关键词 "OpenAI token counter" 的搜索结果, 共 24 条, 只显示前 480 条
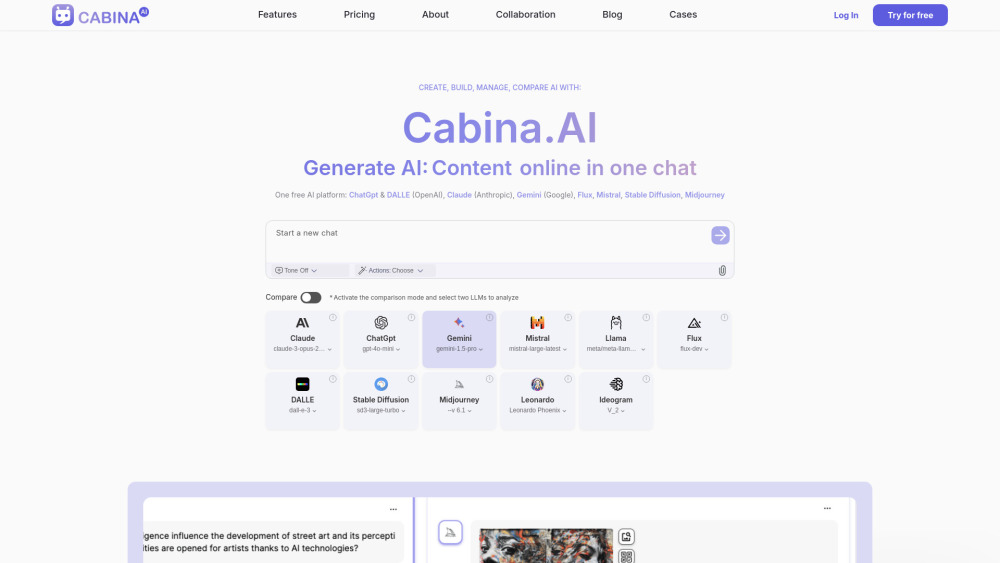
All-in-one AI Chats workspace: productivity, communication & education
Bearly is an exceptional AI tool accessible via hotkey, enhancing workflow with advanced capabilities.
Effortlessly bypass CAPTCHAs with advanced AI.
Token-gate content access with AI writing assistance.
All-in-one AI app with multiple AI models.
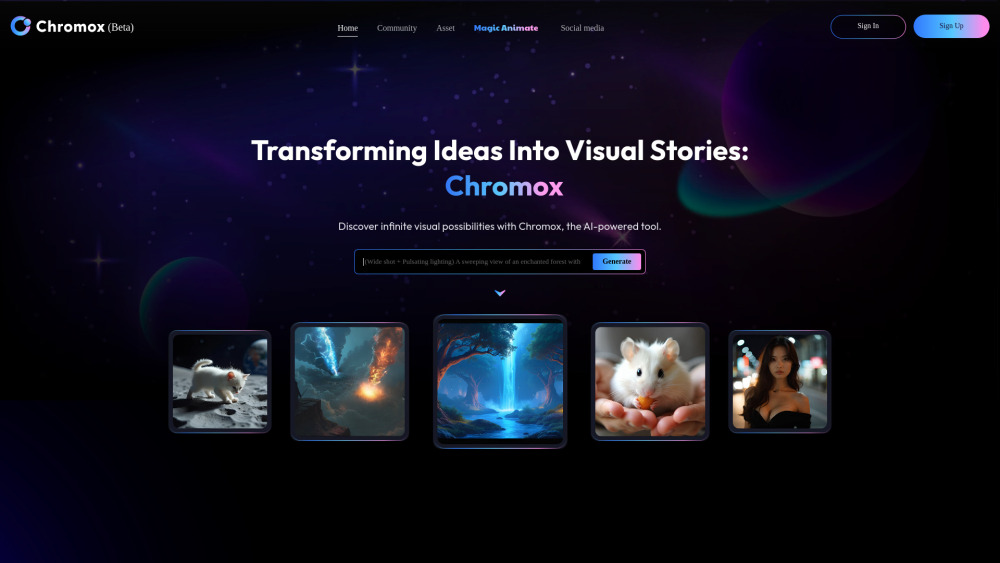
The best Free OpenAI Sora alternatives for generating AI videos.
