关键词 "Huggingface OpenAI detector" 的搜索结果, 共 24 条, 只显示前 480 条
SmolVLA 是 Hugging Face 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。 SmolVLA的主要功能 多模态输入处理:SmolVLA 能处理多种输入,包括多幅图像、语言指令以及
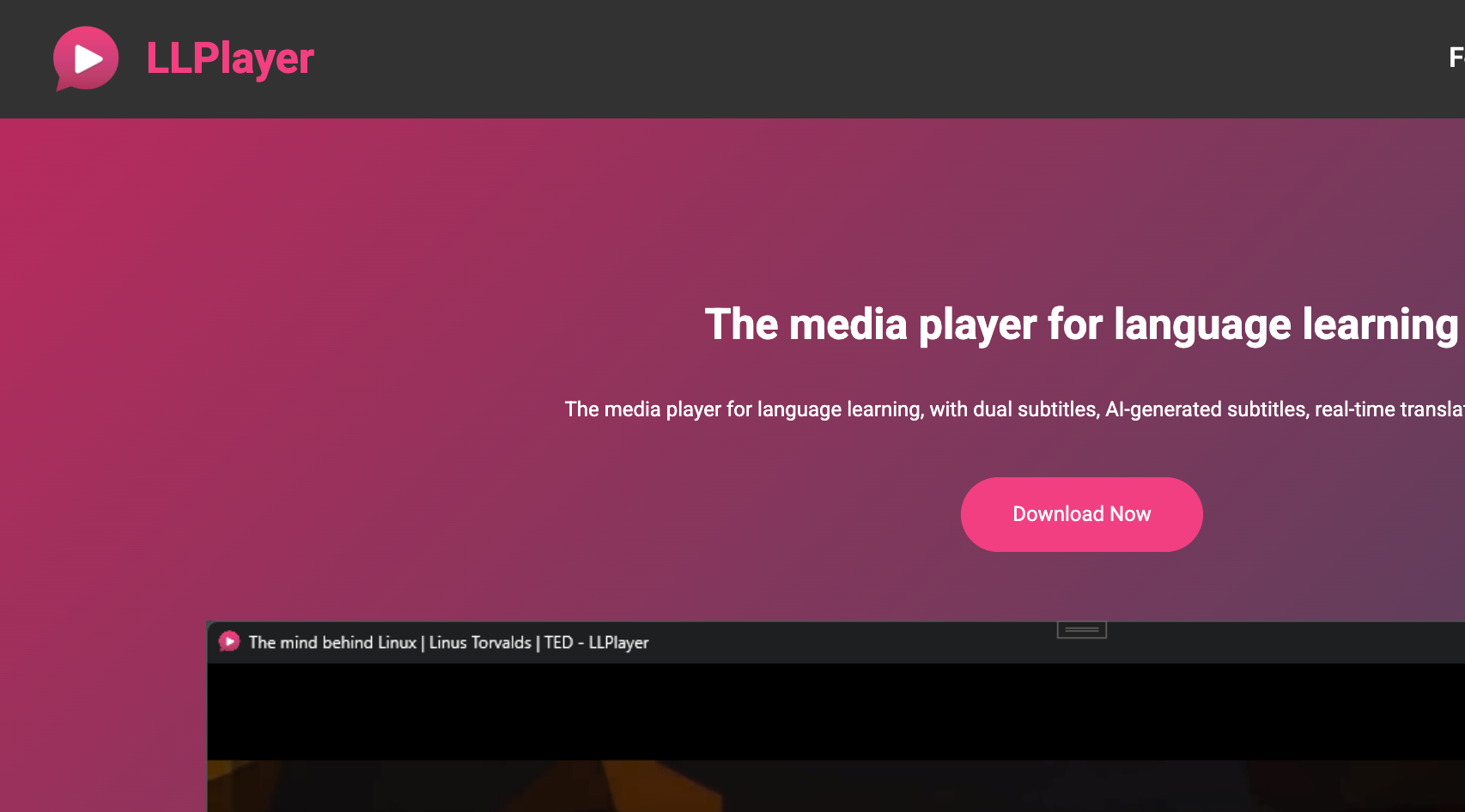
专注于字幕相关功能的视频播放器,例如双字幕、AI 生成字幕、实时翻译、单词查找等! LLPlayer 具有许多普通视频播放器所不具备的语言学习功能。 双字幕:可同时显示两个字幕。支持文本字幕和位图字幕。 AI 生成的字幕(ASR):由OpenAI Whisper提供支持,从任何视频和音频实时自动生成字幕。支持whisper.cpp和fastest-whisper两个引擎。 实时翻译:支
Kimi-Dev是Moonshot AI推出的开源代码模型,专为软件工程任务设计。模型拥有 72B 参数量,编程水平比最新的DeepSeek-R1还强,和闭源模型比较也表现优异。在 SWE-bench Verified数据集上达到60.4%的性能,超越其他开源模型,成为当前开源模型中的SOTA。Kimi-Dev 基于强化学习和自我博弈机制,能高效修复代码错误、编写测试代码。模型基于MIT协议开源,
