关键词 "PDF parsing" 的搜索结果, 共 24 条, 只显示前 480 条
II-Agent:一个用于构建和部署智能体的全新开源框架。II-Agent 是一款开源智能助手,旨在简化和增强跨领域的工作流程。它代表了我们与技术互动方式的重大进步——从被动工具转变为能够独立执行复杂任务的智能系统。作为简易的COZE,Dify平替。 ii-agent开源框架,擅长构建跨多个领域工作流的Agent,能独立执行复杂任务已是Agent标配 其技能覆盖研究与核查、内容生成、数据分析可视
Aurora是微软研究院推出的13亿参数的大气基础模型,基于从海量大气数据中提取有价值信息,用在预测全球天气模式、空气污染和海洋波浪等大气过程。模型用预训练和微调的架构,处理不同分辨率和压力水平的数据。Aurora在多个预测任务中表现出色,包括高分辨率天气预测、空气污染预测和热带气旋轨迹预测,计算速度比传统数值天气模型快约5000倍。模型提高了预测精度,降低计算成本,为应对气候变化和极端天气事件提
HRAvatar是清华大学联合IDEA团队推出的单目视频重建技术,支持从普通单目视频中生成高质量、可重光照的3D头像。HRAvatar用可学习的形变基和线性蒙皮技术,基于精准的表情编码器减少追踪误差,提升重建质量。HRAvatar将头像外观分解为反照率、粗糙度和菲涅尔反射等属性,结合物理渲染模型,实现真实的重光照效果。HRAvatar在多个指标上优于现有方法,支持实时渲染(约155 FPS),为数
