关键词 "paper sharing" 的搜索结果, 共 20 条, 只显示前 480 条
A MCP Server for paperscraper:Tools to scrape publication metadata from pubmed, arxiv, medrxiv, biorxiv and chemrxiv.
A MCP Server for Google Scholar: 🔍 Enable AI assistants to search and access Google Scholar papers through a simple MCP interface.
A Model Context Protocol server for searching academic papers on arXiv.
A Python MCP Server for Paper Analytical Devices (PAD)
A Model Content Protocol server that provides tools to search and retrieve academic papers from PubMed database.
MCP server for searching and querying PubMed medical papers/research database
MCP server for Semantic Scholar to search for papers
A FastMCP server implementation for the Semantic Scholar API, providing comprehensive access to academic paper data, author information, and citation networks.
Tool to work with arXiv, provide LLM with ability to search and read papers from there
A Model Context Protocol server for searching and analyzing arXiv papers
Supporting multiple themes, automatic long text splitting, one-click image export, making your content creation easier and more efficient. Completely free, start using now! MD2Card is a simple and ea
Sharing the latest developments in the world of artificial intelligence. 每天3分钟学习最新的AI前沿信息
RWKV开源发布了 RWKV7-G1 1.5B 推理模型(Reasoning Model)。模型基于 World v3.5 数据集训练,包含更多小说、网页、数学、代码和 reasoning 数据,总数据为 5.16T tokens。其具备其它同尺寸模型不具备的推理能力和任务能力,同时还支持现实世界 100+ 种语言。 在实际测试中,RWKV7-G1 1.5B 模型的推理逻辑性较强,能够完成有难度的
Lovart 全球首个设计 Agent 体验 Lovart 的三个特点: 一、全链路设计和执行,一句话搞定 以前的文生图工具,它们所提供的任务是“生成图片”这一环。 而设计 Agent,则像一位“设计执行官”,覆盖从创意拆解到专业交付的整个视觉流程。 从意图拆解 → 任务链 → 最后成品,一句话全搞定。 单次可以执行上
Vid2World是清华大学联合重庆大学推出的创新框架,支持将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。模型基于视频扩散因果化和因果动作引导两大核心技术,解决传统VDM在因果生成和动作条件化方面的不足。Vid2World在机器人操作和游戏模拟等复杂环境中表现出色,支持生成高保真、动态一致的视频序列,支持基于动作的交互式预测。Vid2World为提升世界模
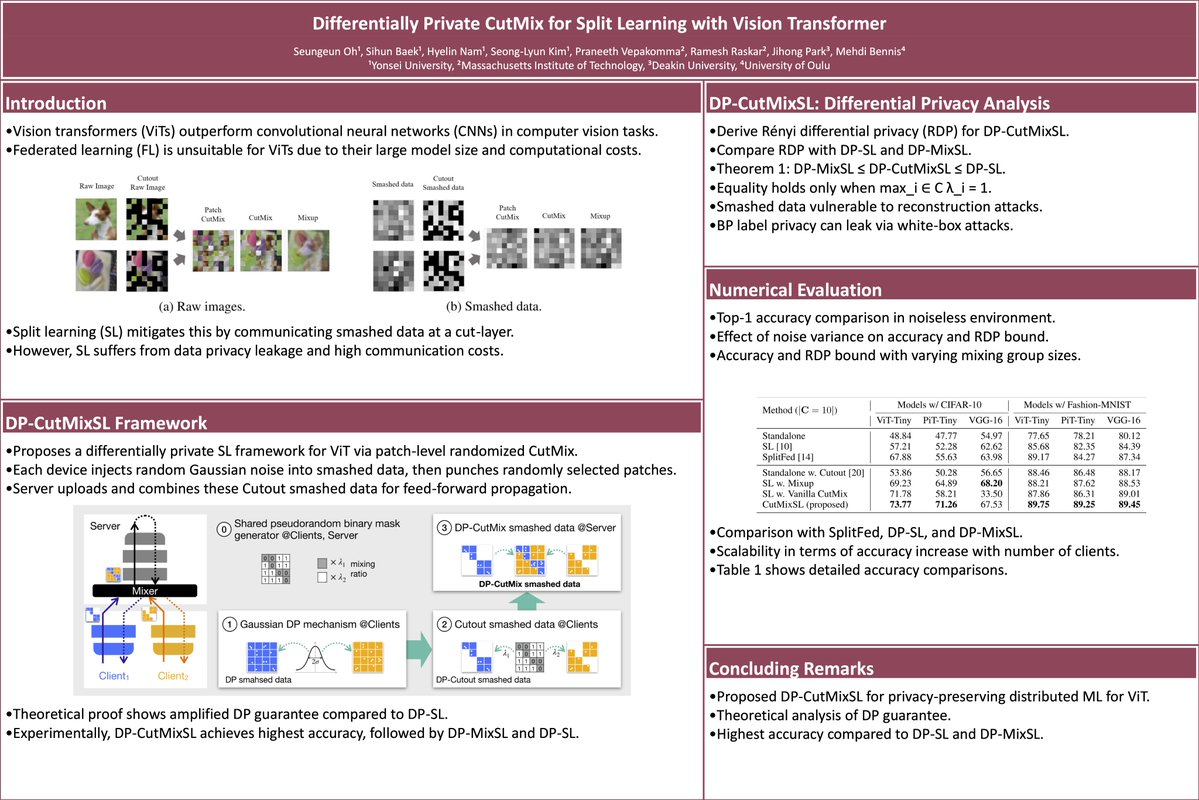
一款论文转多模态海报工具:Paper2Poster,给它一篇论文,可自动生成一张学术海报,生成质量高制作成本低 生成的海报可读性较好,结构清晰、用词精简,比GPT-4清晰可读,比PPTAgent布局合理 输入论文PDF全自动处理,可以自动提取重点,进行智能排版设计,自动调整布局,维持论文逻辑顺序并控制信息密度
AlphaGenome是谷歌DeepMind推出的全新AI模型,能更深入地理解基因组。模型能接收长达100万个碱基对的DNA序列输入,预测数千种表征其调控活性的分子特性,评估基因变异的影响。模型基于卷积层、Transformer架构,训练数据来自大型公共数据库。模型具有长序列上下文与高分辨率、全面多模态预测、高效变异评分和新颖剪接点建模等优势,在多项基准测试中表现顶尖,基于API向非商业研究领域开
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设
只显示前20页数据,更多请搜索
Showing 433 to 452 of 452 results