MiniMax-M1是MiniMax团队最新推出的开源推理模型,基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,总参数量达 4560 亿,每个token激活 459 亿参数。模型超过国内的闭源模型,接近海外的最领先模型,具有业内最高的性价比。MiniMax-M1原生支持 100 万token的上下文长度,提供40 和80K两种推理预算版本,适合处理长输入
Lingshu是阿里巴巴达摩院推出的专注于医学领域的多模态大型语言模型。模型支持超过12种医学成像模态,包括X光、CT扫描、MRI等,在多模态问答、文本问答及医学报告生成等任务上展现出卓越的性能。Lingshu基于多阶段训练,逐步嵌入医学专业知识,显著提升在医学领域的推理和问题解决能力。推出7B、32B两个参数版本,其中32B版本在多个医学多模态问答任务中超越GPT-4.1等专有模型。Lingsh
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
FLUX.1 Kontext 是由 Black Forest Labs 推出的图像生成与编辑模型,支持上下文感知的图像处理。模型基于文本和图像提示进行生成与编辑,支持对象修改、风格转换、背景替换、角色一致性保持和文本编辑等多种任务。FLUX.1 Kontext Pro版本支持快速迭代图像编辑,能在多次编辑中保持图像质量和角色特征稳定。。Kontext Max版本在提示词遵循、排版生成和编辑一致性方