RelightVid是上海 AI Lab、复旦大学、上海交通大学、浙江大学、斯坦福大学和香港中文大学推出用在视频重照明的时序一致性扩散模型,支持根据文本提示、背景视频或HDR环境贴图对输入视频进行细粒度和一致的场景编辑,支持全场景重照明和前景保留重照明。模型基于自定义的增强管道生成高质量的视频重照明数据对,结合真实视频和3D渲染数据,在预训练的图像照明编辑扩散框架(IC-Light)基础上,插入可
3DTown 是哥伦比亚大学联合Cybever AI等机构推出的从单张俯视图生成3D城镇场景框架。框架基于区域化生成和空间感知的3D修复技术,将输入图像分解为重叠区域,基于预训练的3D对象生成器分别生成每个区域的3D内容,基于掩码修正流修复过程填补缺失的几何结构,同时保持结构连续性。3DTown 支持生成具有高几何质量和纹理保真度的连贯3D场景,在多种风格的场景生成中表现出色,优于现有的先进方法。
橙篇是由百度推出的一款AI写作工具,基于百度文库的庞大内容库和尖端AI技术,为用户提供了强大的长文件处理和内容创作能力。用户可以利用橙篇AI轻松理解、总结超大量、多格式、长篇幅的文件,并通过即时问答功能获得所需信息。此外,橙篇还支持长文生成、深度编辑和多模态创作,极大地丰富了用户的创作手段。橙篇的研发基于百度文库12亿内容的积累,结合了20万精调数据和1.4亿用户的行为数据,以及百度文库、百度学术
