关键词 "19 languages" 的搜索结果, 共 12 条, 只显示前 480 条
类似 Manus 但基于 Deepseek R1 Agents 的本地模型。 Manus AI 的本地替代品,它是一个具有语音功能的大语言模型秘书,可以 Coding、访问你的电脑文件、浏览网页,并自动修正错误与反省,最重要的是不会向云端传送任何资料。采用 DeepSeek R1 等推理模型构建,完全在本地硬体上运行,进而保证资料的隐私。 Features: 100% 本机运行:
Prezi是创新的AI演示文稿工具,基于开放式画布和动态演示方式,帮助用户创建引人入胜的演示文稿和视频。与传统线性幻灯片不同,Prezi支持自由组织内容,提供丰富的模板和资源库,包括图片、GIF和图标等。Prezi AI技术辅助用户快速生成演示内容,提升创意效率。Prezi广泛应用于商业和教育领域,深受全球用户喜爱。 Prezi的主要功能 开放式画布:提供无边界的画布,让用户自由地组织
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。Dolphin在多种文档解析任务上表现出色,性能超越GPT-4.1、Mistral-OCR等模型。Dolphin 具有322M参数,体积小、速度快,支持多种文档元素解析,包括文本、表格、公式等。Dolphin的代码和预训练模型已公开,
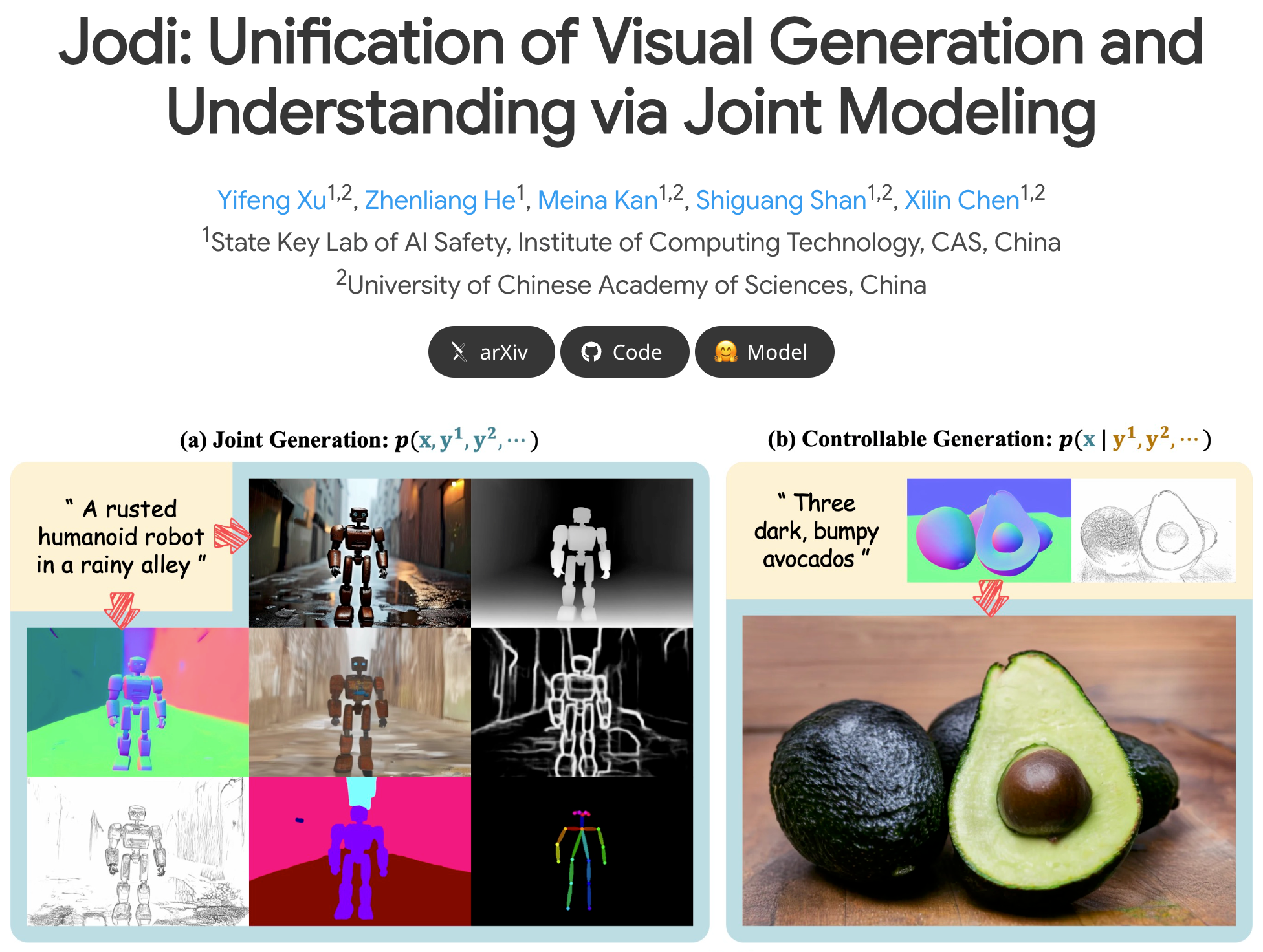
Jodi是中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,将视觉生成与理解统一起来。Jodi基于线性扩散Transformer和角色切换机制,执行联合生成(同时生成图像和多个标签)、可控生成(基于标签组合生成图像)及图像感知(从图像预测多个标签)三种任务。Jodi用包含20万张高质量图像和7个视觉域标签的Joint-1.6M数据集进行训练。Jodi在生成
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视
OCode 是终端原生 AI 编程助手,为开发者提供深度代码库智能和自动任务执行功能。与本地 Ollama 模型无缝集成,将企业级 AI 辅助直接融入开发流程中。终端原生工作流,能直接在你的 shell 环境中运行;深度代码库智能,可自动映射并理解整个项目;自动任务执行,能端到端处理多步骤开发任务;可扩展的插件层,通过模型上下文协议(MCP)启用第三方集成,帮助开发者提高编程效率和质量。 OCo
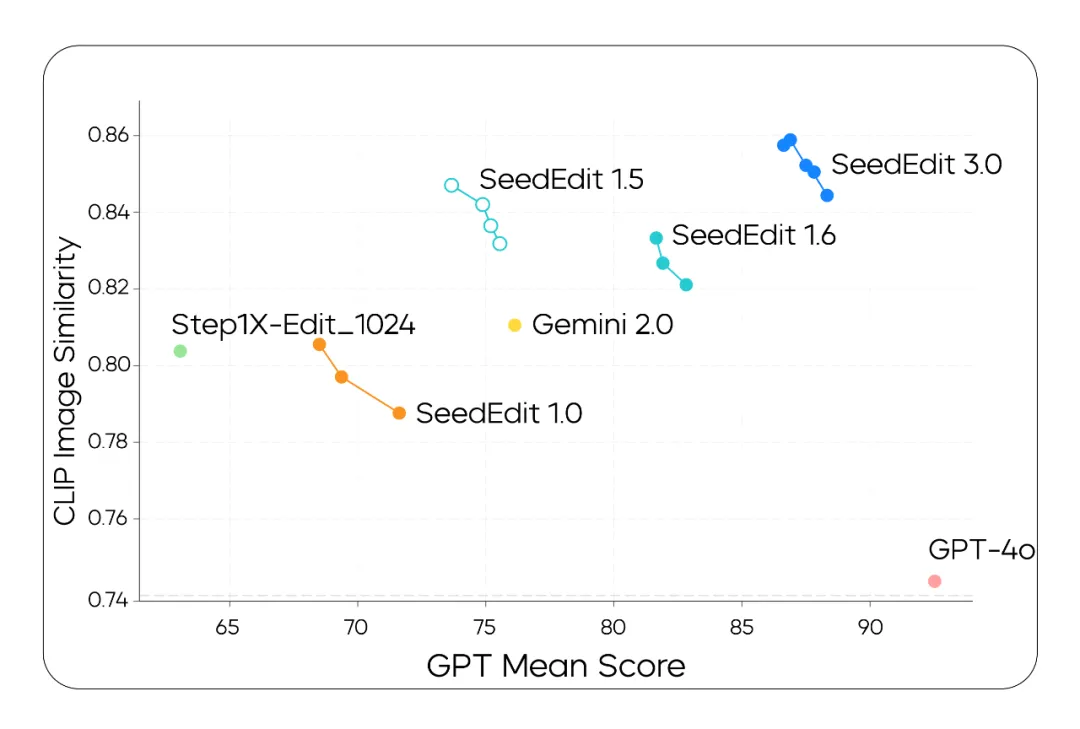