Fireplexity是Firecrawl推出的开源AI问答引擎,基于Next.js构建。Fireplexity支持让开发者快速搭建和托管自己的AI驱动的问答应用。具有快速部署(5分钟内启动)、无供应商锁定(完全开源,可自由定制)、实时智能(基于Firecrawl可靠抓取网页内容,智能筛选并合成带引用的答案)等特点。Fireplexity用GPT-4o-mini生成实时答案,支持替换为任何兼容Op
ML-Master是上海交通大学人工智能学院Agents团队推出ML-Master – 上海交大推出的AI专家Agent的AI专家智能体。在OpenAI的权威基准测试MLE-bench中表现出色,以29.3%的平均奖牌率位居榜首,超越了微软的RD-Agent和OpenAI的AIDE等竞争对手。ML-Master通过“探索-推理深度融合”的创新范式,模拟人类专家的认知策略,整合广泛探索与深度推理,显
ThinkSound是阿里通义语音团队推出的首个CoT(链式思考)音频生成模型,用在视频配音,为每一帧画面生成专属匹配音效。模型引入CoT推理,解决传统技术难以捕捉画面动态细节和空间关系的问题,让AI像专业音效师一样逐步思考,生成音画同步的高保真音频。模型基于三阶思维链驱动音频生成,包括基础音效推理、对象级交互和指令编辑。模型配备AudioCoT数据集,包含带思维链标注的音频数据。在VGGSoun
RoboBrain 2.0 是强大的开源具身大脑模型,能统一感知、推理和规划,支持复杂任务的执行。RoboBrain 2.0 包含 7B(轻量级)和 32B(全规模)两个版本,基于异构架构,融合视觉编码器和语言模型,支持多图像、长视频和高分辨率视觉输入,及复杂任务指令和场景图。模型在空间理解、时间建模和长链推理方面表现出色,适用机器人操作、导航和多智能体协作等任务,助力具身智能从实验室走向真实场景