夸克是阿里推出的AI搜索应用,集成了浏览器搜索、网盘、实用工具等功能。夸克支持手机版、Pad版、Windows电脑PC版,资产一键同步。提供6T超大空间、AI总结、AI生成等智能服务。用户可通过手机扫码快速登录,享受无缝的多端协同体验。夸克极速、安全、高效、高颜值,是你的学习、工作、生活的高效拍档。 夸克的功能特色 智能搜索:夸克基于AI智能引擎提供快速、准确的搜索结果,查资料更快,工作,
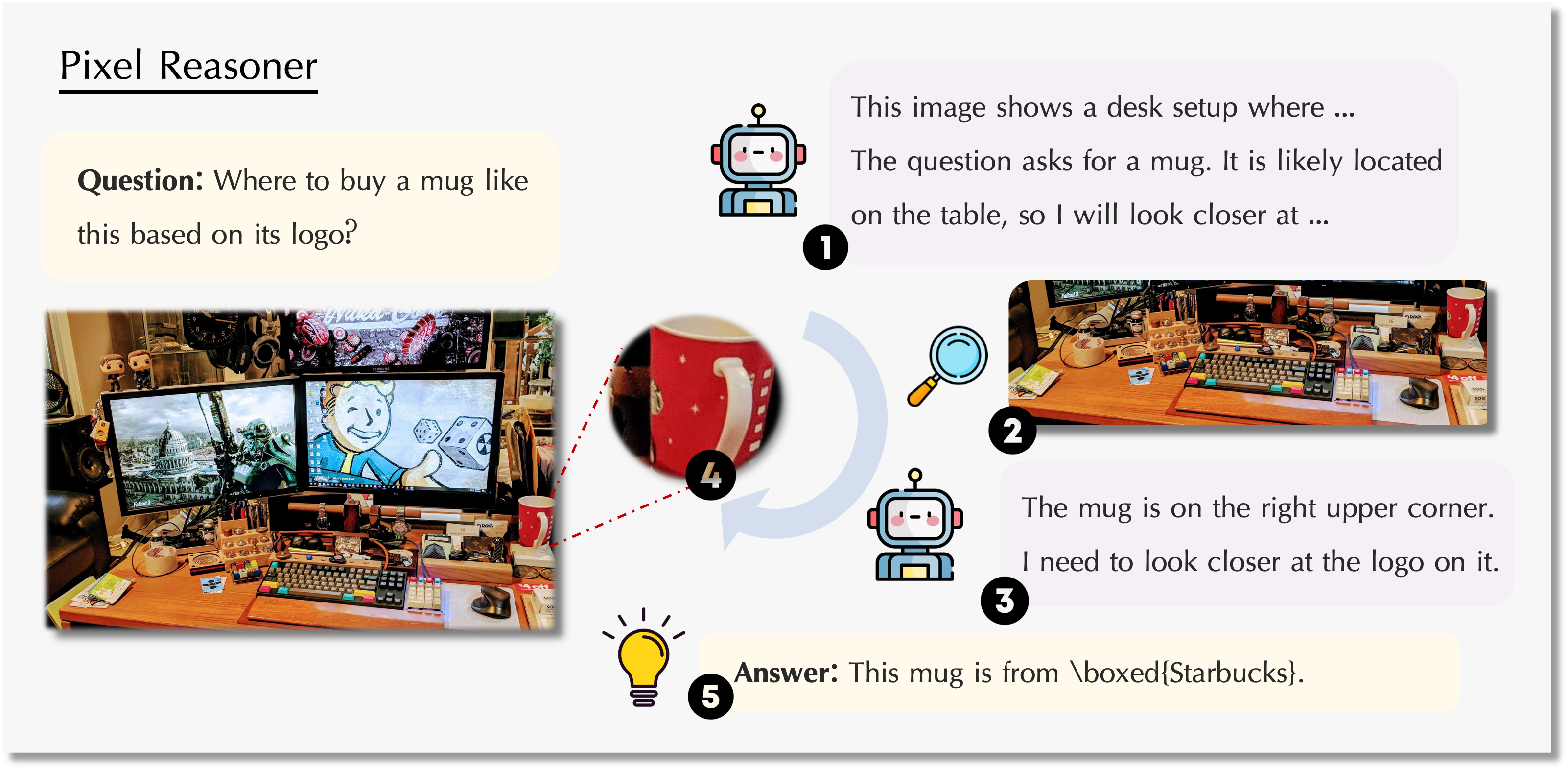
视觉语言模型(VLM),基于像素空间推理增强模型对视觉信息的理解和推理能力。模型能直接在视觉输入上进行操作,如放大图像区域或选择视频帧,更细致地捕捉视觉细节。Pixel Reasoner用两阶段训练方法,基于指令调优让模型熟悉视觉操作,用好奇心驱动的强化学习激励模型探索像素空间推理。Pixel Reasoner在多个视觉推理基准测试中取得优异的成绩,显著提升视觉密集型任务的性能。 Pixel R
Vid2World是清华大学联合重庆大学推出的创新框架,支持将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。模型基于视频扩散因果化和因果动作引导两大核心技术,解决传统VDM在因果生成和动作条件化方面的不足。Vid2World在机器人操作和游戏模拟等复杂环境中表现出色,支持生成高保真、动态一致的视频序列,支持基于动作的交互式预测。Vid2World为提升世界模
