关键词 "Human avatar" 的搜索结果, 共 24 条, 只显示前 480 条
An MCP Server for Gravatar
You are the MCP server!
Simple MCP Server to enable a human-in-the-loop workflow in tools like Cline and Cursor.
VRChat MCP OSC provides a bridge between AI assistants and VRChat using the Model Context Protocol (MCP), enabling AI-driven avatar control and interactions in virtual reality environments. By levera
A Browser Automation Tool for Humans and AI - Built with Playwright, optimized for Bun runtime, supporting CLI and MCP Server modes for webpage analysis and automation
Model Context Protocol Server to facilitate llms to able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created.
Mirror of
MCP Server to assist LLMs and humans on Model Context Protocol spec compliance and understanding
Just unleashed a "Model Context Protocol" (MCP) server that's basically JARVIS but with more attitude and less British accent! When the robot uprising happens, I'll be on their "handled this human's w
MCP server for generating human face images with various shapes and sizes
Meta发布AssetGen 2.0 AI模型,可高效生成3D资产 Meta发布了AssetGet 2.0版本,Meta表示,2.0显著提升了细节和保真度,其中包括几何一致性和极其精细的细节。“AssetGen 2.0为行业树立了全新标准,并利用生成式AI突破了可能性的界限。” 从技术原理来看,AssetGen 1.0需要根据提示生成目标素材的多个2D图像视图,然后
DreamFit是什么 DreamFit是字节跳动团队联合清华大学深圳国际研究生院、中山大学深圳校区推出的虚拟试衣框架,专门用在轻量级服装为中心的人类图像生成。框架能显著减少模型复杂度和训练成本,基于优化文本提示和特征融合,提高生成图像的质量和一致性。DreamFit能泛化到各种服装、风格和提示指令,生成高质量的人物图像。DreamFit支持与社区控制插件的无缝集成,降低使用门槛。 Dre
