关键词 "GitHub gists" 的搜索结果, 共 24 条, 只显示前 480 条
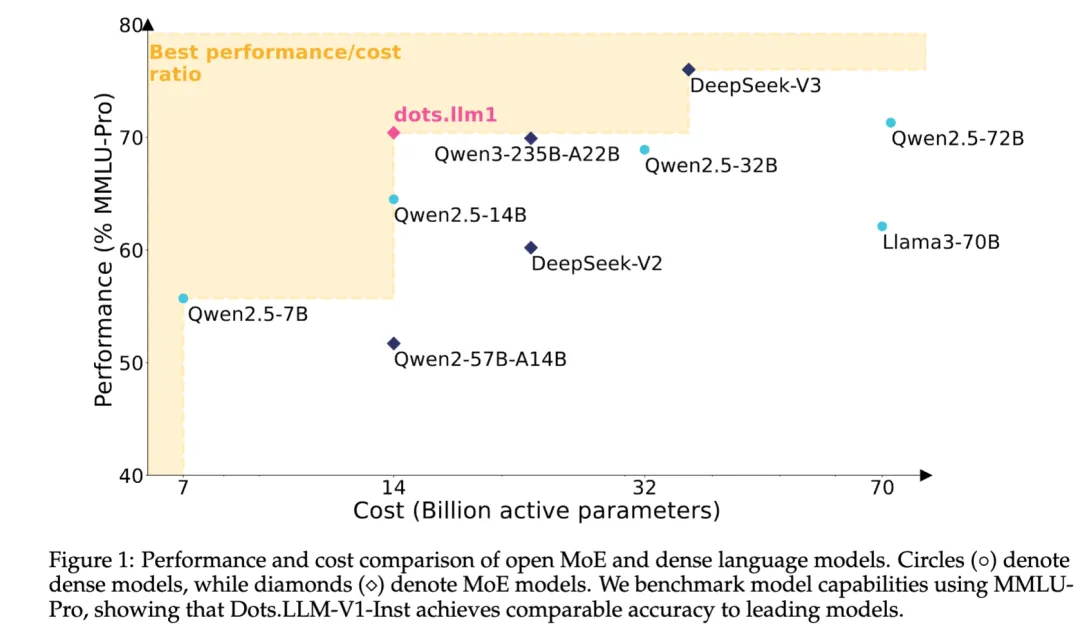
小红书hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源文本大模型 dots.llm1。 dots.llm1是一个中等规模的Mixture of Experts (MoE)文本大模型,在较小激活量下取得了不错的效果。该模型充分融合了团队在数据处理和模型训练效率方面的技术积累,并借鉴了社区关于 MoE 的最新开源成果。hi lab团队开源了所有模型和必要的训练
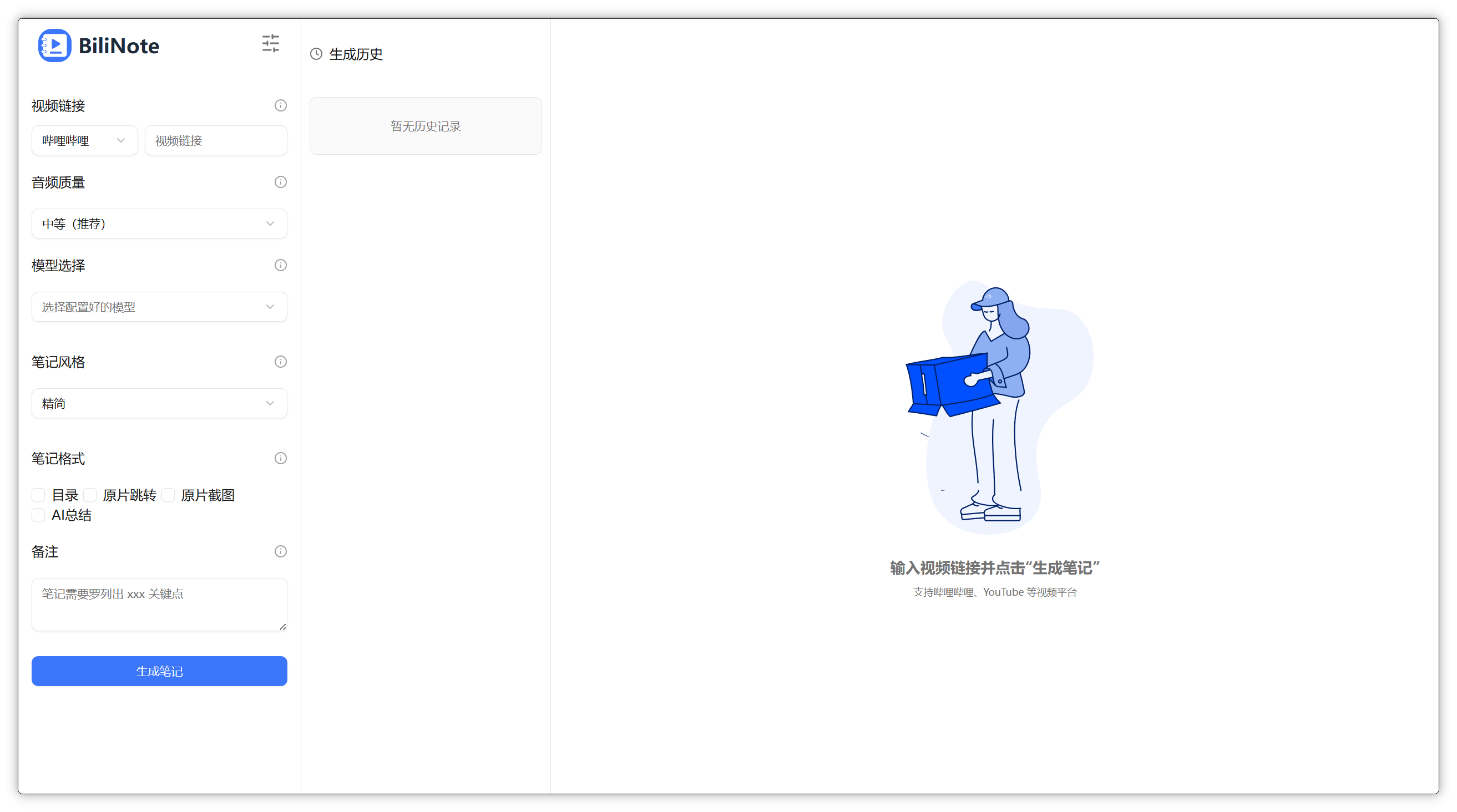
BiliNote 是一个开源的 AI 视频笔记助手,支持通过哔哩哔哩、YouTube、抖音等视频链接,自动提取内容并生成结构清晰、重点明确的 Markdown 格式笔记。支持插入截图、原片跳转等功能。 Windows 打包版 本项目提供了 Windows 系统的 exe 文件,可在release进行下载。注意一定要在没有中文路径的环境下运行。 🔧 功能特性 支持多平台:
Playmate是广州趣丸科技团队推出的人脸动画生成框架。框架基于3D隐式空间引导扩散模型,用双阶段训练框架,根据音频和指令精准控制人物的表情和头部姿态,生成高质量的动态肖像视频。Playmate基于运动解耦模块和情感控制模块,实现对生成视频的精细控制,显著提升视频质量和情感表达的灵活性。Playmate在音频驱动肖像动画领域取得重大进展,提供对情感和姿态的精细控制,能生成多种风格的动态肖像,具有