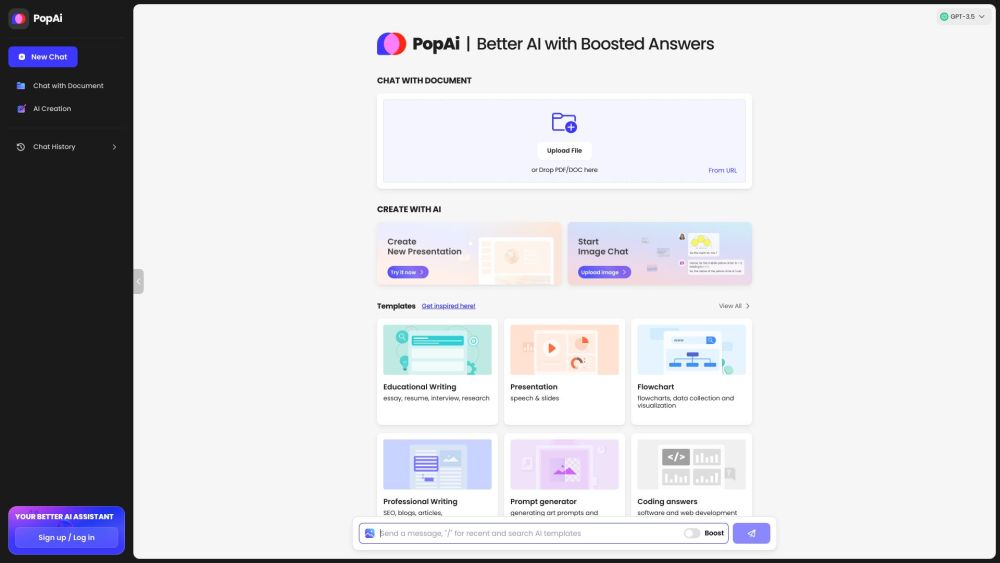
Boost productivity with PopAi's powerful AI tool!
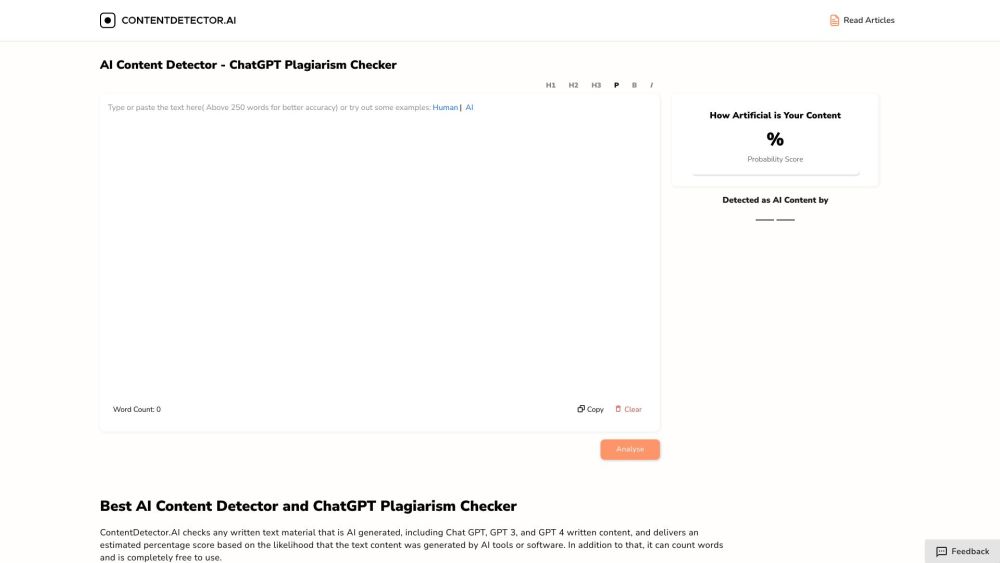
A free AI content detector, ChatGPT plagiarism checker, and word counter.
Create AudioBooks or MP3 files from PDFs and eBooks.
LabLab is a platform that encourages innovation with AI technology through hackathons and events.
Free AI chat interface for advanced problem-solving.
