关键词 "Dance coaching" 的搜索结果, 共 24 条, 只显示前 480 条
AI-Powered Personal Trainer for personalized health journey
Wonsulting helps non-traditional job seekers find dream jobs with coaching and resources.
AI-guided stock market insights.
BIGVU is a versatile tool for creating professional videos with teleprompter, captioning, and video editing features.
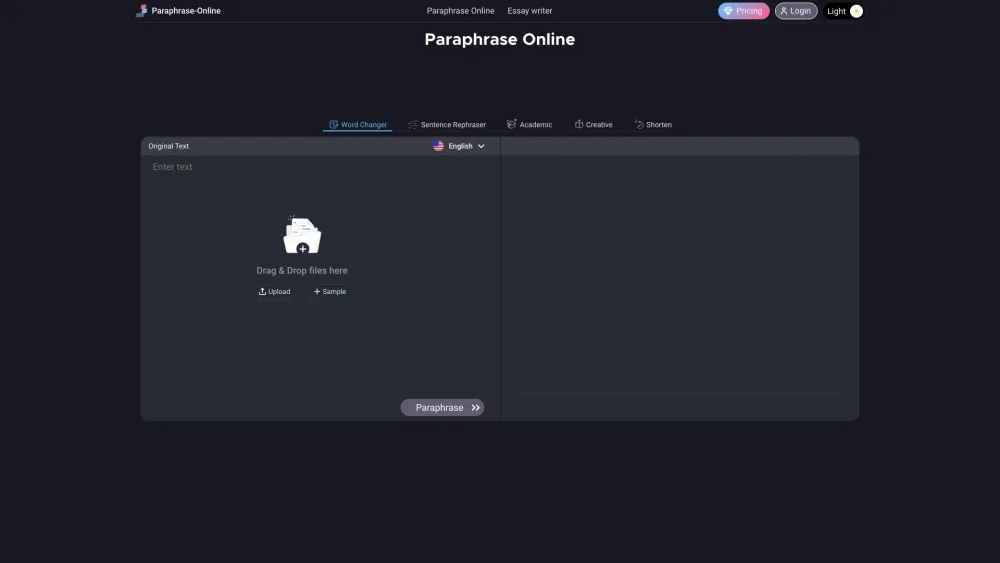
Best online paraphrasing tool for students and writers.
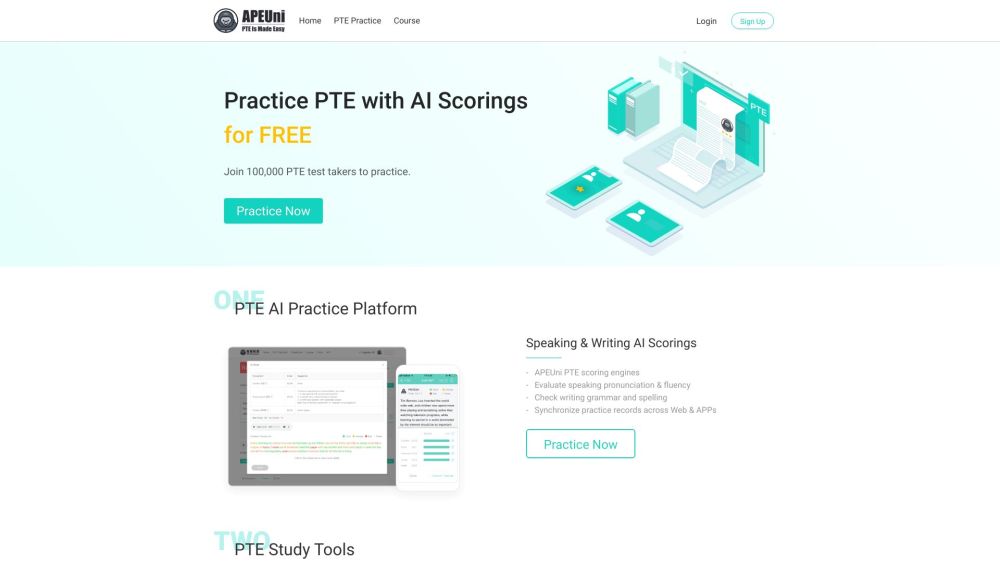
Pearson Test of English (PTE) is a computer-based academic exam with online mock tests available. Join APEUni to practice PTE for FREE and use AI scorings to evaluate your performance.
Automated coaching platform for nutrition and fitness resources.