Genspark AI 浏览器(Genspark AI Browser) 是 Genspark 公司推出的创新性人工智能浏览器。内置智能助手,能帮助用户查找更优交易、比较产品、分析评论,在各类网站上辅助决策。 AI 自动浏览信息源、收集资料、访问高级数据库,完成复杂网页任务,支持MCP服务,连接 Discord、GitHub、Notion、Slack 等 700 多种工具,实现工作流程自动化。自动
普林斯顿与复旦推出HistBench和HistAgent,首个人文AI评测基准 普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。 历史是关于时间中的人的
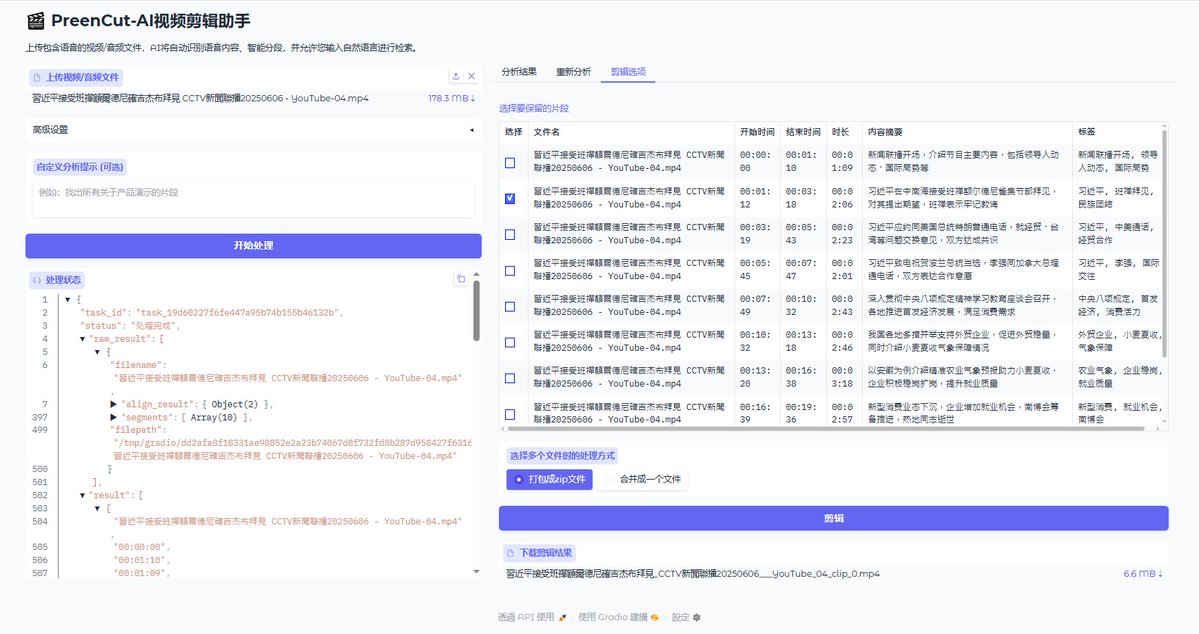
通过 AI 自动分析视频内容并生成文字转录,其中语义化搜索功能颇有用,支持自然语言描述快速找到想要的视频片段。 GitHub:http://github.com/roothch/PreenCut… 主要功能: - 基于 WhisperX 的自动语音识别,生成准确的视频转录 - AI 智能分析,自动分段并总结每段内容要点 - 自然语言查询,用描述性文字快速找到目标片段 - 智能剪辑导出,可选择单个
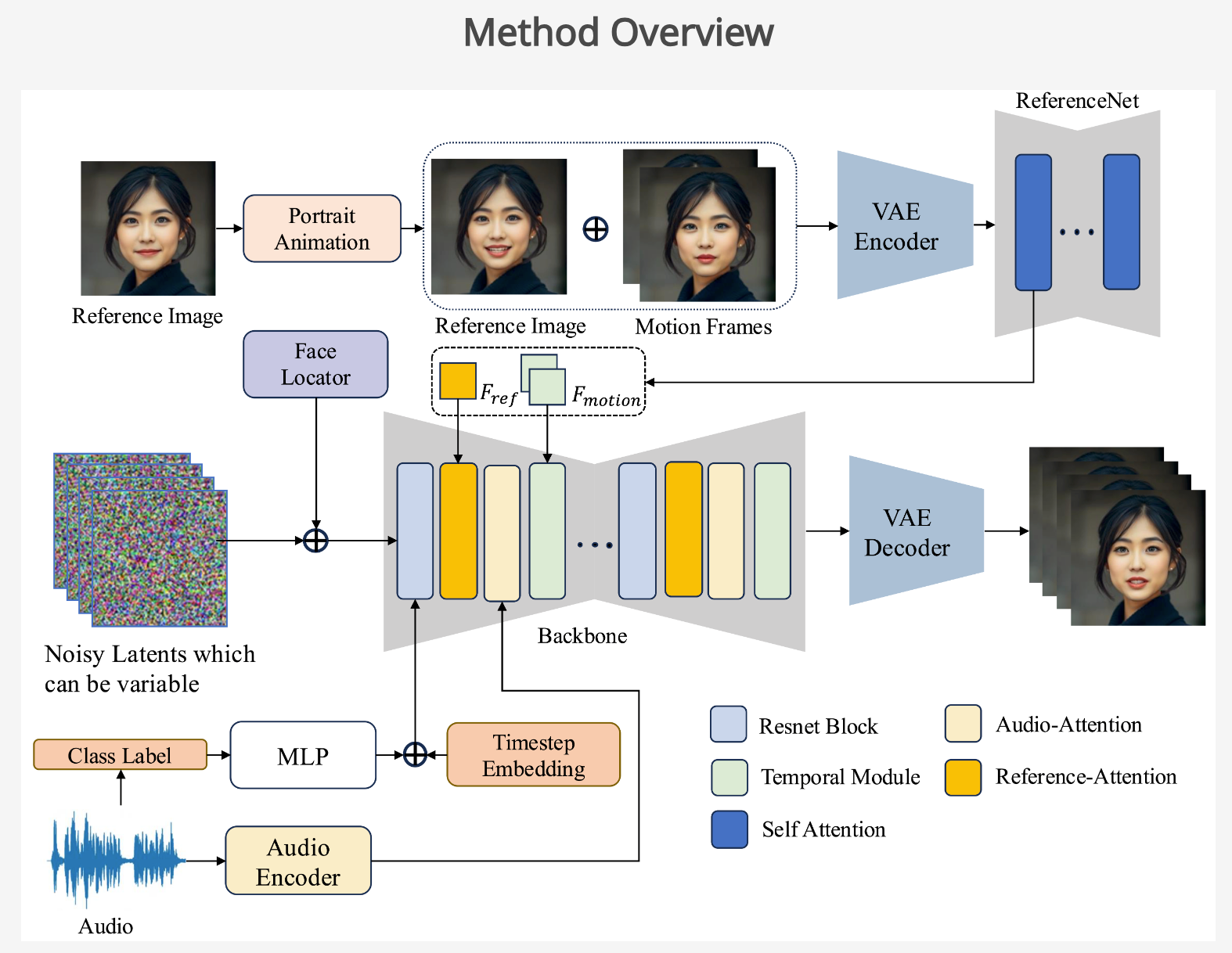
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
专注于字幕相关功能的视频播放器,例如双字幕、AI 生成字幕、实时翻译、单词查找等! LLPlayer 具有许多普通视频播放器所不具备的语言学习功能。 双字幕:可同时显示两个字幕。支持文本字幕和位图字幕。 AI 生成的字幕(ASR):由OpenAI Whisper提供支持,从任何视频和音频实时自动生成字幕。支持whisper.cpp和fastest-whisper两个引擎。 实时翻译:支