Morphik 是开源的多模态检索增强生成(RAG)工具,专为处理高技术性和视觉内容丰富的文档设计。支持对图像、PDF、视频等多种格式的文档进行搜索,采用 ColPali 等技术,能理解文档中的视觉内容。Morphik 具备快速元数据提取功能,可从文档中提取边界框、标签、分类等信息。 Morphik的主要功能 多模态数据处理:能处理文本、PDF、图片、视频等多种格式的文件。 智能解析文件
MemenomeLM 是 Brainrot AI 推出的AI工具,专为Z世代研究人员设计,可将PDF文档、笔记等资料转化为有趣且互动性强的视频内容。具有多模态理解能力,能将复杂概念用简单语言解释并提供现实例子,能将文献转化为多种格式的短视频,如Brainrot Quiz、Yap Dollar等,支持添加搞笑音效、生成图片及选择不同语音。 MemenomeLM的主要功能 AI视频创作:用户可
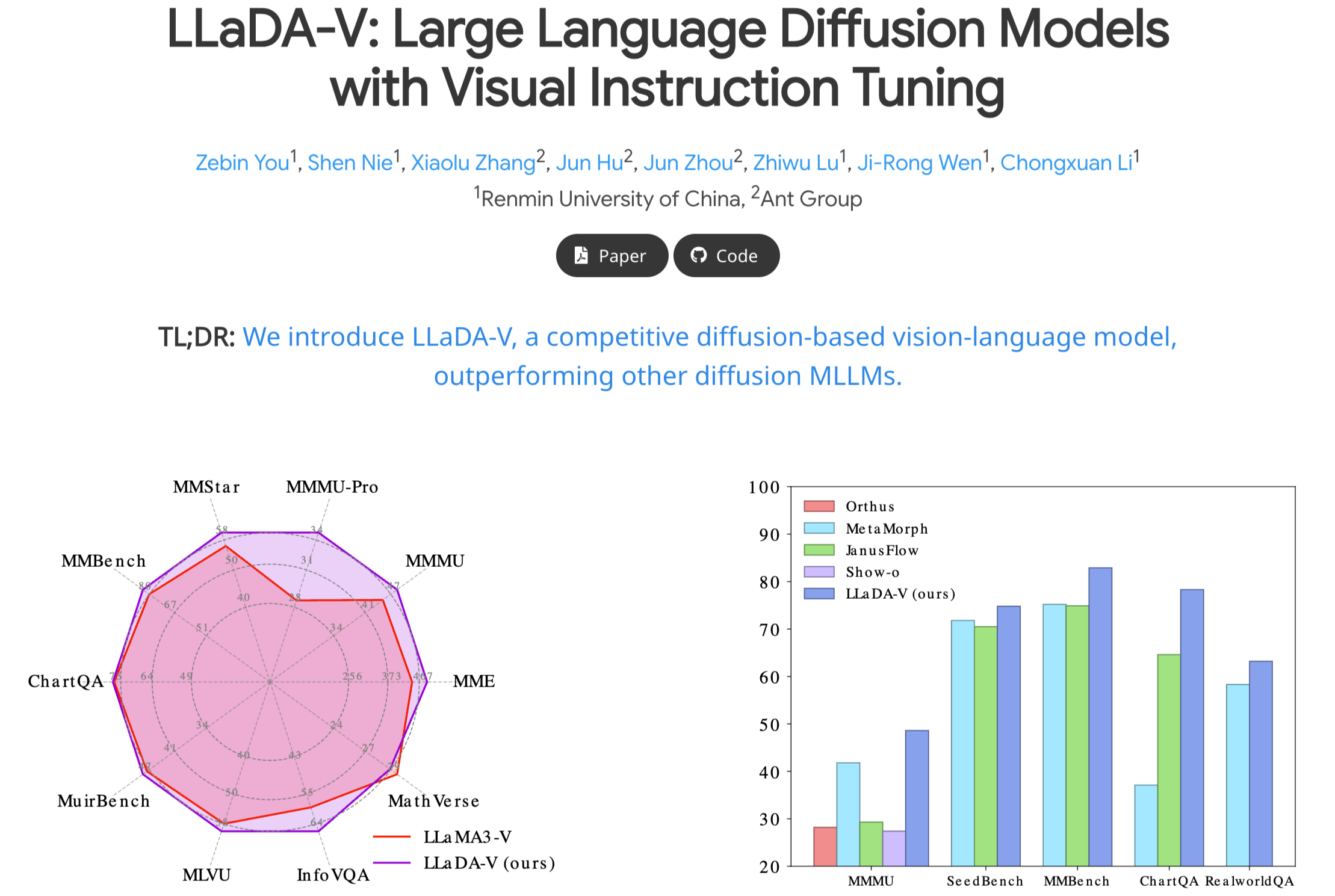
LLaDA-V是中国人民大学高瓴人工智能学院、蚂蚁集团推出的多模态大语言模型(MLLM),基于纯扩散模型架构,专注于视觉指令微调。模型在LLaDA的基础上,引入视觉编码器和MLP连接器,将视觉特征映射到语言嵌入空间,实现有效的多模态对齐。LLaDA-V在多模态理解方面达到最新水平,超越现有的混合自回归-扩散和纯扩散模型。 LLaDA-V的主要功能 图像描述生成:根据输入的图像生成详细的描述