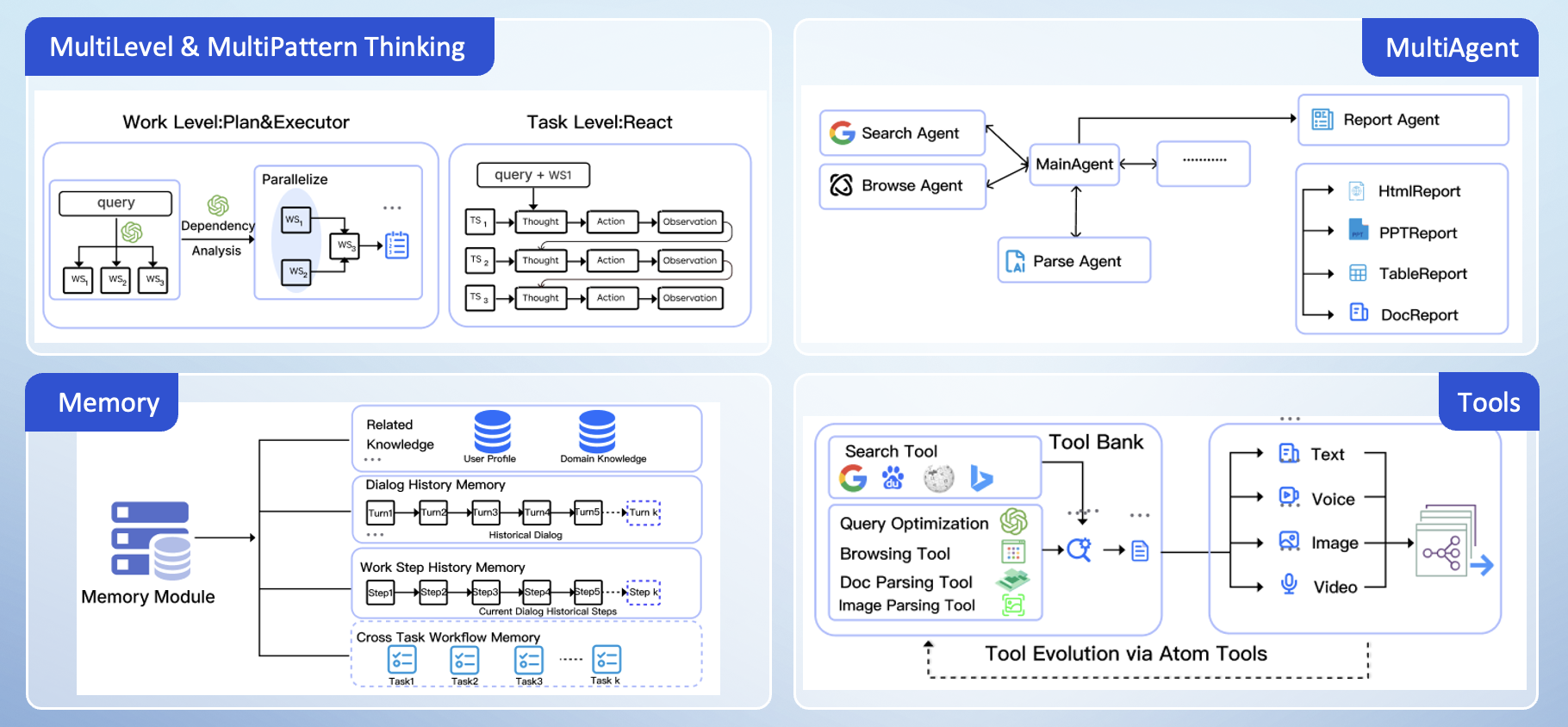
业界首个开源高完成度轻量化通用多智能体产品(JoyAgent-JDGenie) 解决快速构建多智能体产品的最后一公里问题 简介 当前相关开源agent主要是SDK或者框架,用户还需基于此做进一步的开发,无法直接做到开箱即用。我们开源的JoyAgent-JDGenie是端到端的多Agent产品,对于输入的query或者任务,可以直接回答或者解决。例如用户query"给我做一个最
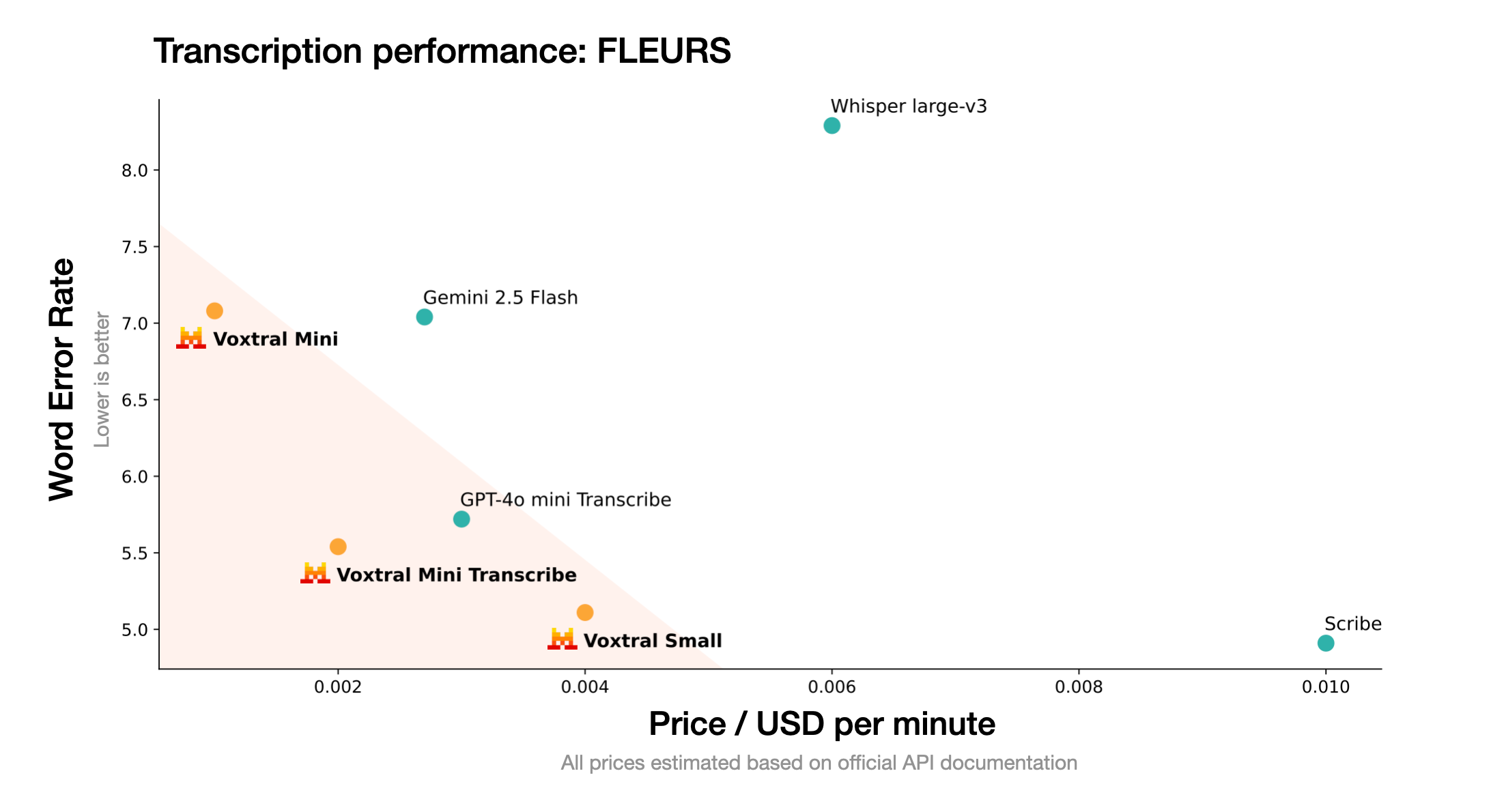
Mistral AI,最新发布了首个开源语音模型:Voxtral语音理解模型系列! 该模型包含24B和3B两个参数规模的版本,均基于Apache 2.0许可证开源,同时提供API服务接口。 Voxtral模型支持32k token的上下文窗口,能够处理长达30分钟的音频转录任务或40分钟的语义理解任务,在各项基准测试指标上全面超越目前主流的开源语音转录模型Whisper large-v3。
Detector de IA y Humanizador online y gratuito. Compatible con ChatGPT, GPT-4, Gemini y Claude. Gratis, sin registro, y rápido.