MAGREF(Masked Guidance for Any‑Reference Video Generation)是字节跳动推出的多主体视频生成框架。MAGREF仅需一张参考图像和文本提示,能生成高质量、主体一致的视频,支持单人、多人及人物与物体、背景的复杂交互场景。基于区域感知动态掩码和像素级通道拼接机制,MAGREF能精准复刻身份特征,保持视频中人物、物体和背景的协调性与一致性,适用内容创作
Kimi-Dev是Moonshot AI推出的开源代码模型,专为软件工程任务设计。模型拥有 72B 参数量,编程水平比最新的DeepSeek-R1还强,和闭源模型比较也表现优异。在 SWE-bench Verified数据集上达到60.4%的性能,超越其他开源模型,成为当前开源模型中的SOTA。Kimi-Dev 基于强化学习和自我博弈机制,能高效修复代码错误、编写测试代码。模型基于MIT协议开源,
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
ThinkChain是开源框架,提升AI工具的智能交互能力。框架将工具的执行结果实时反馈到AI(如 Claude)的思考过程中,形成动态的反馈循环,让AI能调用工具,根据工具结果进行推理和决策。ThinkChain支持自动工具发现、MCP服务器扩展及增强的 CLI 界面,支持开发者用简单的Python文件扩展功能,实现从天气查询到数据库操作等多种应用。框架基于MIT许可证,鼓励开发者fork和扩展