PPT.AI 是AI演示文稿制作工具,能快速将用户输入的主题或上传的文档内容转换为专业的 PPT 演示文稿。具备智能内容生成、自动设计与排版、丰富模板选择、多语言支持等功能,支持15种主要语言,提供50多个专业模板。用户只需输入主题或上传文件,选择模板,可快速生成演示文稿,支持进一步自定义编辑。PPT.AI 考虑数据安全,提供银行级加密和安全云存储。 PPT.AI的主要功能 智能生成演示文
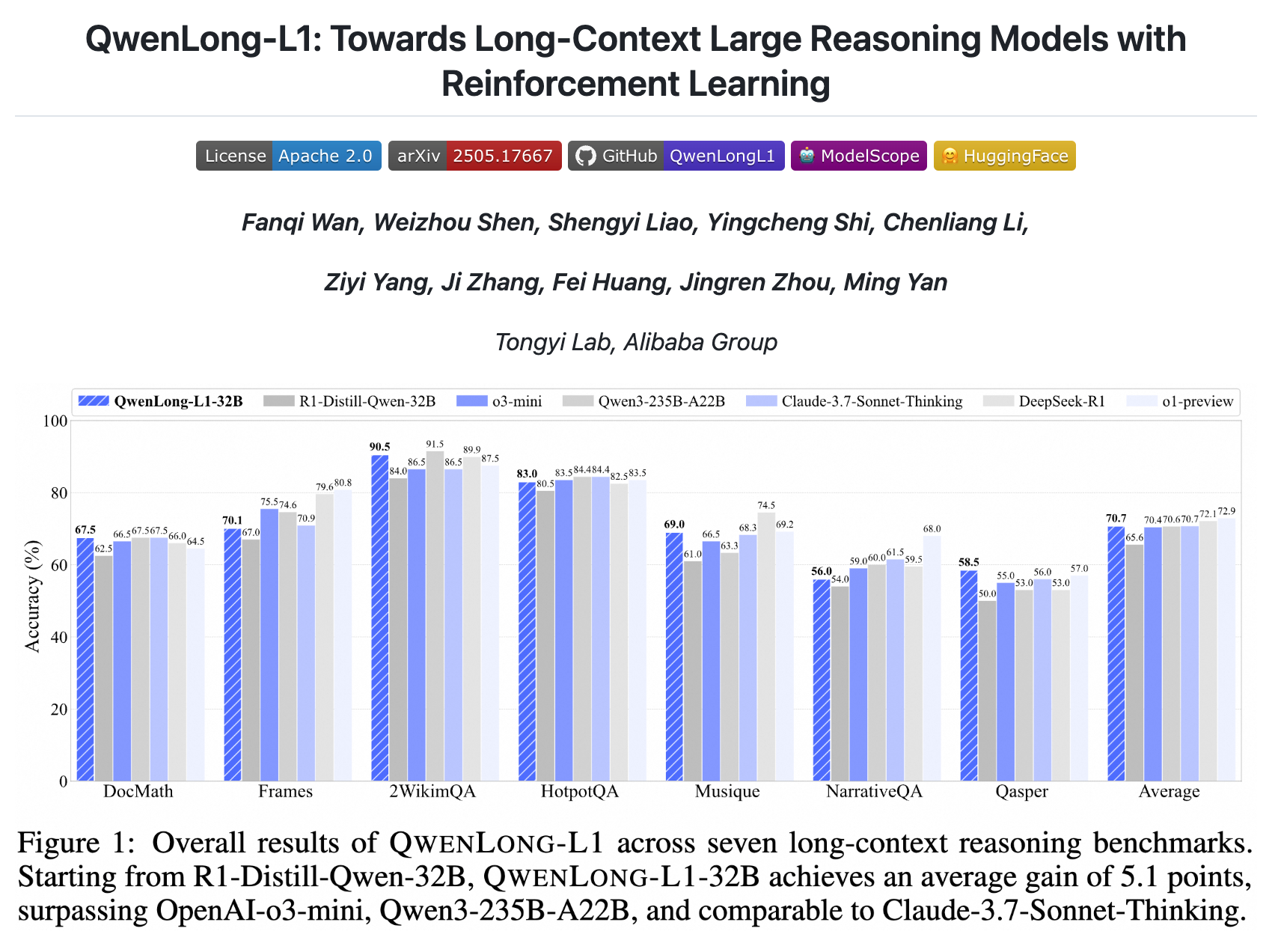
QwenLong-L1-32B 是阿里巴巴集团 Qwen-Doc 团队推出的,基于强化学习训练的首个长文本推理大模型。模型基于渐进式上下文扩展、课程引导的强化学习和难度感知的回顾性采样策略,显著提升在长文本场景下的推理能力。模型在多个长文本文档问答(DocQA)基准测试中表现优异,平均准确率达到了70.7%,超越OpenAI-o3-mini和Qwen3-235B-A22B等现有旗舰模型,且与Cla
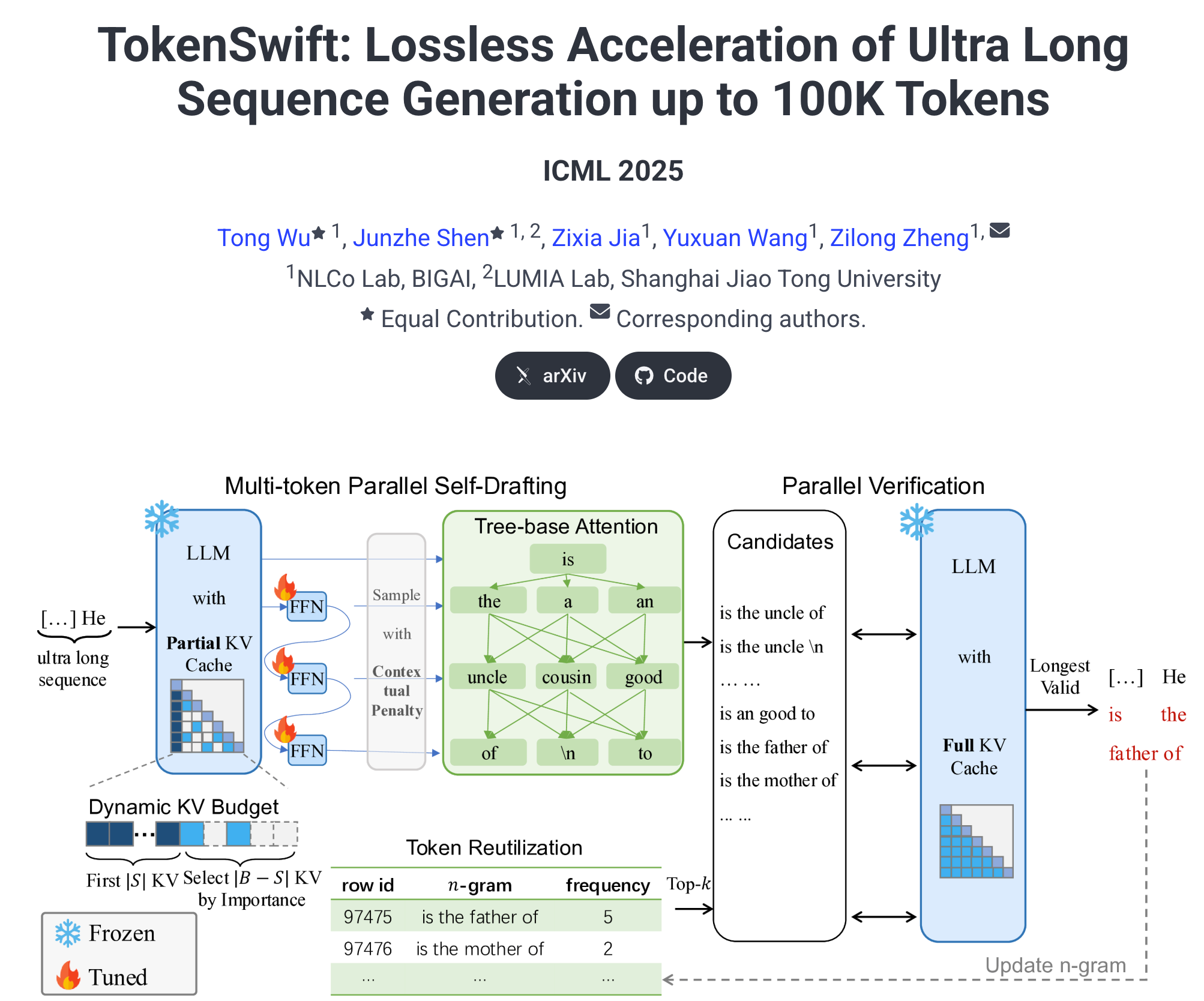
TokenSwift 是北京通用人工智能研究院团队推出的超长文本生成加速框架,能在90分钟内生成10万Token的文本,相比传统自回归模型的近5小时,速度提升了3倍,生成质量无损。TokenSwift 通过多Token生成与Token重用、动态KV缓存更新以及上下文惩罚机制等技术,减少模型加载延迟、优化缓存更新时间并确保生成多样性。支持多种不同规模和架构的模型,如1.5B、7B、8B、14B的MH