字节跳动 Seed 团队今天正式发布图像编辑模型 SeedEdit 3.0。 该模型可处理并生成 4K 图像,在精细且自然地处理编辑区域的同时,还能高保真地维持其他信息。尤其针对图像编辑“哪里改与哪里不改”的取舍,该模型表现出更佳的理解力和权衡力,可用率相应提高。 依靠 AI 完成指令式图像编辑的需求,广泛存在于视觉内容创意工作中。但此前,图像编辑模型在主体&背景保持、指令遵循等方面能
DeepPiano 是智曲科技推出的以大模型为内核的钢琴智能应用。通过先进的人工智能技术,为钢琴演奏者和学习者提供多种便捷功能。DeepPiano 能实现智能乐谱翻页,自动识别演奏进度,无需手动操作,让演奏更加流畅。“AI 音频美颜”功能可快速优化录制的钢琴音频,去除噪音提升音质,达到专业水准。具备 AI 音乐创作能力,可根据用户即兴演奏生成五线谱,激发创作灵感。 DeepPiano的官网地址
Experience revolutionary language learning through real-time conversation practice, instant grammar correction, pronunciation training, and personalized vocabulary building in 30+ languages.
AudioGenie是腾讯AI Lab团队推出的多模态音频生成工具,能从视频、文本、图像等多种模态输入生成音效、语音、音乐等多种音频输出。工具采用无训练的多智能体框架,通过生成团队和监督团队的双层架构实现高效协同。生成团队负责将复杂的输入分解为具体的音频子事件,通过自适应混合专家(MoE)协作机制动态选择最适合的模型进行生成。监督团队则负责时空一致性验证,通过反馈循环进行自我纠错,确保生成的音频高
OmniHuman-1.5 字节推出的先进的AI模型,能从单张图片和语音轨道生成富有表现力的数字人动画。模型基于双重系统认知理论,融合多模态大语言模型和扩散变换器,模拟人类的深思熟虑和直觉反应。模型能生成动态的多角色动画,支持通过文本提示进行细化,实现更精准的动画效果。OmniHuman-1.5 的动画具有复杂的角色互动和丰富的情感表现,为动画制作和数字内容创作带来全新的可能性,大大提升创作效率和
AIVoiceGen is a user-friendly AI voice generation platform focused on text-to-speech. It offers free access with no registration required, featuring diverse voices across languages, accents, and tones
只显示前20页数据,更多请搜索
Showing 217 to 228 of 228 results