FLUX.1 Krea [dev] 是 Black Forest Labs 与 Krea AI 合作推出的最新文本到图像生成模型,支持生成更逼真、更多样化的图像,实现照片级真实感水平。模型具有独特的美学风格,避免过度饱和的纹理,同时与 FLUX.1 [dev] 生态系统兼容,支持diffusers库和ComfyUI。模型现已开源,商业许可可通过 BFL Licensing Portal 获取,且F
dots.ocr 是小红书 hi lab 开源的多语言文档布局解析模型。模型基于 17 亿参数的视觉语言模型(VLM),能统一进行布局检测和内容识别,保持良好的阅读顺序。模型规模虽小,但性能达到业界领先水平(SOTA),在 OmniDocBench 等基准测试中表现优异,公式识别效果能与Doubao-1.5和 gemini2.5-pro 等更大规模模型相媲美,在小语种解析方面优势显著。dots.o
DispatchMail 是开源的、本地运行的 AI 邮件助手,支持通过AI技术自动化收件箱管理。工具能实时监控邮件,用 OpenAI 的 AI Agent根据用户自定义的提示词对邮件进行智能处理和分析。工具提供本地运行的 Web 界面,支持邮件筛选、草稿生成、自动归档和深度发件人研究等功能。所有数据存储在本地 SQLite 数据库中,确保用户隐私和数据安全。 项目地址 GitHub仓库:
AI-Researcher 是香港大学数据科学实验室推出的开源自动化科学研究工具,基于大型语言模型(LLM)代理实现从研究想法到论文发表的全流程自动化。AI-Researcher 支持用户在两种模式下操作:一是提供详细的研究想法描述,系统据此生成实现策略;二是提供参考文献,系统自主生成创新想法实施。平台集成文献综述、想法生成、算法设计与验证、结果分析和论文撰写等核心功能,支持多领域研究,基于开源的
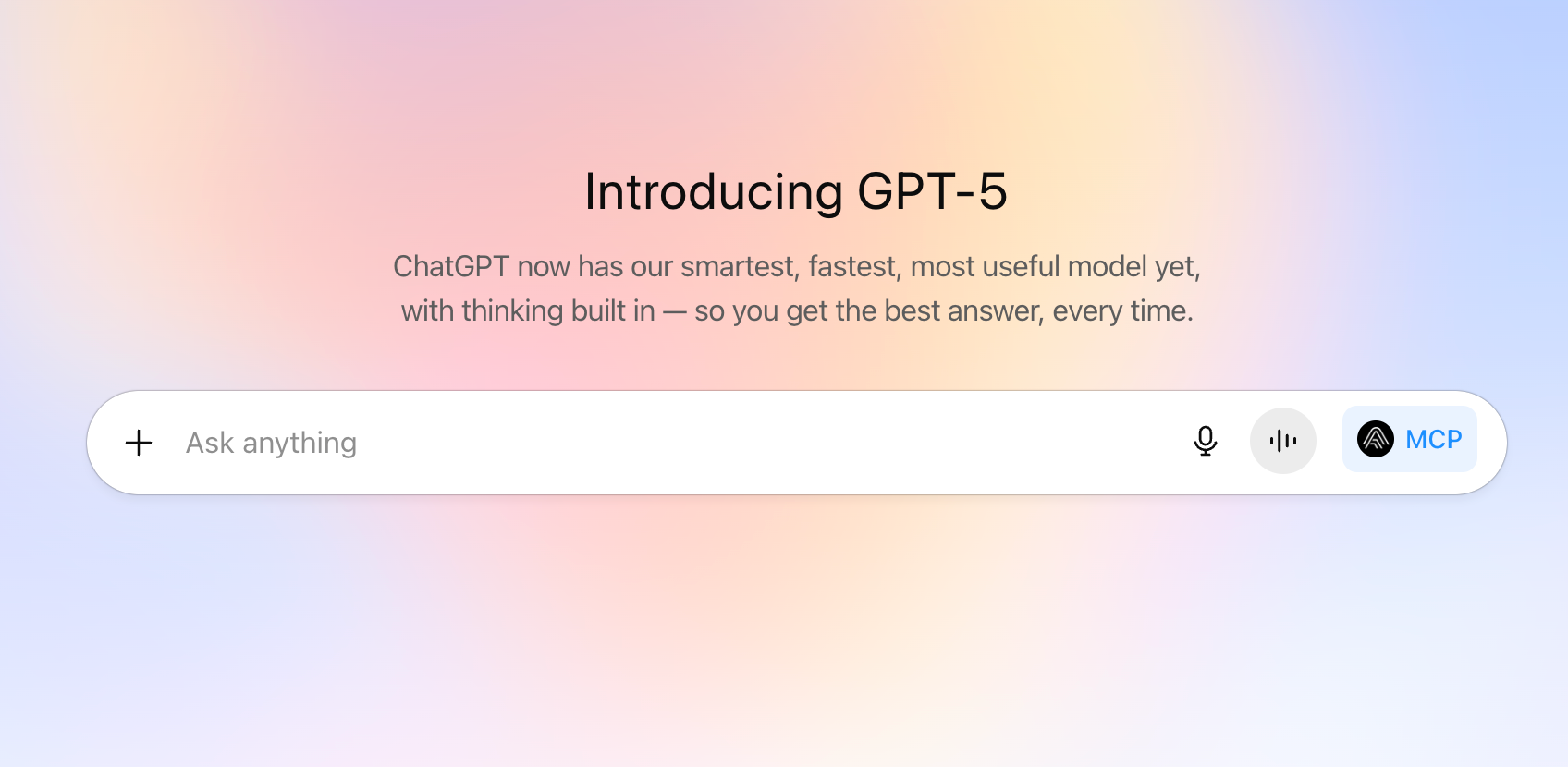
GPT-5 是 OpenAI 最新推出的人工智能模型,是目前最强模型,面向所有用户开放。GPT-5是一个统一系统,包括一个基础模型用在解答常见问题,一个深度推理模型(GPT-5 思维模块)用在处理复杂难题,一个实时路由模块根据对话类型、问题复杂度、工具需求和用户指令(如“仔细思考”)智能调度模型。GPT-5 在编程、写作、数学、健康等多个领域表现出色,大幅减少幻觉和错误,回答更贴近真实情况。GPT
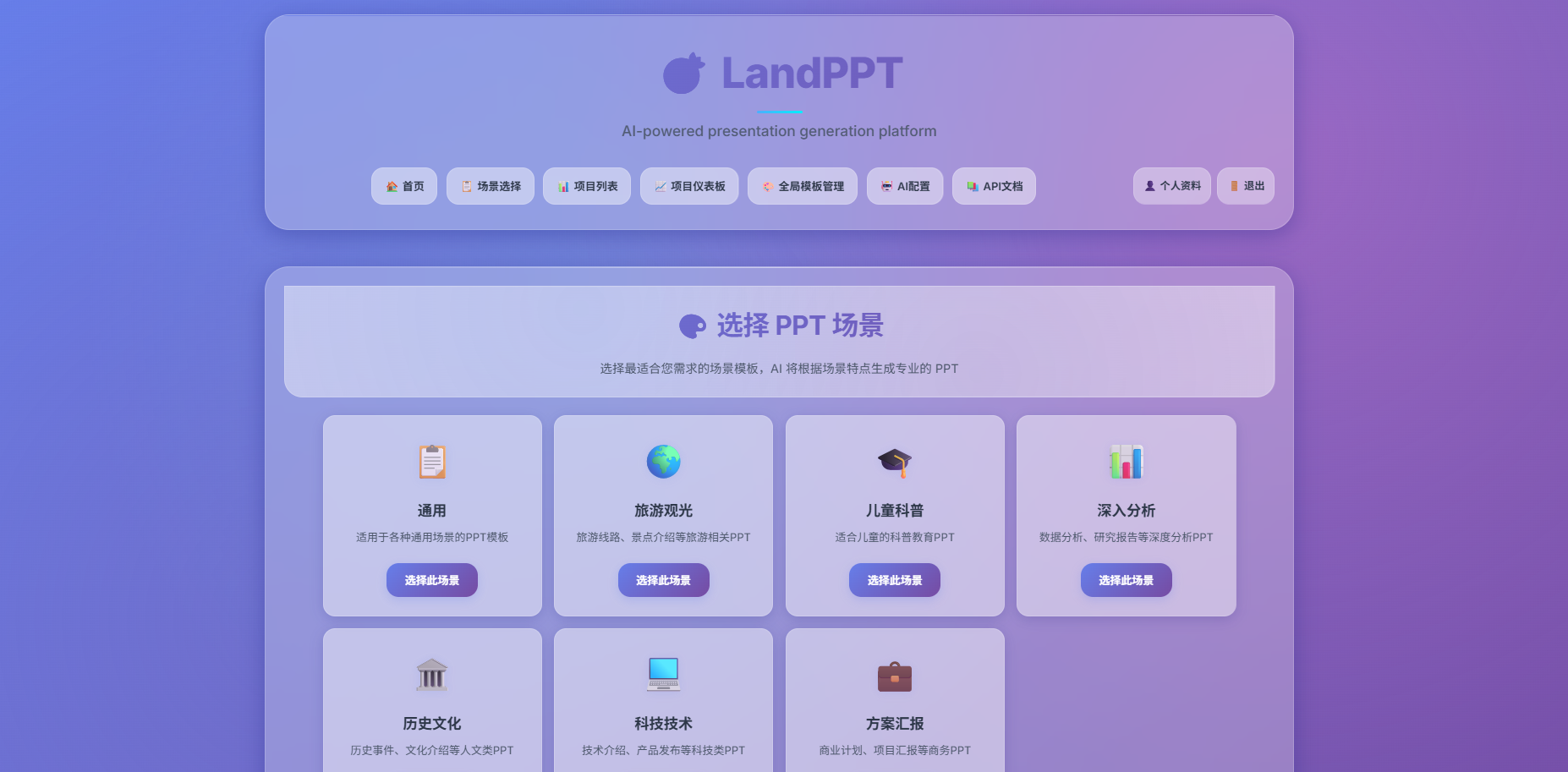
LandPPT 是AI演示文稿生成平台,能将文档内容快速转换为专业的 PPT 演示文稿。LandPPT支持 OpenAI、Claude、Gemini 等多种 AI 模型,兼容 PDF、Word、Markdown 等文件格式,支持智能解析内容,生成结构清晰的大纲和精美的 PPT 页面。平台提供丰富的模板系统和自定义功能,用户基于现代化的 Web 界面进行可视化编辑、实时预览和多格式导出。LandPP