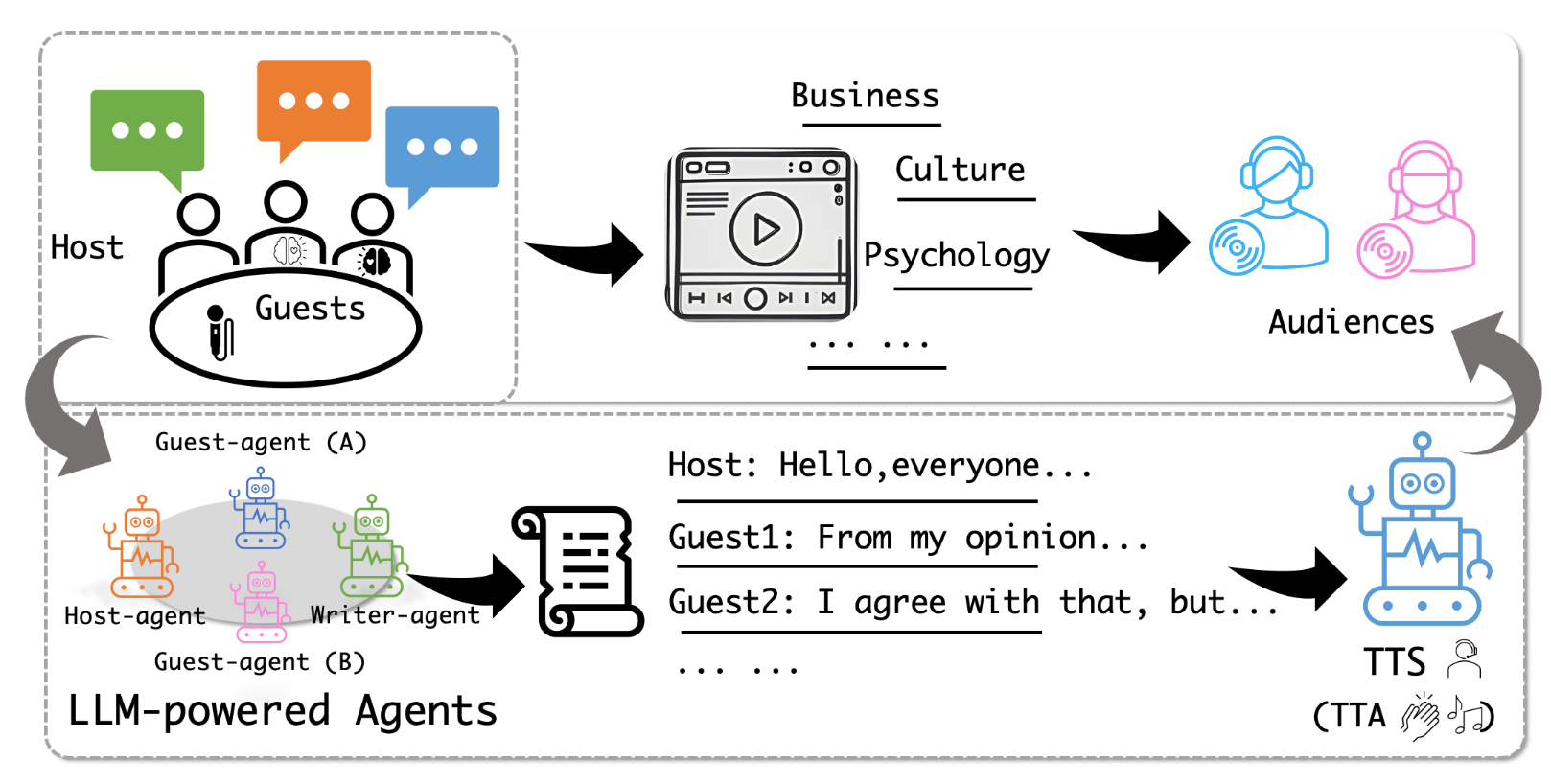
PodAgent 是香港中文大学、微软和小红书联合推出的播客生成框架。基于模拟真实的脱口秀场景,用多智能体协作系统(包括主持人、嘉宾和编剧)自动生成丰富且结构化的对话内容。PodAgent构建了多样化的声音库,用在精准匹配角色与声音,确保音频的自然度和沉浸感。PodAgent 引入基于大语言模型(LLM)的语音合成技术,生成富有表现力和情感的语音,让播客更具吸引力。PodAgent 推出了全面的评
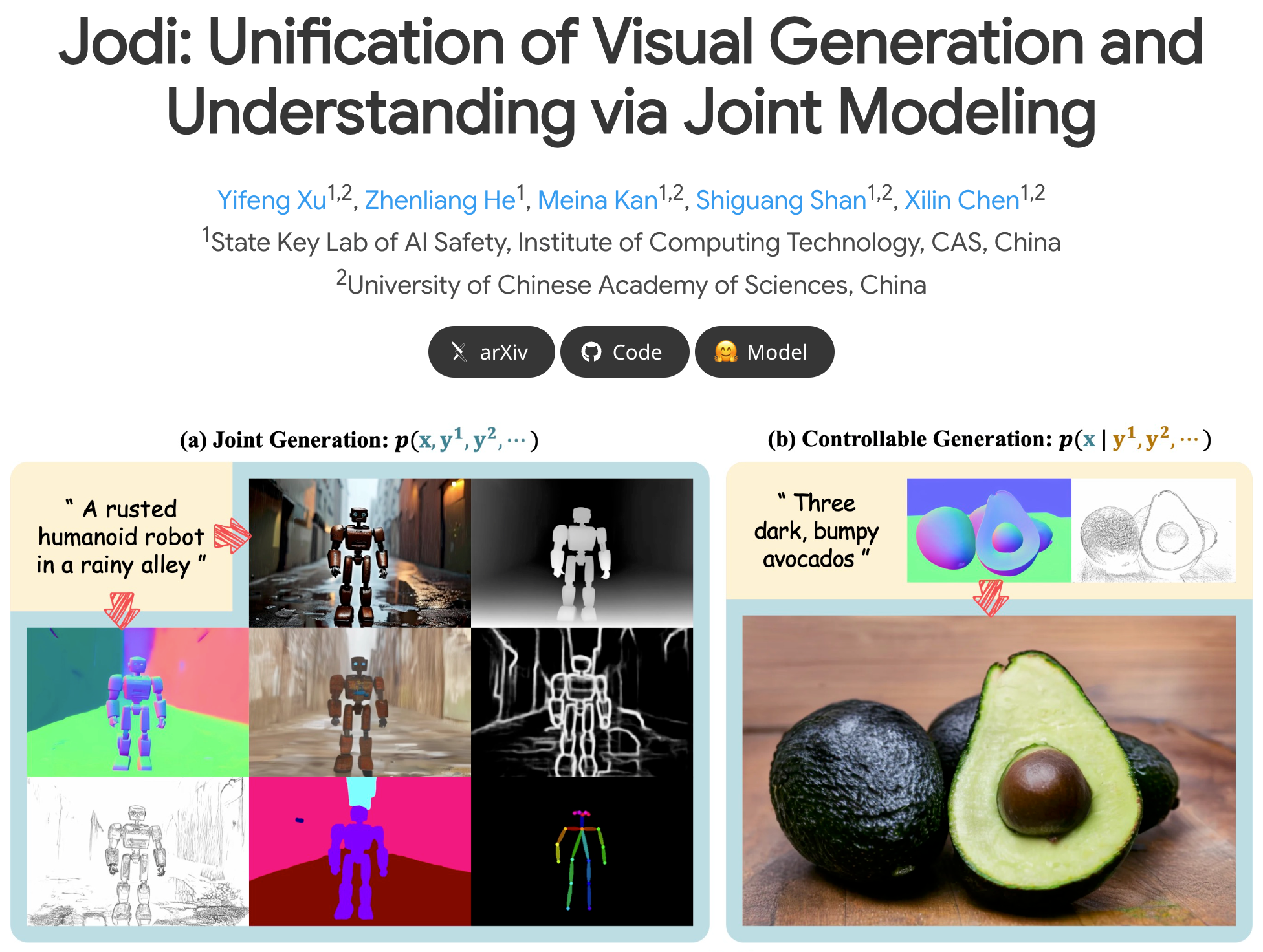
Jodi是中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,将视觉生成与理解统一起来。Jodi基于线性扩散Transformer和角色切换机制,执行联合生成(同时生成图像和多个标签)、可控生成(基于标签组合生成图像)及图像感知(从图像预测多个标签)三种任务。Jodi用包含20万张高质量图像和7个视觉域标签的Joint-1.6M数据集进行训练。Jodi在生成
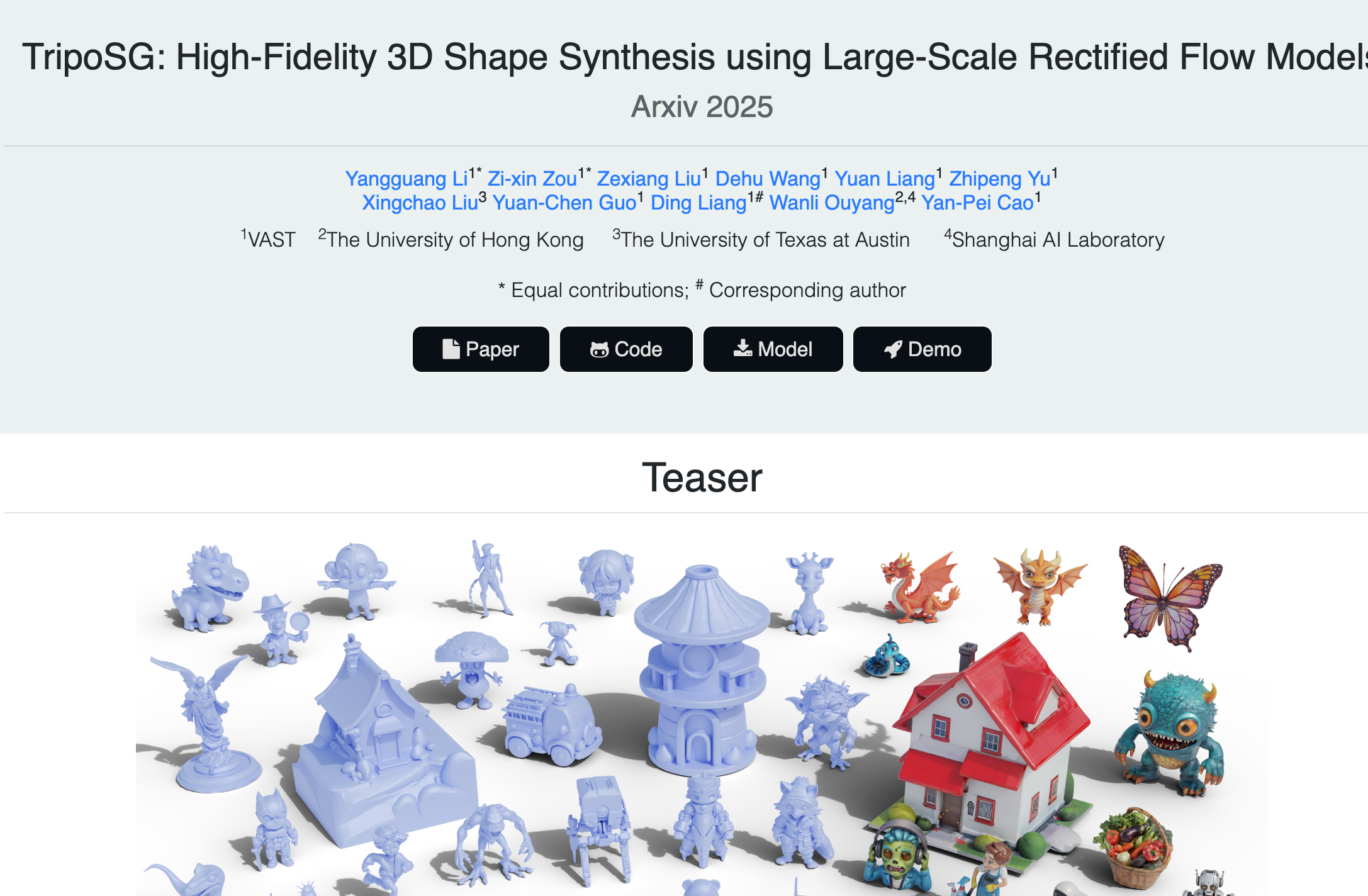
TripoSG 是 VAST-AI-Research 团队推出的基于大规模修正流(Rectified Flow, RF)模型的高保真 3D 形状合成技术, 通过大规模修正流变换器架构、混合监督训练策略以及高质量数据集,实现了从单张输入图像到高保真 3D 网格模型的生成。