LeVo是腾讯AI实验室推出的AI唱歌模型,具备强大的音色克隆能力,仅需3秒音频即可精准复制目标音色,包括音调、情感和韵律,无需大量训练数据。LeVo支持分轨生成,可分别生成人声和伴奏音轨,为后期编辑提供便利。技术架构基于语言模型(LM),结合LeLM和音乐编解码器,能并行生成音轨,音质表现接近行业领先水平,在歌词对齐能力上表现卓越。 LeVo的项目地址 项目官网: https://lev
EmbodiedGen 是用于具身智能(Embodied AI)应用的生成式 3D 世界引擎和工具包。能快速生成高质量、低成本且物理属性合理的 3D 资产和交互环境,帮助研究人员和开发者构建具身智能体的测试环境。EmbodiedGen 包含多个模块,如从图像或文本生成 3D 模型、纹理生成、关节物体生成、场景和布局生成等,支持从简单物体到复杂场景的创建。生成的 3D 资产可以直接用于机器人仿真和
RAG-Anything是香港大学数据智能实验室推出的开源多模态RAG系统。系统支持处理包含文本、图像、表格和公式的复杂文档,提供从文档摄取到智能查询的端到端解决方案。系统基于多模态知识图谱、灵活的解析架构和混合检索机制,显著提升复杂文档处理能力,支持多种文档格式,如PDF、Office文档、图像和文本文件等。RAG-Anything核心优势包括端到端多模态流水线、多格式文档支持、多模态内容分析引
Dive3D是北京大学和小红书公司合作推出的文本到3D生成框架。框架基于分数的匹配(Score Implicit Matching,SIM)损失替代传统的KL散度目标,有效避免模式坍塌问题,显著提升3D生成内容的多样性。Dive3D在文本对齐、人类偏好和视觉保真度方面表现出色,在GPTEval3D基准测试中取得优异的定量结果,证明了在生成高质量、多样化3D资产方面的强大能力。 Dive3D的项目