NeuralAgent 是开源的桌面 AI 个人助手,通过自然语言指令自动化执行多种复杂任务,如模拟键盘输入、鼠标点击、浏览器导航、表单填写和邮件发送等。NeuralAgent 支持桌面自动化,在 Windows 平台上支持后台浏览器控制,实现高效任务处理。NeuralAgent 集成 Claude、GPT-4、Azure OpenAI、Bedrock、Ollama 和 Gemini 等多种主流语
WrenAI 是 Canner 推出的开源商业智能 AI Agent工具。通过自然语言交互,帮助用户快速查询、分析和可视化结构化数据,无需编写复杂的 SQL 代码。用户只需用普通语言提出问题,WrenAI 能生成精准的 SQL 查询语句,以图表、报告等多种形式输出结果。通过架构嵌入和相关性检索,确保查询的准确性和上下文对齐。支持多种主流数据库(如 PostgreSQL、MySQL、Snowflak
Glass 是Pickle 团队推出的开源隐形 AI 桌面助手。Glass能在后台实时捕捉屏幕内容和音频,将其转化为结构化知识。Glass核心功能包括实时会议记录、自动摘要生成、上下文理解及实时问答。Glass 的设计真正隐形,不会出现在屏幕录制、截图或 Dock 中,完全不干扰用户操作。Glass支持 macOS 和 Windows 系统,用户能免费使用,且无需注册。Glass开源特性成为 AI
只显示前20页数据,更多请搜索
Showing 433 to 456 of 482 results