TripoSG 在多个基准测试中表现出色,生成的 3D 模型具有更高的细节和更好的输入条件对齐。 TripoSG的主要功能
OmniAudio 是阿里巴巴通义实验室语音团队推出的从360°视频生成空间音频(FOA)的技术。为虚拟现实和沉浸式娱乐提供更真实的音频体验。通过构建大规模数据集Sphere360,包含超过10.3万个视频片段,涵盖288种音频事件,总时长288小时,为模型训练提供了丰富资源。OmniAudio 的训练分为两个阶段:自监督的coarse-to-fine流匹配预训练,基于大规模非空间音频资源进行自监
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视
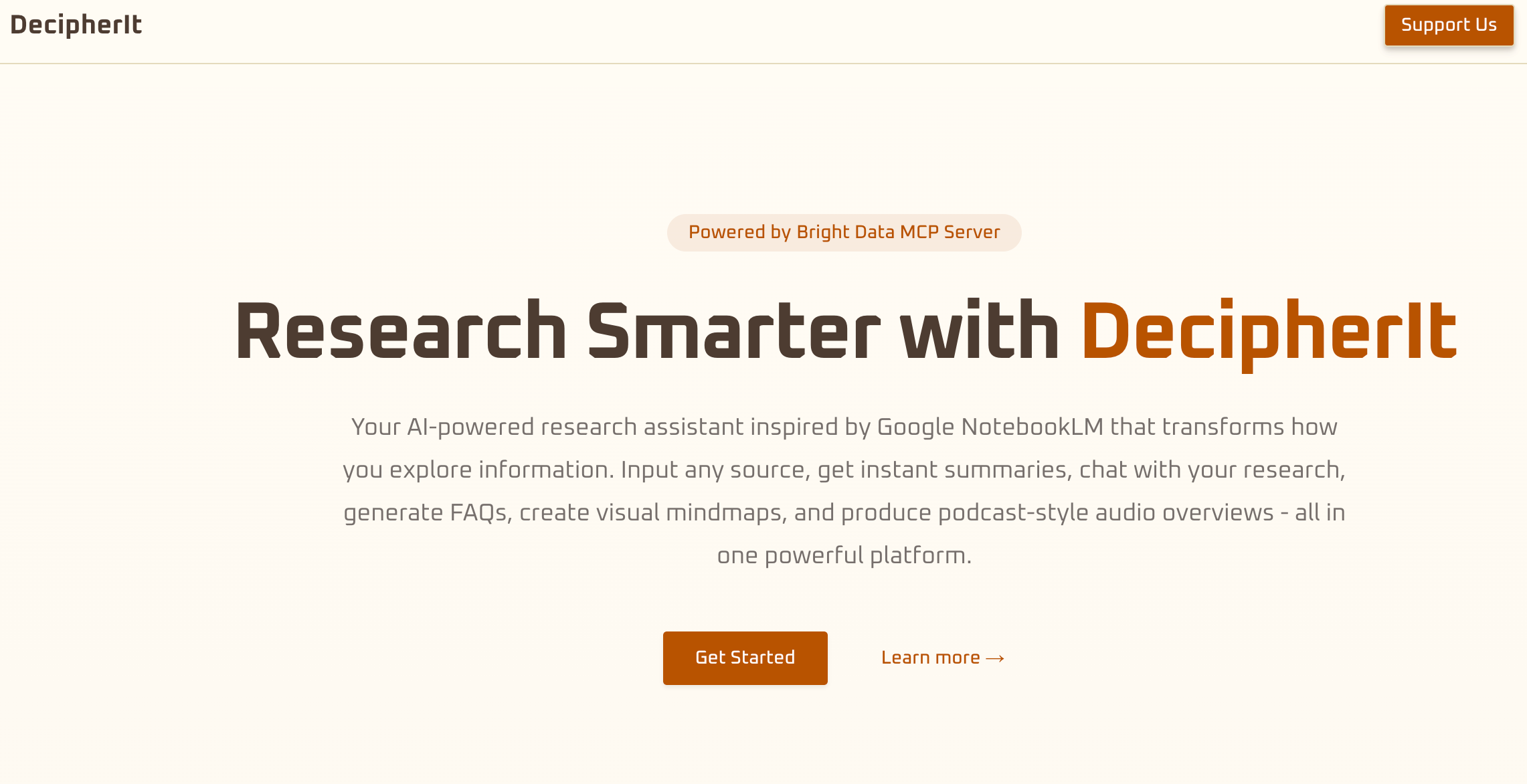
DecipherIt是AI驱动的研究助手工具,基于智能化手段简化和优化研究过程。工具支持将各种主题、链接和文件转化为AI生成的研究笔记本,提供全面的总结、互动问答、音频概述、可视化思维导图及自动化的FAQ生成等功能。基于Bright Data的MCP服务器,DecipherIt突破地理限制和反爬虫检测,获取全球范围内的信息。DecipherIt是多智能体AI框架CrewAI支持高效地分析和整合来自