Lingshu是阿里巴巴达摩院推出的专注于医学领域的多模态大型语言模型。模型支持超过12种医学成像模态,包括X光、CT扫描、MRI等,在多模态问答、文本问答及医学报告生成等任务上展现出卓越的性能。Lingshu基于多阶段训练,逐步嵌入医学专业知识,显著提升在医学领域的推理和问题解决能力。推出7B、32B两个参数版本,其中32B版本在多个医学多模态问答任务中超越GPT-4.1等专有模型。Lingsh
Gemini CLI 是谷歌开源的 AI Agent,将 Gemini 大模型融入开发者终端。Gemini CLI提供强大 AI 功能,如代码理解、文件操作、命令执行及动态排查问题,助力开发者高效编写代码、修复错误、构建功能和迁移代码。Gemini CLI内置谷歌搜索,支持 MCP 协议,支持扩展数千功能,Gemini CLI支持用户定制提示和指令,能集成到脚本中实现自动化任务。Gemini CL
MultiAgentPPT 是多智能体演示文稿生成系统,基于 A2A(Ask-to-Answer)、MCP(Multi-agent Control Protocol)和 ADK(Agent Development Kit)架构。MultiAgentPPT 基于多Agent协作和流式并发机制,从用户输入的主题自动生成高质量的 PPT 内容。系统包括大纲生成、主题拆分、并行调研和内容汇总等步骤,具备多
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
FLUX.1 Kontext 是由 Black Forest Labs 推出的图像生成与编辑模型,支持上下文感知的图像处理。模型基于文本和图像提示进行生成与编辑,支持对象修改、风格转换、背景替换、角色一致性保持和文本编辑等多种任务。FLUX.1 Kontext Pro版本支持快速迭代图像编辑,能在多次编辑中保持图像质量和角色特征稳定。。Kontext Max版本在提示词遵循、排版生成和编辑一致性方