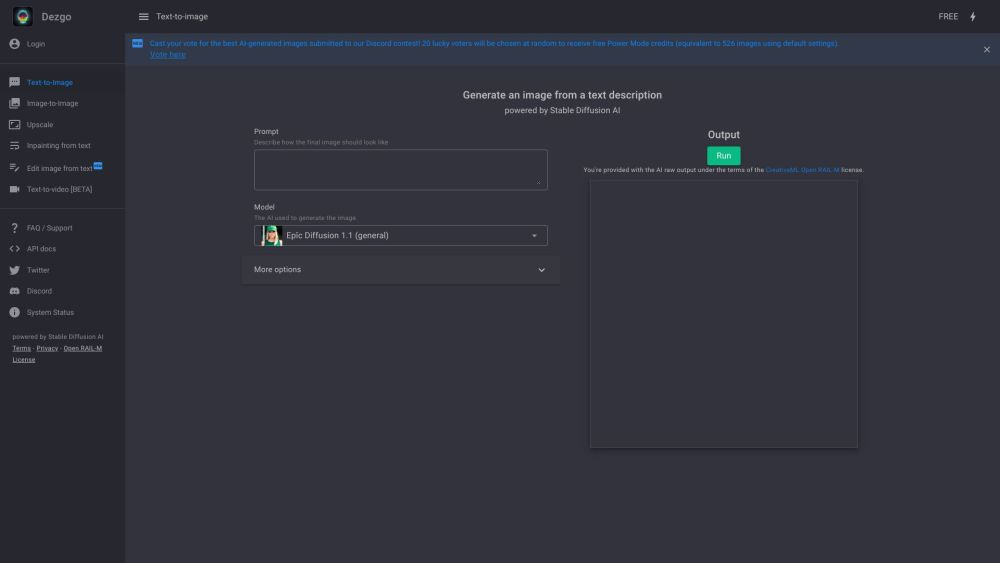
Dezgo is an AI image generator that produces high-quality images from text descriptions.
Build lasting habits with AI guidance
这是一个使用 Python 语言从 0 到 1 搭建 MCP server 的代码学习教程
MCP server that provides tools and resources for integrating Hugeicons into various platforms. It implements a Model Context Protocol (MCP) server that helps AI assistants provide accurate guidance fo
An interactive web tutorial for learning how to build MCP (Model Context Protocol) servers. This educational website provides step-by-step guidance for implementing and understanding MCP servers.
Sensei MCP is a Model Context Protocol (MCP) server that provides expert guidance for Dojo and Cairo development on Starknet.
ContextGem:轻松从文档中提取 LLM ContextGem 是一个免费的开源 LLM 框架,它可以让您以最少的代码更轻松地从文档中提取结构化数据和见解。 💎 为什么选择 Contex
字节开源DreamO,统一图像定制框架,把图像换装、换脸、换造型、换风格以及组合操作装在了一起 支持ID、IP、Try-On等组合,支持16GB/24GB显卡运行,用于虚拟试穿、商品广告、营销广告什么的比较实用 四个能力: IP,处理角色形象,支持人物、物体、动物等输入 ID,人脸身份处理 Try-On,虚拟试穿,可以同时换多件衣服 Style,风格迁移,目前还不能和其他任务组合 DreamO正
昆仑万维正式开源(17B+)Matrix-Game大模型,即Matrix-Zero世界模型中的可交互视频生成大模型。Matrix-Game是Matrix系列在交互式世界生成方向的正式落地,也是工业界首个开源的10B+空间智能大模型,它是一个面向游戏世界建模的交互式世界基础模型,专为开放式环境中的高质量生成与精确控制而设计。 空间智能作为AI时代的重要前沿技术,正在重塑我们与虚拟世界的
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
