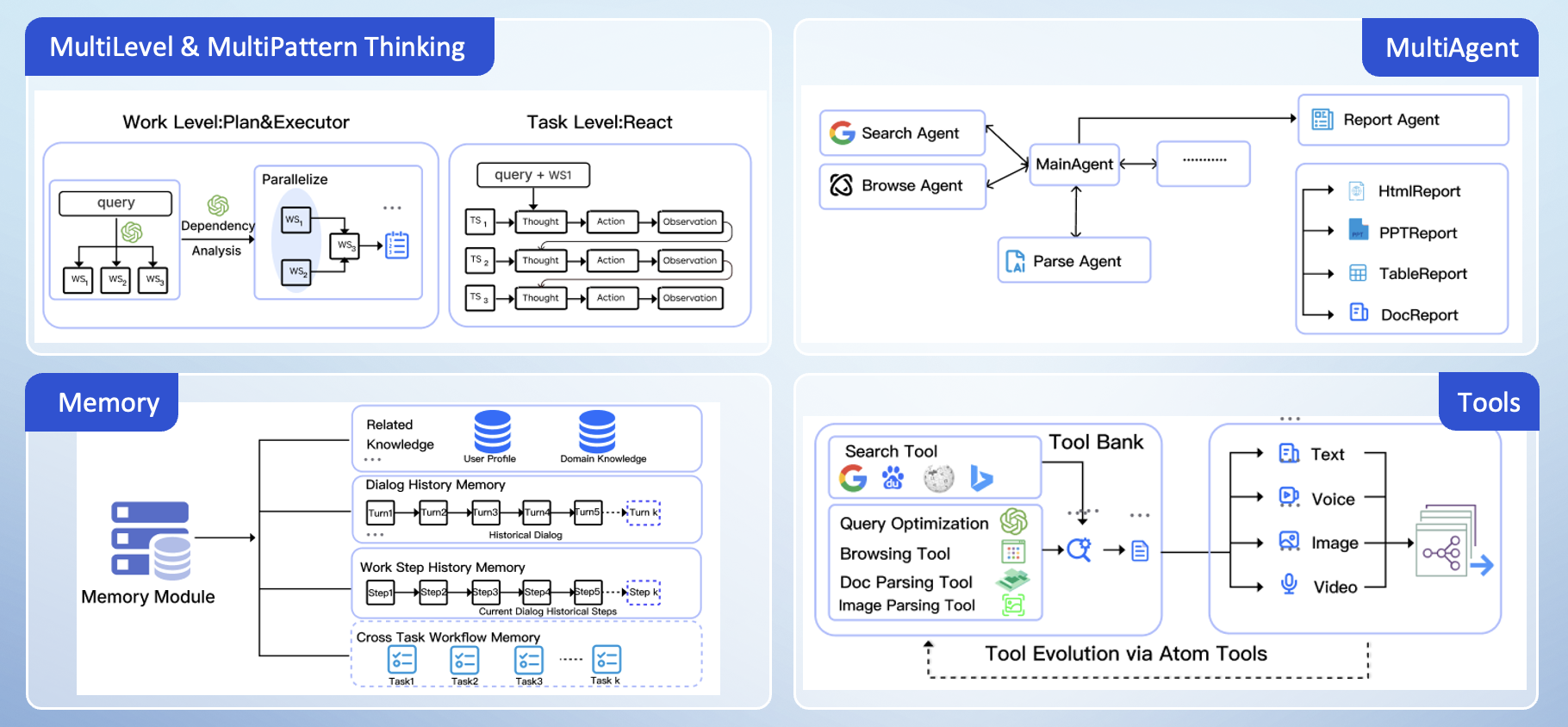
业界首个开源高完成度轻量化通用多智能体产品(JoyAgent-JDGenie) 解决快速构建多智能体产品的最后一公里问题 简介 当前相关开源agent主要是SDK或者框架,用户还需基于此做进一步的开发,无法直接做到开箱即用。我们开源的JoyAgent-JDGenie是端到端的多Agent产品,对于输入的query或者任务,可以直接回答或者解决。例如用户query"给我做一个最
MirageLSD 是 Decart AI 团队推出的全球首个 Live-Stream Diffusion(实时流扩散)AI 视频模型,能实现无限时长的实时视频生成,延迟低至 40 毫秒以内,支持 24 帧/秒的流畅输出。通过 Diffusion Forcing 技术和历史增强训练,解决了传统自回归模型在长时间生成中的误差累积问题,实现了视频的无限生成。基于Hopper 优化的 Mega Kern
来福是北京耳朵时间科技推出的AI私人电台应用,应用主打AI语音驱动的“陪伴型内容”,结合语音合成与场景感知实现个性化播报,为用户提供沉浸式的音频体验。用户用语音交互点播节目、提问或聊天,享受7×24小时的声音陪伴。应用融合播客、智能语音助手与定制内容推荐的多重属性,用AI生成内容替代传统主播,重新定义私人电台的使用体验。 来福官网: https://laifu.fm/ 也可以下载APP使用
Mistral AI,最新发布了首个开源语音模型:Voxtral语音理解模型系列! 该模型包含24B和3B两个参数规模的版本,均基于Apache 2.0许可证开源,同时提供API服务接口。 Voxtral模型支持32k token的上下文窗口,能够处理长达30分钟的音频转录任务或40分钟的语义理解任务,在各项基准测试指标上全面超越目前主流的开源语音转录模型Whisper large-v3。
TokenPony 是为个人开发者和小型团队设计的高效 AI 平台,如同一位智能指挥家,将多种主流大模型(如 DeepSeek、Kimi、Qwen、GLM 等)集成在一个统一接口下,极大地简化了模型切换的繁琐流程。用户无需跨平台操作,可一键接入并自由调用不同模型,享受超长 1024K 上下文支持,轻松处理长文档和复杂任务。TokenPony 提供零配置、免部署的一键调用 API,无需自建 GPU
LoomlyAI 是专注于视觉内容解决方案的 AI 平台,提供 AI 模特和智能换装功能。基于 AI 模型取代传统模特拍摄,快速生成高质量的商业图片和视频,解决模特拍摄成本高、版权复杂和流程繁琐的问题。平台产品亮点包括无 AI 感的多样化模特库、10 秒快速生成的智能换装功能及一键生成视频的功能。LoomlyAI 适用电商、社交媒体和内容创作,帮助用户高效制作视觉内容,提升商业价值。LoomlyA
AIVoiceGen is a user-friendly AI voice generation platform focused on text-to-speech. It offers free access with no registration required, featuring diverse voices across languages, accents, and tones
只显示前20页数据,更多请搜索
Showing 433 to 451 of 451 results