MoonCast 是零样本播客生成系统,从纯文本源合成自然的播客风格语音。通过长上下文语言模型和大规模语音数据训练,能生成几分钟长的播客音频,支持中文和英文。生成语音的自然性和连贯性,在长音频生成中能保持高质量。MoonCast 使用特定的LLM提示来生成播客脚本,通过语音合成模块将其转换为最终的播客音频。用户可以通过简单的命令和预训练权重快速生成播客。 MoonCast的项目地址 项目官
PandaWiki 是开源的AI知识库搭建系统,基于 AI 大模型的能力,帮助用户快速构建智能化的产品文档、技术文档、FAQ 和博客系统。核心功能包括 AI 辅助创作、AI 问答和 AI 搜索,显著提升知识管理的效率和智能化水平。PandaWiki 提供强大的富文本编辑能力,支持 Markdown 和 HTML 编辑,可导出为 Word、PDF、Markdown 等多种格式。支持与第三方应用集成,
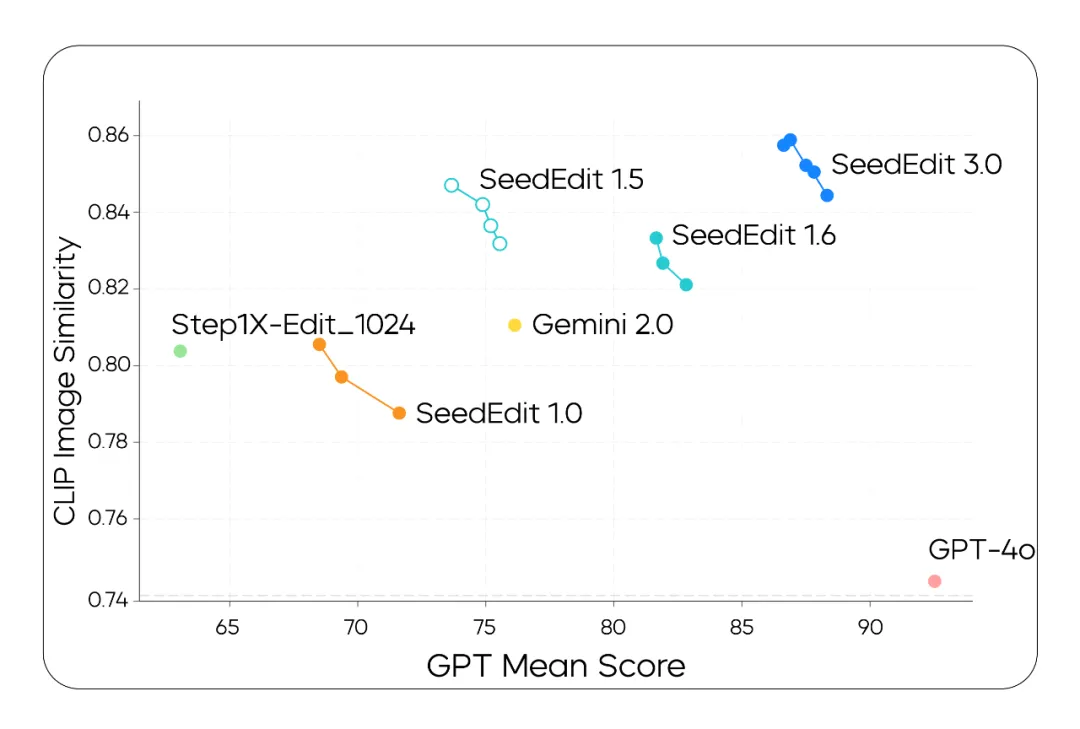
字节跳动 Seed 团队今天正式发布图像编辑模型 SeedEdit 3.0。 该模型可处理并生成 4K 图像,在精细且自然地处理编辑区域的同时,还能高保真地维持其他信息。尤其针对图像编辑“哪里改与哪里不改”的取舍,该模型表现出更佳的理解力和权衡力,可用率相应提高。 依靠 AI 完成指令式图像编辑的需求,广泛存在于视觉内容创意工作中。但此前,图像编辑模型在主体&背景保持、指令遵循等方面能
只显示前20页数据,更多请搜索
Showing 433 to 456 of 498 results