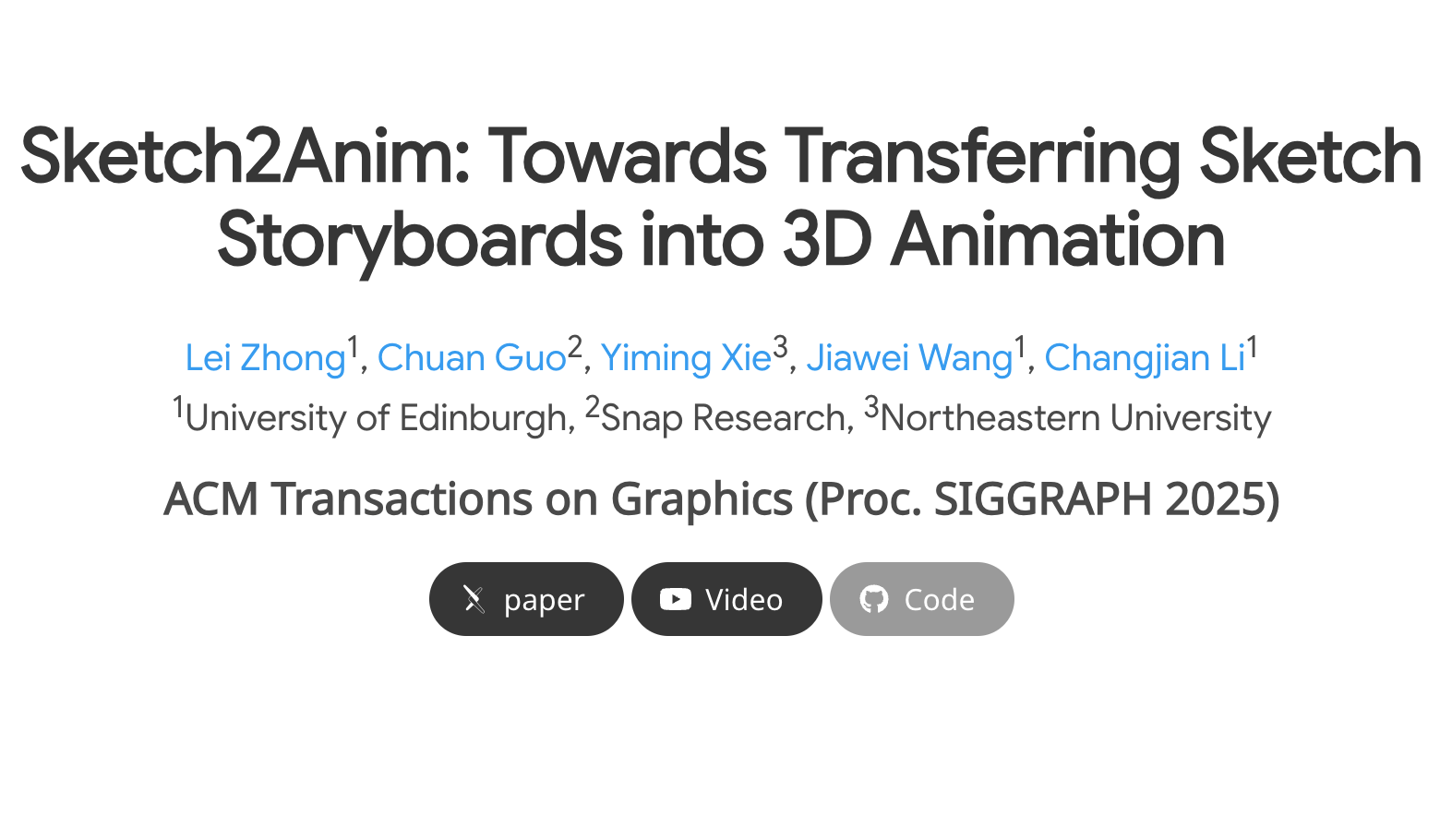
Sketch2Anim 是爱丁堡大学联合Snap Research、东北大学推出的自动化框架,能将2D草图故事板直接转换为高质量的3D动画。基于条件运动合成技术,用3D关键姿势、关节轨迹和动作词精确控制动画的生成。框架包含两个核心模块,多条件运动生成器和2D、3D神经映射器。Sketch2Anim能生成自然流畅的3D动画,支持交互式编辑,极大地提高动画制作的效率和灵活性。 Sketch2Anim
HRAvatar是清华大学联合IDEA团队推出的单目视频重建技术,支持从普通单目视频中生成高质量、可重光照的3D头像。HRAvatar用可学习的形变基和线性蒙皮技术,基于精准的表情编码器减少追踪误差,提升重建质量。HRAvatar将头像外观分解为反照率、粗糙度和菲涅尔反射等属性,结合物理渲染模型,实现真实的重光照效果。HRAvatar在多个指标上优于现有方法,支持实时渲染(约155 FPS),为数
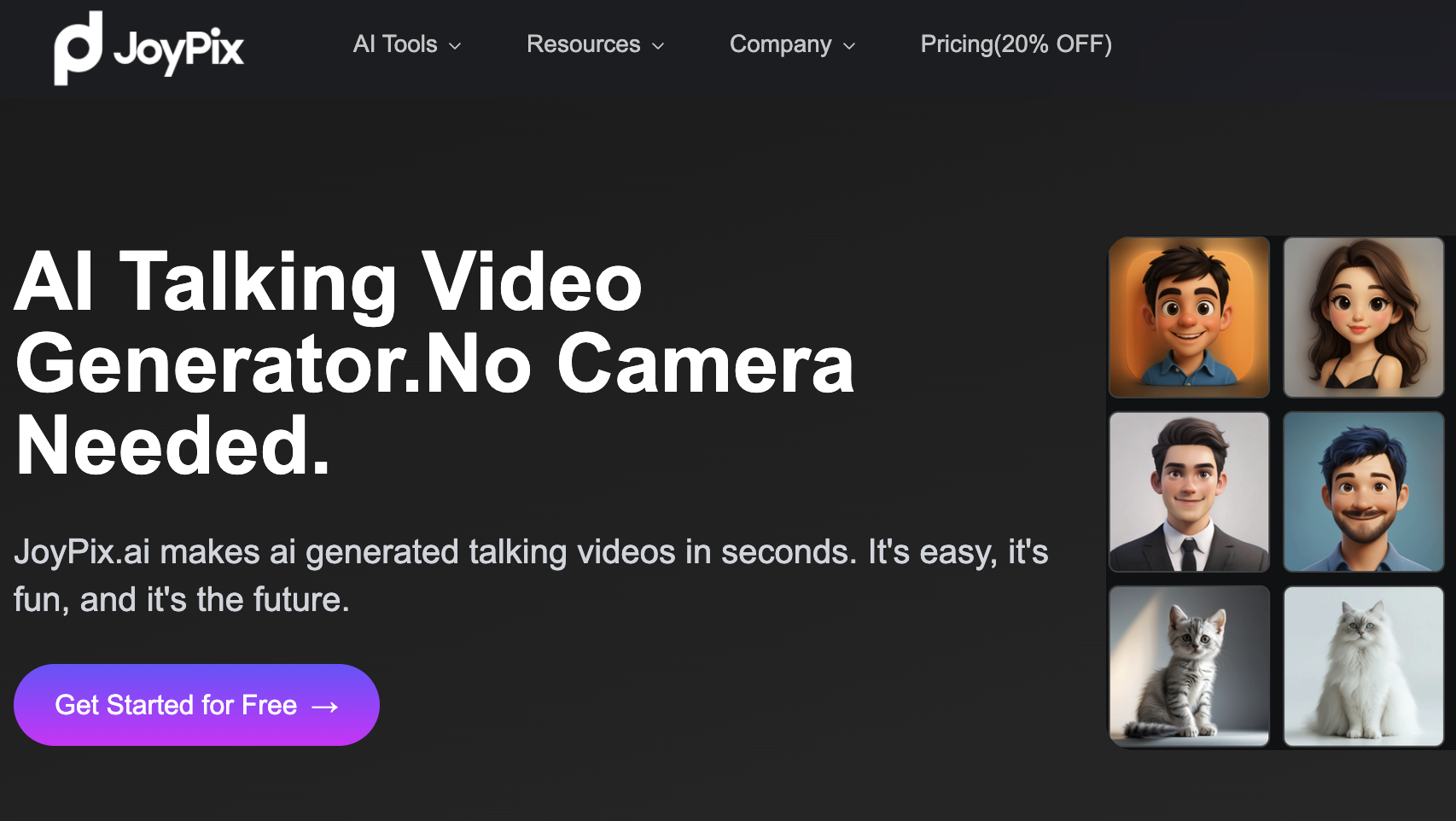
JoyPix 是专注于数字人和语音合成的AI创作工具。用户可以通过上传照片创建个性化的虚拟形象,支持与虚拟形象进行语音对话。JoyPix 提供自定义虚拟形象,可以根据自己的需求进一步定制虚拟形象的外观。JoyPix支持声音克隆,用户只需上传10秒音频片段,可克隆自己的声音,生成自然流畅的语音输出。JoyPix 的文本转语音功能可以将文本转换为逼真的语音,满足多种语音合成需求。JoyPix提供了虚拟