ChatGPT alternative for powerful AI chat capabilities
ZeroGPT is a powerful, accurate AI tool for detecting chatGPT content, OpenAI-generated text, and plagiarism.
一款轻量级终端运行编码智能体 —— Codex CLI,该工具现已在 GitHub 完全开源。是OpenAI开发的。 Codex CLI 可以直接在用户的计算机上工作,旨在最大化 o3 和 o4-mini 等模型的推理能力,并即将支持 GPT-4.1 等额外的 API 模型。 Codex CLI 可以在 macOS 12+、Ubuntu 20.04+/Debian 10+、Windows 11
TCMLLM由北京交通大学计算机与信息技术学院医学智能团队开发的中医药大语言模型项目,旨在通过大模型方式实现中医临床辅助诊疗(病证诊断、处方推荐等)中医药知识问答等任务,推动中医知识问答、临床辅助诊疗等领域的快速发展。目前针对中医临床智能诊疗问题中的处方推荐任务,发布了中医处方推荐指令微调大模型TCMLLM-PR。研发团队整合了8个数据来源,涵盖4本中医经典教科书《中医内科学》、《中医外科学》、《
Langchain-Chachat(原Langchain-ChatGLM)基于Langchain与ChatGLM、Qwen与Llama等语言模型的RAG与Agent应用| Langchain-Chatatch(以前称为 langchain-ChatGLM),基于本地知识的 LLM(如 ChatGLM、Qwen 和 Llama)RAG 和带有 langchain 的代理应用程序 ✅ 本项目支持主流
LangChain for Java:利用 LLM 的强大功能增强你的 Java 应用程序 LangChain4j 的目标是简化 LLM 与 Java 应用程序的集成。 方法如下: 统一的 API: LLM 提供商(例如 OpenAI 或 Google Vertex AI)和嵌入(向量)存储(例如 Pinecone 或 Milvus)使用专有 API。LangChain4j 提供统一
集成20+领先AI模型(包括OpenAI、Anthropic、Google等),支持深度研究和AI代理功能。用户可通过简单界面调用多种模型,适合复杂任务和跨模型比较。
一款支持主流大语言模型、主流聊天平台的聊天的机器人! 可 DIY 的 多模态 AI 聊天机器人 | 🚀 快速接入 微信、 QQ、Telegram、等聊天平台 | 🦈支持DeepSeek、Grok、Claude、Ollama、Gemini、OpenAI | 工作流系统、网页搜索、AI画图、人设调教、虚拟女仆、语音对话 |
PDF scientific paper translation with preserved formats - 基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI 等服务,提供 CLI/GUI/MCP/Docker/Zotero
Higress 是一款云原生 API 网关,集成了流量网关、微服务网关、安全网关和 AI 网关的功能。 它基于 Istio 和 Envoy 开发,支持使用 Go/Rust/JS 等语言编写 Wasm 插件。 提供了数十个通用插件和开箱即用的控制台。 Higress AI 网关支持多种 AI 服务提供商,如 OpenAI、DeepSeek、通义千问等,并具备令牌限流、消费者鉴权、WAF 防护、
🤯 Lobe Chat - an open-source, modern-design AI chat framework. Supports Multi AI Providers( OpenAI / Claude 3 / Gemini / Ollama / DeepSeek / Qwen), Knowledge Base (file upload / knowledge management /
DeepWiki :基于 GitHub Repo 源代码生成最新版可对话式文档,由 Devin驱动。 开源项目免费使用,无需注册。 私有项目中使用需在 http://devin.ai 注册账号。 直接访问 https://deepwiki.com,或将 GitHub 链接中的 github 替换为 deepwiki。 即:GitHub 仓库链接中的 github 替换为 deepwiki,
潮汐AIGC问答系统,聚合多模态大模型、知识库、插件和工作流等 Agent 构建能力,致力于为用户提供 LLM 大语言模型落地应用的强大在线平台。 新版本采用 Gin + Vite5 TypeScript Vue3 技术栈,拥有极致的响应速度;在更简洁的界面下保留完整功能,拥有更多的细节但是更加轻量化,拥有新的UI及交互方式,内置6组不同风格的显示效果,以及更流畅的使用体验。 AI对话
只显示前20页数据,更多请搜索
Showing 265 to 288 of 492 results