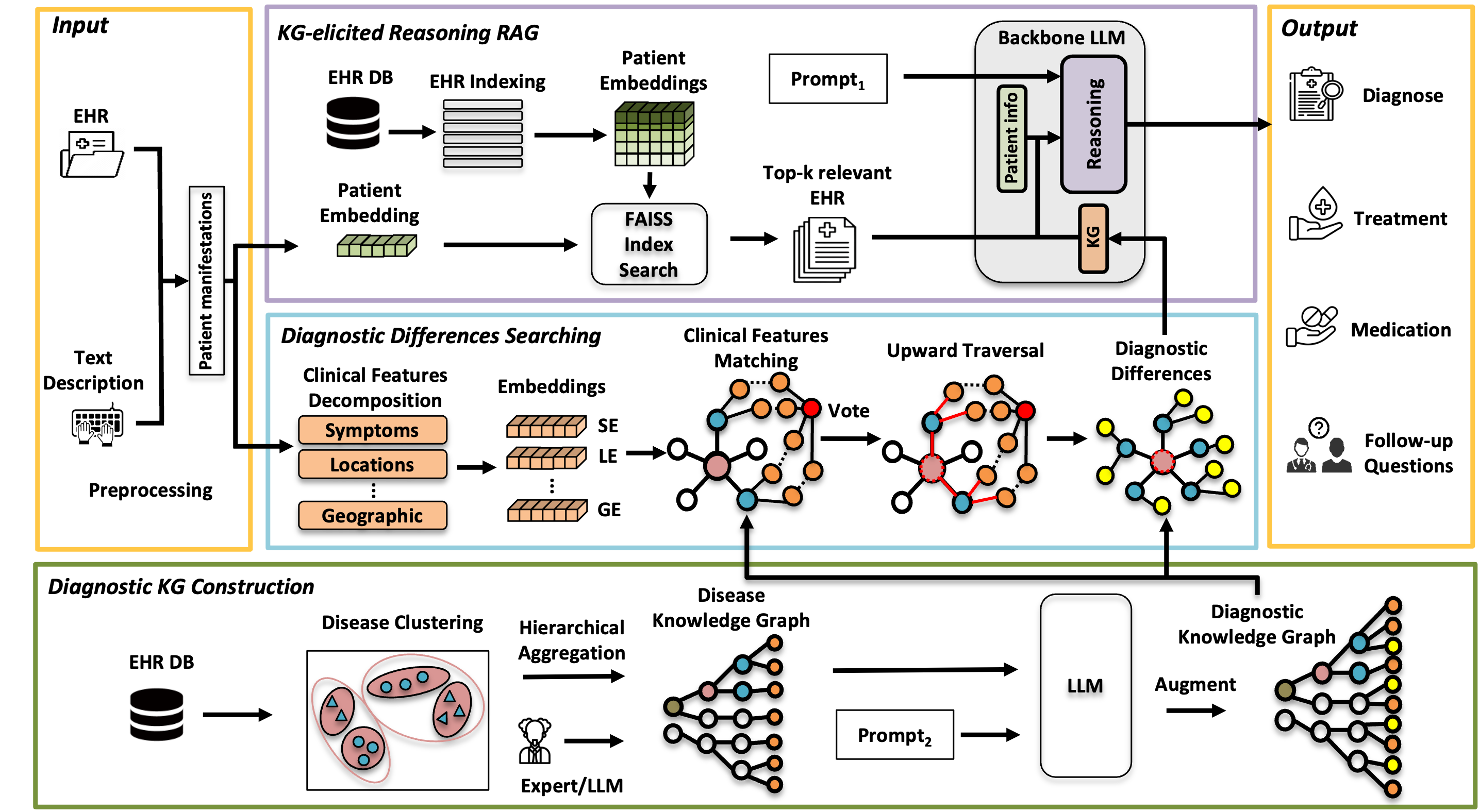
MedRAG是南洋理工大学研究团队提出的医学诊断模型,通过结合知识图谱推理增强大语言模型(LLM)的诊断能力。模型构建了四层细粒度诊断知识图谱,可精准分类不同病症表现,通过主动补问机制填补患者信息空白。MedRAG在真实临床数据集上诊断准确率提升了11.32%,具备良好的泛化能力,可应用于不同LLM基模型。MedRAG支持多模态输入,能实时解析症状并生成精准诊断建议。 MedRAG的主要功能
文本到图像的扩散模型的最新进展已取得显著成功,但它们往往难以完全捕捉用户的意图。现有的使用文本输入结合边界框或区域蒙版的方法无法提供精确的空间引导,常常导致对象方向错位或意外。为了解决这些限制,我们提出了涂鸦引导扩散(ScribbleDiff),这是一种无需训练的方法,它利用用户提供的简单涂鸦作为视觉提示来引导图像生成。然而,将涂鸦纳入扩散模型存在挑战,因为涂鸦具有稀疏和单薄的特性,很难确保准确的
FairyGen 是大湾区大学推出的动画故事视频生成框架,支持从单个手绘角色草图出发,生成具有连贯叙事和一致风格的动画故事视频。框架借助多模态大型语言模型(MLLM)进行故事规划,基于风格传播适配器将角色的视觉风格应用到背景中,用 3D Agent重建角色生成真实的运动序列,基于两阶段运动适配器优化视频动画的连贯性与自然度。FairyGen 在风格一致性、叙事连贯性和运动质量方面表现出色,为个性化
只显示前20页数据,更多请搜索
Showing 457 to 480 of 498 results