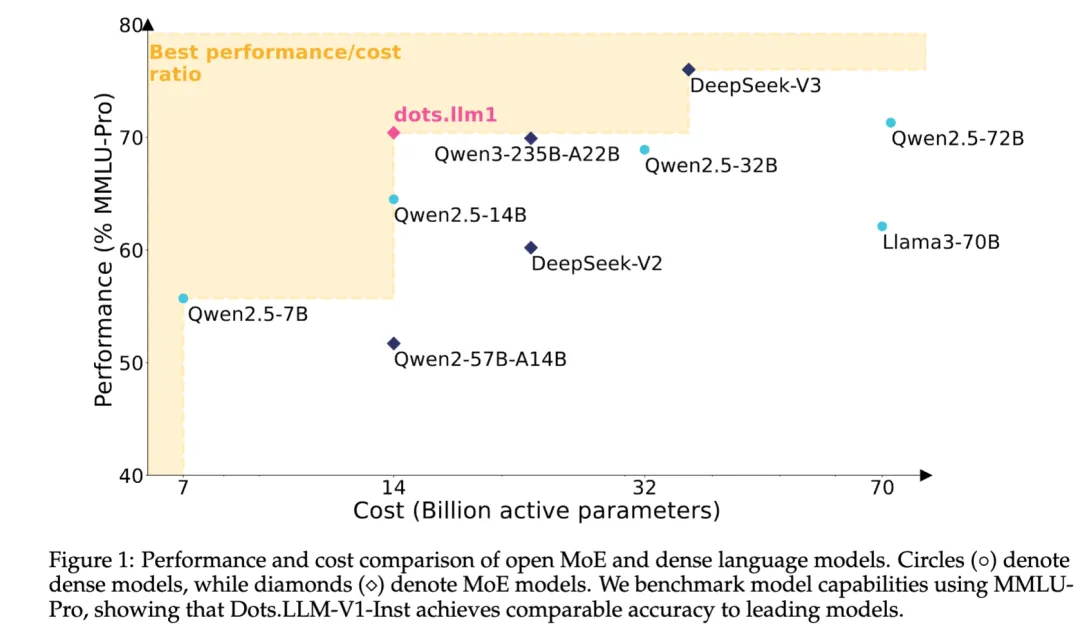
小红书hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源文本大模型 dots.llm1。 dots.llm1是一个中等规模的Mixture of Experts (MoE)文本大模型,在较小激活量下取得了不错的效果。该模型充分融合了团队在数据处理和模型训练效率方面的技术积累,并借鉴了社区关于 MoE 的最新开源成果。hi lab团队开源了所有模型和必要的训练
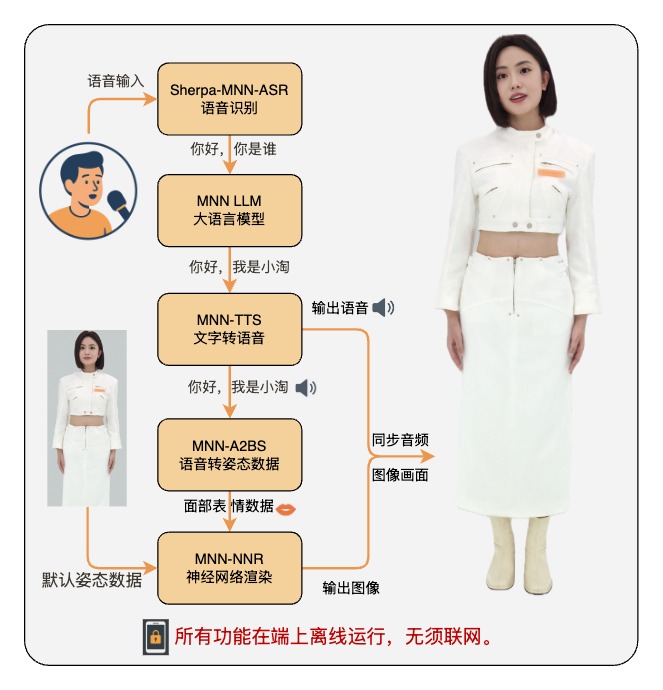
MNN轻量级高性能推理引擎 通用性 - 支持TensorFlow、Caffe、ONNX等主流模型格式,支持CNN、RNN、GAN等常用网络。 高性能 - 极致优化算子性能,全面支持CPU、GPU、NPU,充分发挥设备算力。 易用性 - 转换、可视化、调试工具齐全,能方便地部署到移动设备和各种嵌入式设备中。 什么是 TaoAvatar?它是阿里最新研究
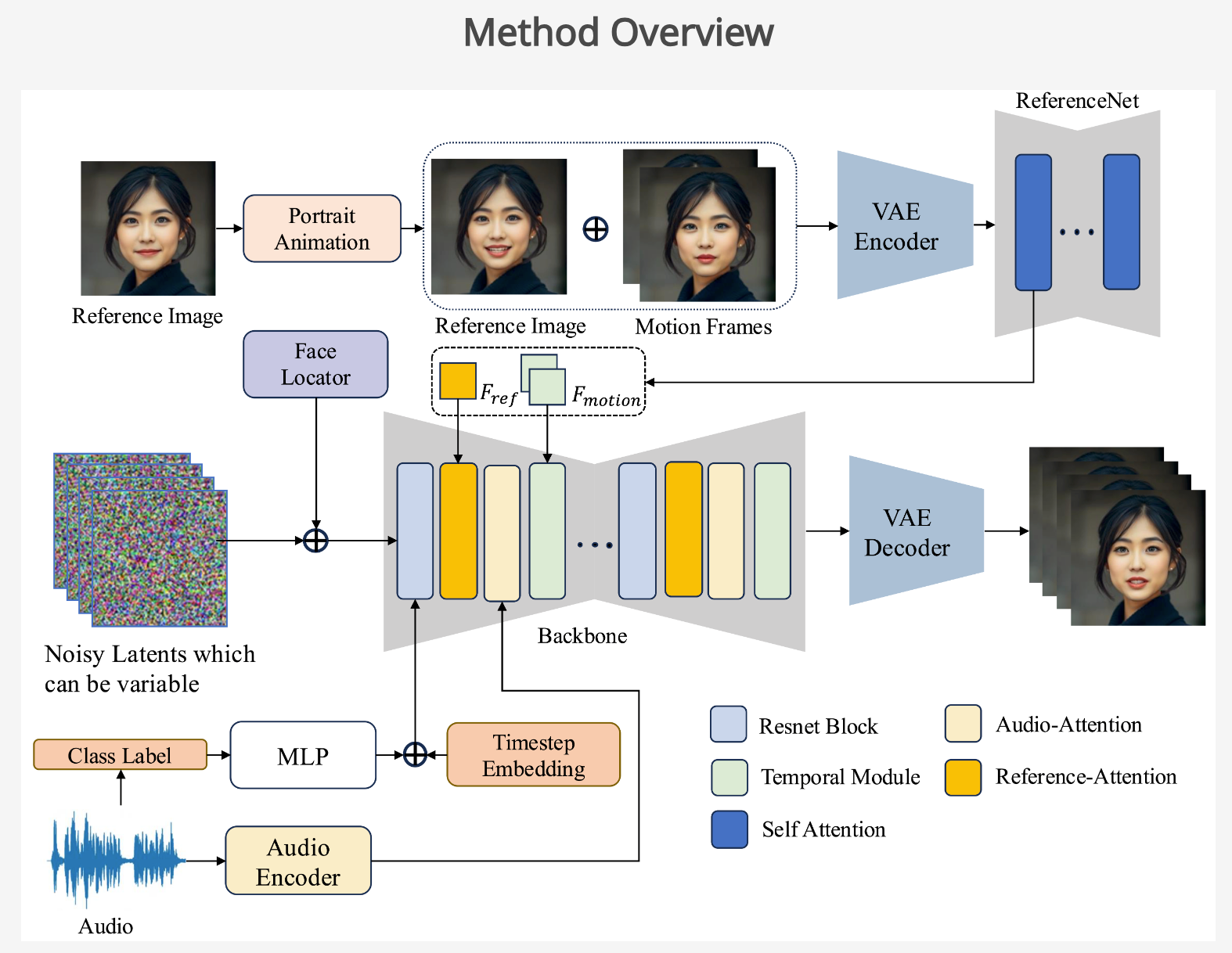
LLIA(Low-Latency Interactive Avatars)是美团公司推出的基于扩散模型的实时音频驱动肖像视频生成框架。框架基于音频输入驱动虚拟形象的生成,支持实现低延迟、高保真度的实时交互。LLIA用可变长度视频生成技术,减少初始视频生成的延迟,结合一致性模型训练策略和模型量化技术,显著提升推理速度。LLIA支持用类别标签控制虚拟形象的状态(如说话、倾听、空闲)及面部表情的精细控制
An AI text humanizer transforms AI-generated content into natural, human-like text. It adds flow, uses conversational phrasing, and avoids robotic language. Our humanization tool helps create engaging
Detector de IA y Humanizador online y gratuito. Compatible con ChatGPT, GPT-4, Gemini y Claude. Gratis, sin registro, y rápido.
Humanize AI provides One-stop Writing Assistant. Save yourself time, energy, and frustration with our range of helpful products.
OmniHuman-1.5 字节推出的先进的AI模型,能从单张图片和语音轨道生成富有表现力的数字人动画。模型基于双重系统认知理论,融合多模态大语言模型和扩散变换器,模拟人类的深思熟虑和直觉反应。模型能生成动态的多角色动画,支持通过文本提示进行细化,实现更精准的动画效果。OmniHuman-1.5 的动画具有复杂的角色互动和丰富的情感表现,为动画制作和数字内容创作带来全新的可能性,大大提升创作效率和
只显示前20页数据,更多请搜索
Showing 457 to 480 of 482 results