Seedance 1.0 lite是火山引擎推出的豆包视频生成模型的小参数量版本,支持文生视频和图生视频两种生成方式,支持生成5秒或10秒、480p或720p分辨率的视频。具备影视级视频生成质量,能精细控制人物外貌、衣着、表情动作等细节,支持360度环绕、航拍、变焦等多种运镜技术,生成的视频画质细腻、美感十足。模型广泛用在电商广告、娱乐特效、影视创作、动态壁纸等领域,能有效降低制作成本和周期。
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引入对比监督信号,进一步优化模型训练。SuperEdit不需要额外的视觉语言模型(VLM)或预训练任务,仅依赖高质量的监督信号,在多个基准测试中实现显著的性能提升。 Super
MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越性能。模型用统一的扩散架构,具备模态不可知的设计,消除对特定模态组件的需求,引入混合长链推理(CoT)微调策略,统一跨模态的CoT格式,推出UniGRPO,针对扩散基础模型的统
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数,其中70亿为活跃参数。采用混合变换器专家架构(MoT),通过两个独立编码器分别捕捉图像的像素级和语义级特征。BAGEL遵循“下一个标记组预测”范式进行训练,使用海量多模态标记数据进行预训练,包括语言、图像、视频和网络数据。在性能方面,BAGEL在多模态理解基准测试中超越了Qwen2.5-VL和InternVL-2.5等顶级开源视觉语言模型
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
全新的生成模型MeanFlow,最大亮点在于它彻底跳脱了传统训练范式——无须预训练、蒸馏或课程学习,仅通过一次函数评估(1-NFE)即可完成生成。 MeanFlow在ImageNet 256×256上创下3.43 FID分数,实现从零开始训练下的SOTA性能。 图1(上):在ImageNet 256×256上从零开始的一步生成结果 在ImageNet 256×25
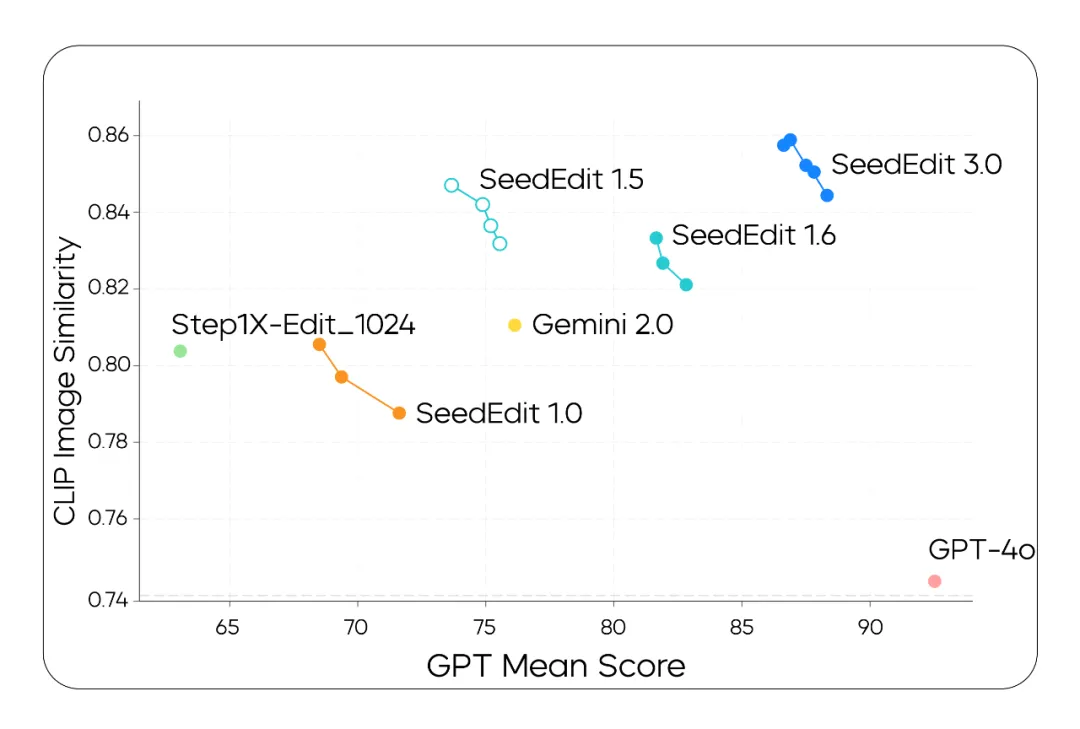
字节跳动 Seed 团队今天正式发布图像编辑模型 SeedEdit 3.0。 该模型可处理并生成 4K 图像,在精细且自然地处理编辑区域的同时,还能高保真地维持其他信息。尤其针对图像编辑“哪里改与哪里不改”的取舍,该模型表现出更佳的理解力和权衡力,可用率相应提高。 依靠 AI 完成指令式图像编辑的需求,广泛存在于视觉内容创意工作中。但此前,图像编辑模型在主体&背景保持、指令遵循等方面能
只显示前20页数据,更多请搜索
Showing 313 to 336 of 347 results